Key Takeaways
- Gemini 3.5 Flash costs 5.5x more to run than its predecessor in benchmark testing
- Token prices tripled: $1.50/$9.00 per million tokens, up from $0.50/$3.00
- High token consumption on agent tasks pushes total costs 75% above Gemini 3.1 Pro
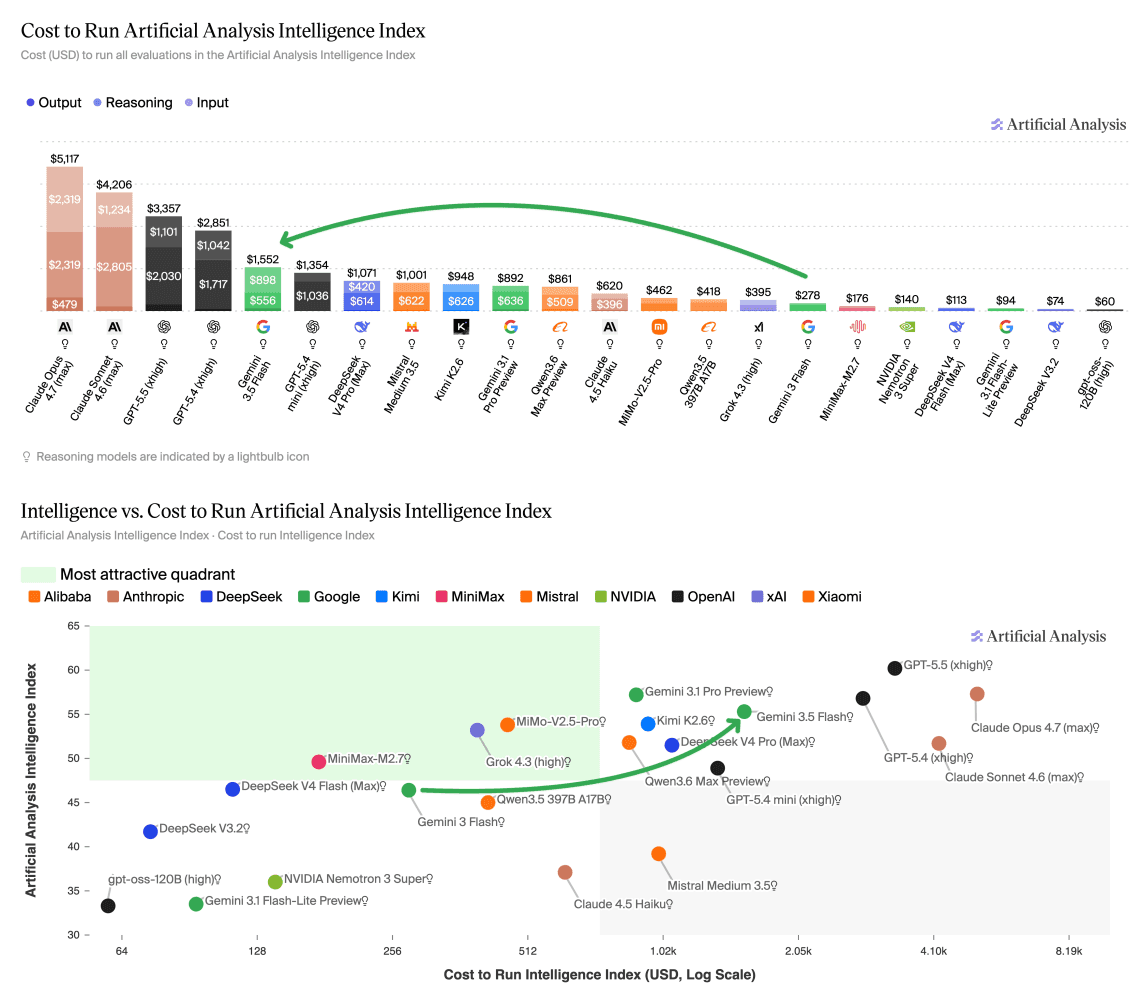
Google DeepMind has released Gemini 3.5 Flash, and the price tag is raising eyebrows. The new model costs 5.5 times more to run than Gemini 3 Flash in benchmark testing, according to an analysis by Artificial Analysis. That makes it nearly twice as expensive as the Pro model Gemini 3.1.
The sticker shock gets worse when you look at agent-based tasks. Gemini 3.5 Flash burns through so many tokens that total costs end up 75 percent higher than Gemini 3.1 Pro, the model it was supposed to undercut.
Token Prices Triple Across the Board
Google now charges $1.50 per million input tokens and $9.00 per million output tokens for Gemini 3.5 Flash. That's up from $0.50 and $3.00 for Gemini 3 Flash. A straight tripling.
On paper, that's still cheaper per token than Gemini 3.1 Pro at $2.00 and $12.00. But the math flips in practice. Gemini 3.5 Flash consumes far more tokens to complete agent-based tasks, wiping out the per-token savings.

The context window stays at one million tokens. So developers get the same input capacity but pay more for what comes out.
Google Joins an Industry-Wide Price Hike
Google isn't alone in making newer models pricier. Anthropic's Opus 4.7 had a hidden price increase of roughly 30 to 40 percent over its predecessor due to higher token consumption. OpenAI's GPT 5.5 jumped 50 to 90 percent over GPT 5.4. In OpenAI's case, token consumption went down but base prices went up. Google raised both.
For developers and companies, this means raw token price is becoming a less useful metric on its own. What matters now is efficiency: how many tokens a model actually needs to finish a job. A cheaper per-token rate means nothing if the model uses three times as many tokens.
Performance Gains Come With a Catch
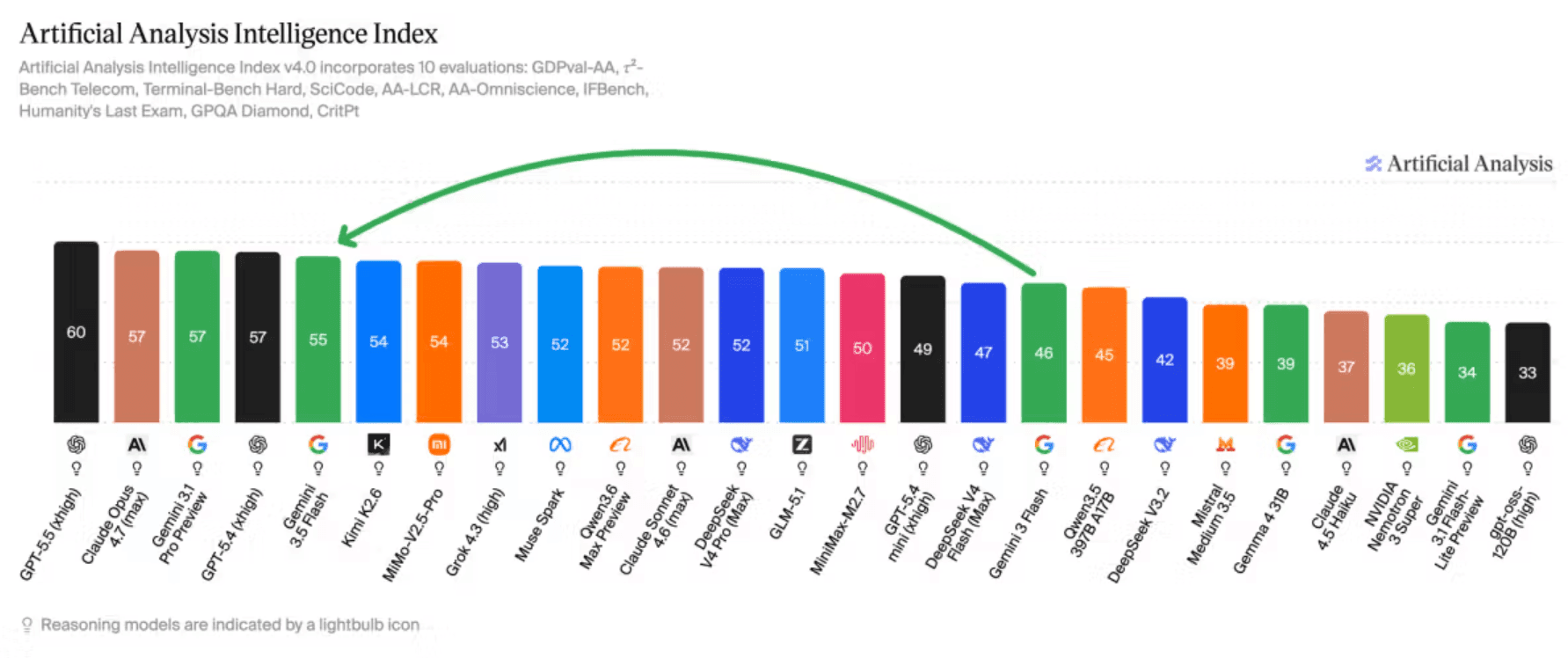
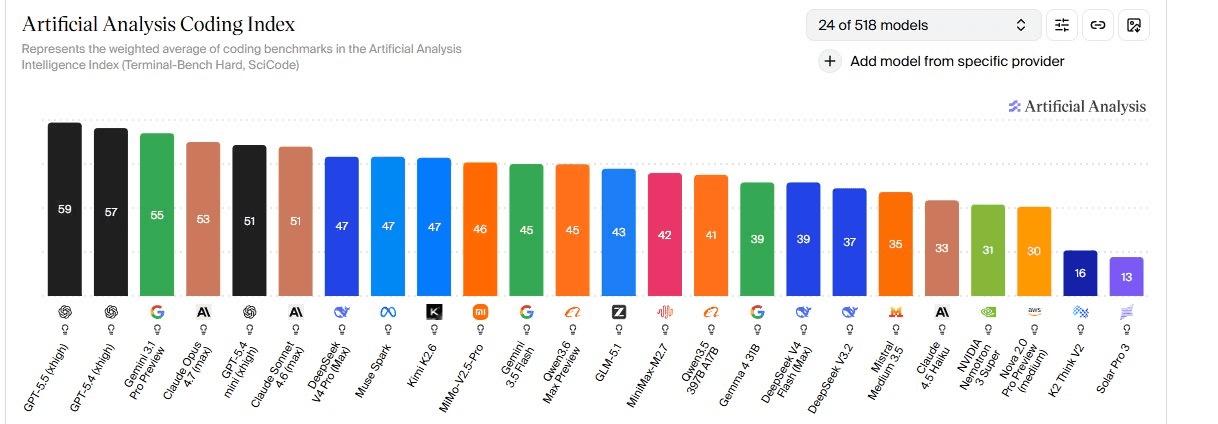
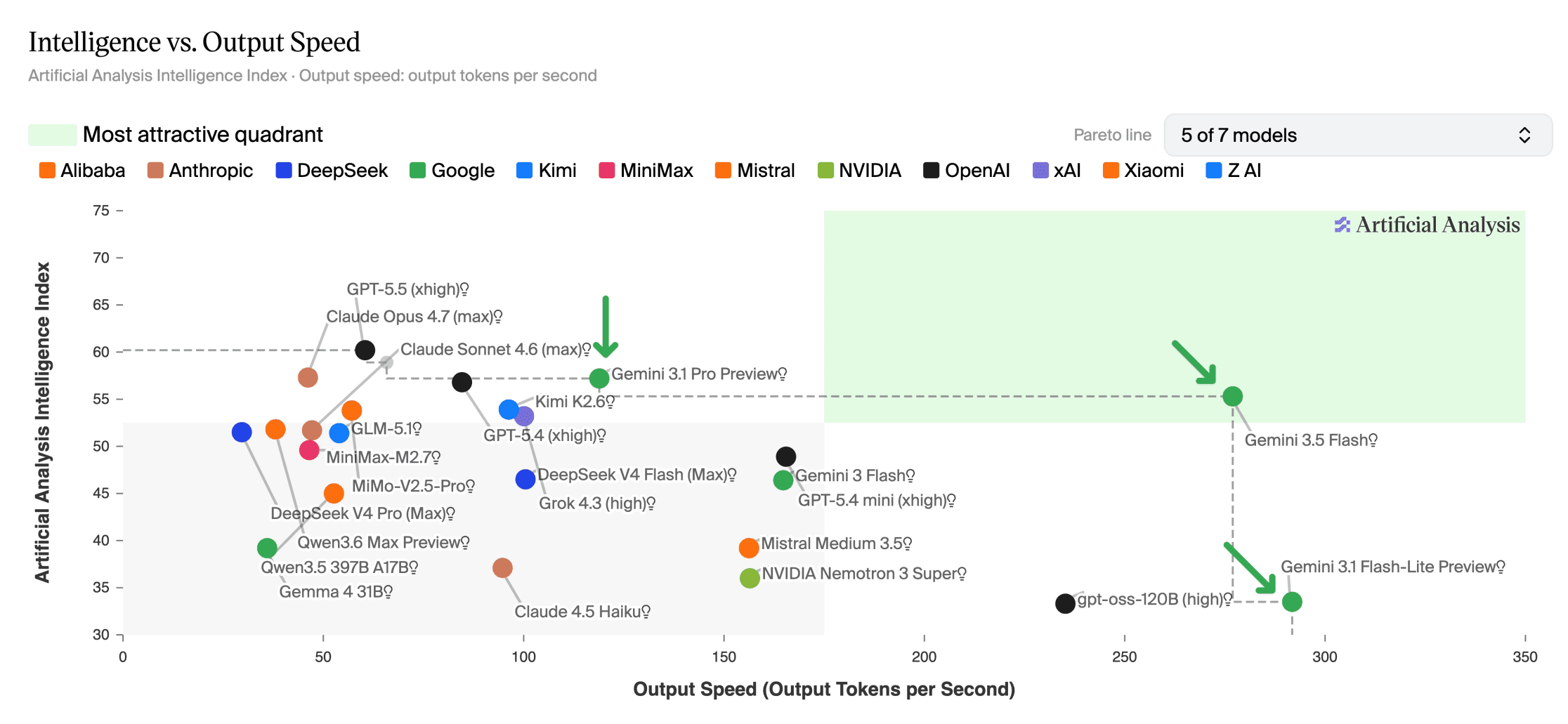
Gemini 3.5 Flash does deliver meaningful improvements. It scores 55 on the Artificial Analysis Intelligence Index, nine points above Gemini 3 Flash. That puts it ahead of Grok 4.3 (53) and Claude Sonnet 4.6 (52).
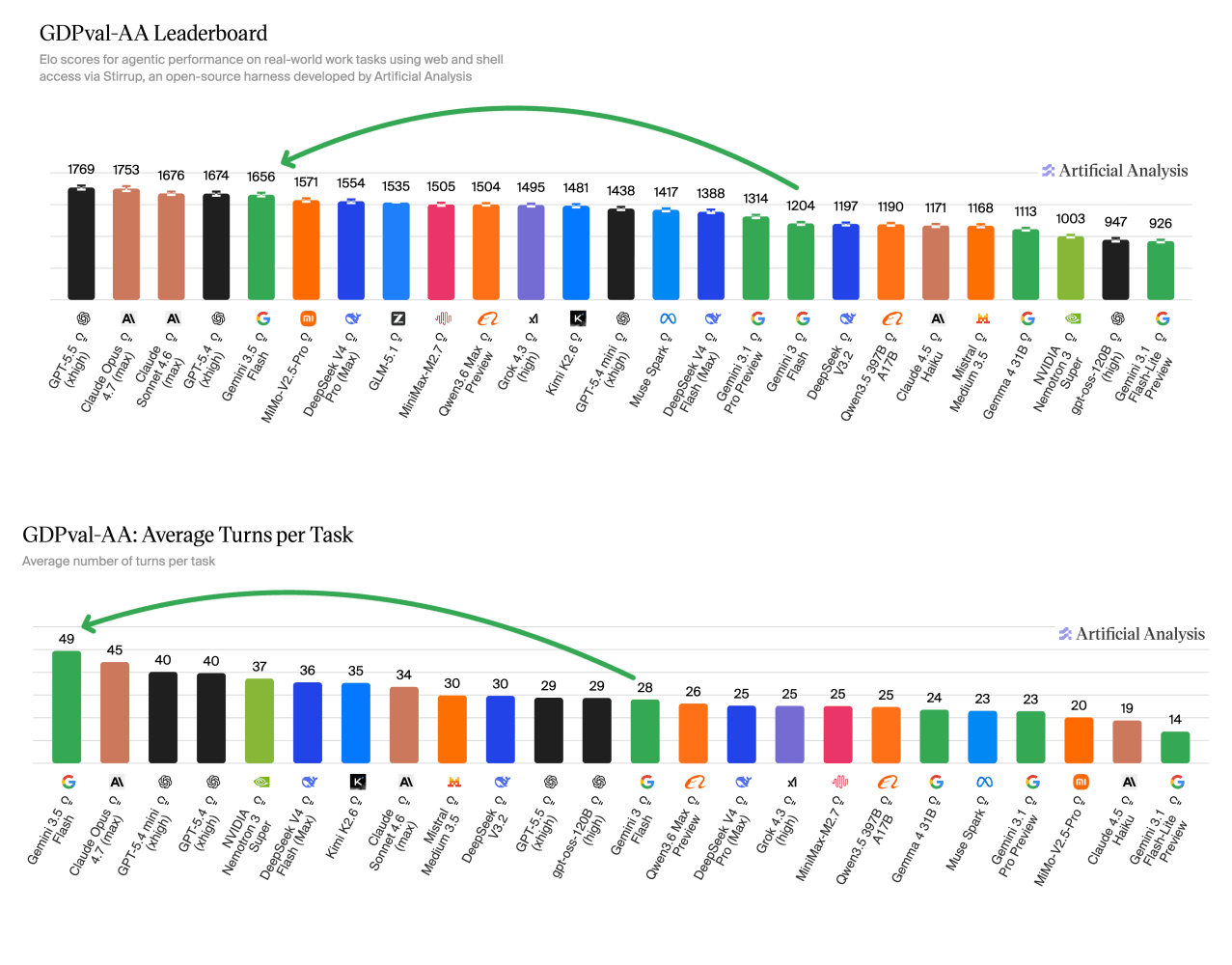
The model pushes out more than 280 output tokens per second, making it the fastest in its intelligence class. Gains show up across nearly every category tested, with the strongest improvements in agentic and multimodal tasks.

But there's a notable weakness. In programming tasks, Gemini 3.5 Flash falls clearly behind competitors like GPT-5.5 and Claude Opus 4.7. For teams building coding assistants or developer tools, this could be a deal-breaker.
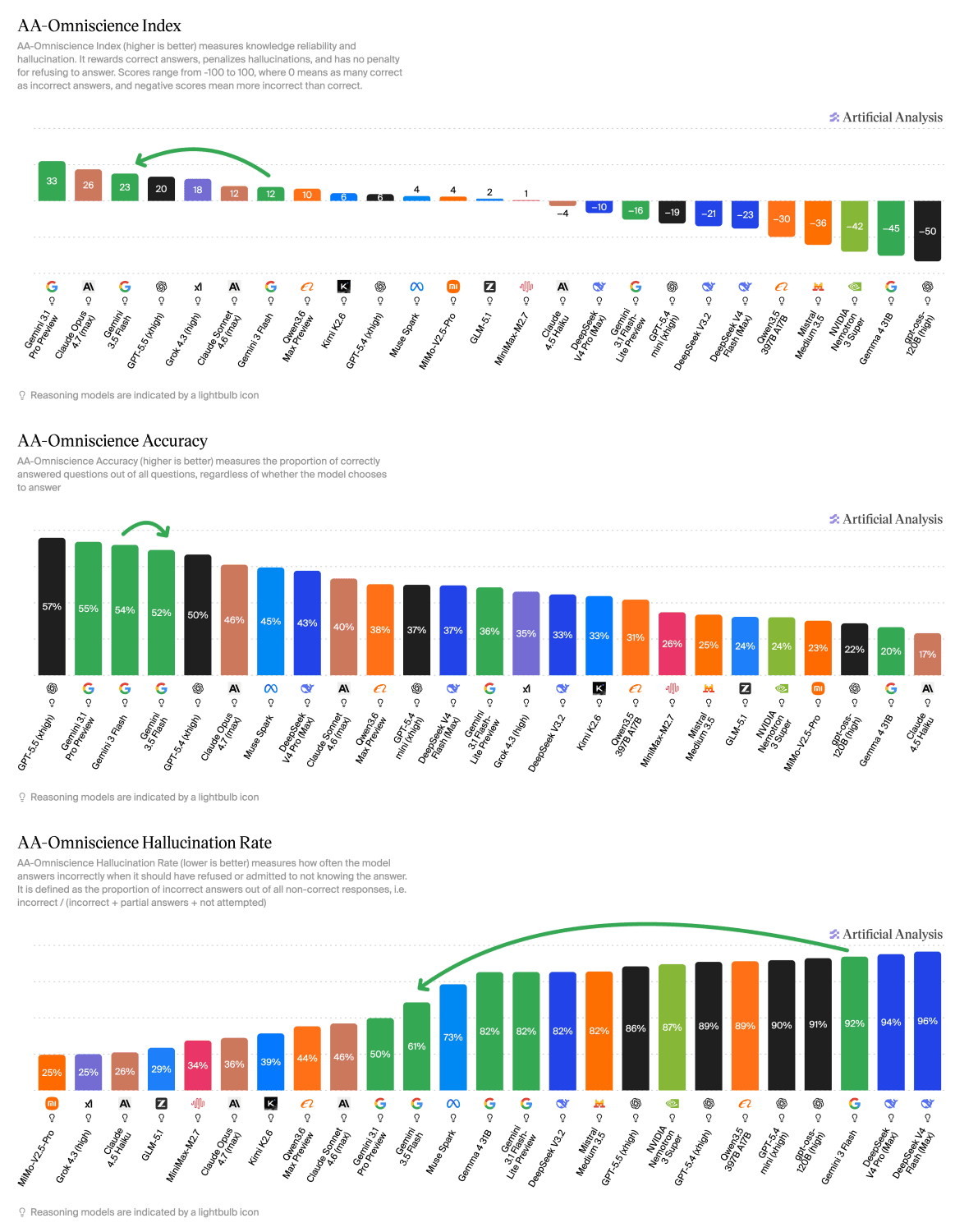
Hallucinations Remain a Problem
Despite the intelligence gains, Gemini 3.5 Flash still struggles with hallucinations. The model shows improvement in knowledge accuracy, but factual reliability remains an issue that developers will need to account for in production systems.
What This Means for Your AI Budget
How much the price hike stings depends on your application. Simple query-response use cases might absorb the increase without much pain. But agent-based workflows, the kind that loop through multiple reasoning steps, will see costs balloon.
The Flash line was long positioned as the cheaper, faster alternative to Google's Pro models. That value proposition is now murkier. Teams will need to benchmark their specific use cases rather than relying on published per-token rates.
More on Google's Gemini AI strategy
Logicity's Take
Frequently Asked Questions
How much more expensive is Gemini 3.5 Flash than Gemini 3 Flash?
Gemini 3.5 Flash costs 5.5 times more to run in benchmark testing. Token prices tripled from $0.50/$3.00 to $1.50/$9.00 per million input/output tokens.
Is Gemini 3.5 Flash cheaper than Gemini Pro?
Per token, yes. But in practice, Gemini 3.5 Flash uses so many more tokens on agent tasks that total costs end up 75% higher than Gemini 3.1 Pro.
What is Gemini 3.5 Flash best at?
Agentic and multimodal tasks. It scores 55 on the Artificial Analysis Intelligence Index and outputs 280+ tokens per second. However, it lags behind competitors in programming tasks.
Are other AI companies raising prices too?
Yes. Anthropic's Opus 4.7 increased costs 30-40% through higher token consumption. OpenAI's GPT 5.5 jumped 50-90% over GPT 5.4 through higher base prices.
What is the context window for Gemini 3.5 Flash?
One million tokens, unchanged from the previous version.
Need Help Implementing This?
Source: The Decoder / Matthias Bastian
Google I/O 2026: Gemini Omni, Spark Assistant, and XR Hardware
The new article introduces several major announcements from Google I/O 2026 not mentioned in the first piece, including the 'Gemini Omni' model and the 'Spark' agentic personal assistant. It also covers broader developments such as the AI integration in Google Search and the debut of Android XR glasses.
Manaal Khan
Tech & Innovation Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






