
Key Takeaways

- GPT-5.5 scores 82.7% on Terminal-Bench 2.0, beating Claude Opus 4.7 (69.4%) and Gemini 3.1 Pro (68.5%)
- API access will cost twice as much as GPT-5.4
- A Pro variant pushes FrontierMath scores to 39.6%, up from 35.4% in the standard model
OpenAI has released GPT-5.5, its latest large language model built for autonomous task completion. The company calls it a "new class of intelligence for real work and powering agents." Translation: the model can write code, search the web, analyze data, and operate software without constant human guidance.
The catch? API access will cost double what developers paid for GPT-5.4.
GPT-5.5 is available now for paying ChatGPT and Codex users on Plus, Pro, Business, and Enterprise plans. API access is coming soon.
What Makes GPT-5.5 Different
The core pitch is agentic workflows. GPT-5.5 is designed to understand complex goals, use multiple tools, check its own output, and work through tasks until completion. It switches between tools on its own rather than waiting for user prompts at each step.
OpenAI highlights four areas where the model shows the biggest improvements: agentic coding, computer use, knowledge work, and early scientific research. These tasks require reasoning across contexts and the ability to carry out actions over extended periods.
- Writing and debugging code
- Web research
- Data analysis
- Creating documents and spreadsheets
- Operating software autonomously
Benchmark Results: GPT-5.5 vs Claude vs Gemini
On Terminal-Bench 2.0, a coding benchmark for agentic workflows, GPT-5.5 scores 82.7%. That's 7.6 percentage points above GPT-5.4's 75.1%. Anthropic's Claude Opus 4.7 hits 69.4%, and Google's Gemini 3.1 Pro lands at 68.5%.
The gap widens on harder math problems. On FrontierMath Tier 4, GPT-5.5 scores 35.4%. Claude Opus 4.7 reaches 22.9%, and Gemini 3.1 Pro gets 16.7%. The Pro variant, GPT-5.5 Pro, pushes that number to 39.6%.
| Benchmark | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | 69.4% | 68.5% |
| Expert-SWE (Internal) | 73.1% | 68.5% | - | - |
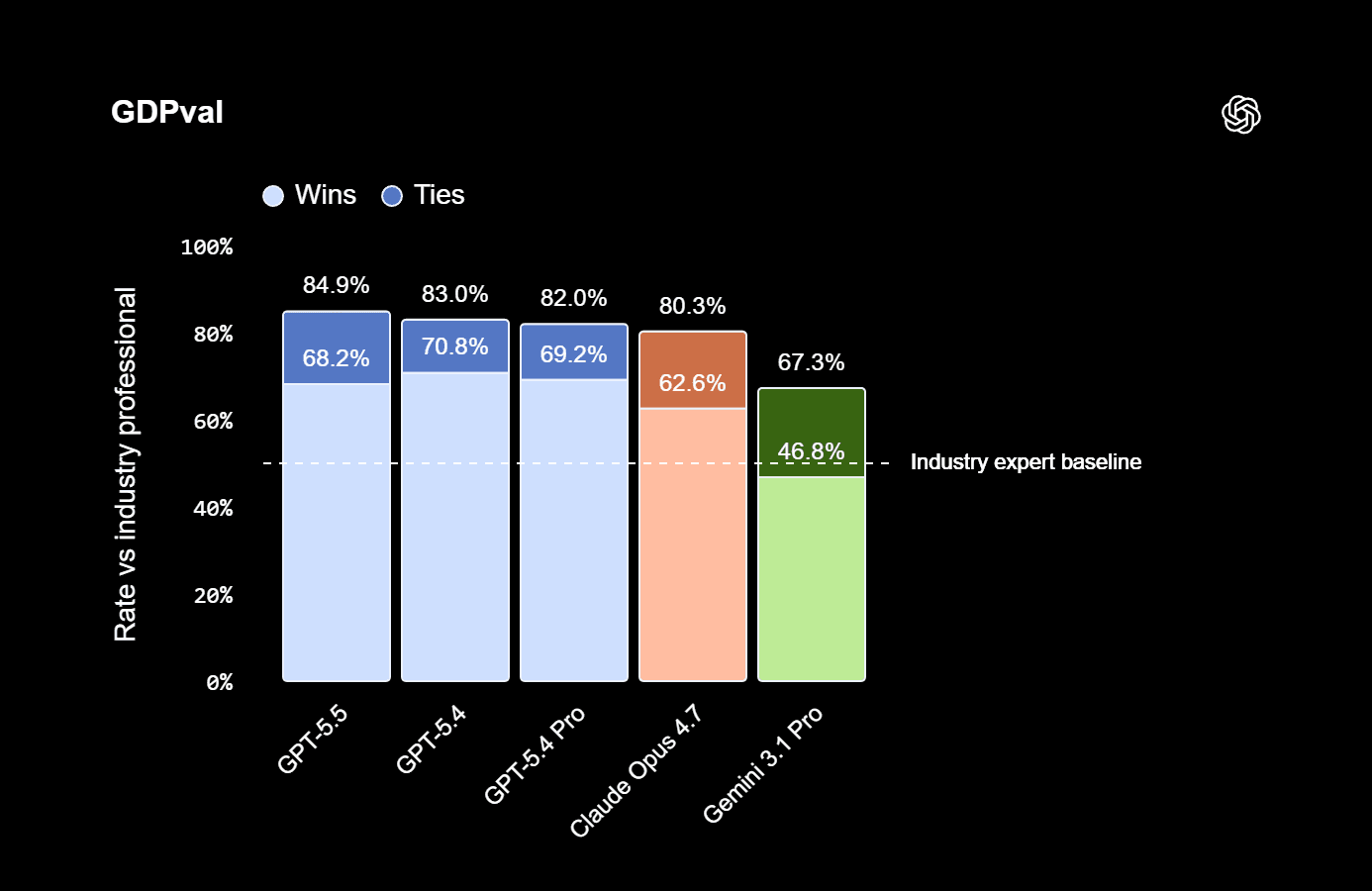
| GDPval (wins/ties) | 84.9% | 83.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | 78.0% | - |
| Toolathlon | 55.6% | 54.6% | - | 48.8% |
| BrowseComp | 84.4% | 82.7% | 79.3% | 85.9% |
| FrontierMath Tier 4 | 35.4% | - | 22.9% | 16.7% |

OpenAI claims GPT-5.5 delivers these gains without sacrificing speed. The model reportedly matches GPT-5.4's per-token latency while using fewer tokens to complete the same Codex tasks.
Worth noting: GPT-5.5 doesn't lead every benchmark. On BrowseComp, Gemini 3.1 Pro edges out GPT-5.5 with 85.9% versus 84.4%. On OSWorld-Verified, Claude Opus 4.7 nearly matches GPT-5.5 at 78.0% versus 78.7%.
The Pro Variant
OpenAI has also launched GPT-5.5 Pro, positioned as an "iterative research partner." The Pro model shows modest improvements over the standard version on certain tasks.
On BrowseComp, GPT-5.5 Pro scores 90.1% compared to 84.4% for the standard model. On FrontierMath Tier 4, it reaches 39.6% versus 35.4%. On GDPval, the Pro variant actually scores slightly lower at 82.3% compared to 84.9% for standard GPT-5.5.
API Pricing: The Elephant in the Room
Doubling API costs is a bold move in a market where Anthropic and Google are competing aggressively on price. OpenAI is betting that performance gains justify the premium.
For companies already building on GPT-5.4, this creates a calculation: Is 7.6 percentage points on Terminal-Bench worth 100% more per API call? For some workflows, especially complex coding tasks, the answer might be yes. For simpler use cases, Claude Opus 4.7 at its current pricing could become more attractive.
Availability
GPT-5.5 is available now for ChatGPT and Codex users on Plus, Pro, Business, and Enterprise plans. API access is listed as "coming soon" with no specific date announced.
How Anthropic's valuation compares to OpenAI amid this product launch
OpenAI's recent enterprise security initiatives
Logicity's Take
Frequently Asked Questions
When is GPT-5.5 API access available?
OpenAI says API access is "coming soon" but hasn't announced a specific date. The model is already available for ChatGPT and Codex users on Plus, Pro, Business, and Enterprise plans.
How much does GPT-5.5 API cost?
API pricing will be double what GPT-5.4 costs. OpenAI hasn't released exact per-token rates yet.
Is GPT-5.5 better than Claude Opus 4.7?
On coding benchmarks like Terminal-Bench 2.0, GPT-5.5 scores 82.7% versus Claude's 69.4%. On FrontierMath Tier 4, it's 35.4% versus 22.9%. However, the models are closer on other tasks, and Claude nearly matches GPT-5.5 on OSWorld-Verified.
What's the difference between GPT-5.5 and GPT-5.5 Pro?
GPT-5.5 Pro is positioned as an "iterative research partner" with higher scores on BrowseComp (90.1% vs 84.4%) and FrontierMath Tier 4 (39.6% vs 35.4%). It actually scores slightly lower on GDPval.
What are GPT-5.5's main use cases?
OpenAI highlights agentic coding, computer use, knowledge work, and early scientific research. The model handles complex tasks autonomously across coding, web research, data analysis, and document creation.
Need Help Implementing This?
Source: The Decoder / Matthias Bastian
Official Cautions on Financial and Professional Use
The article provides new quotes from OpenAI spokesperson Niko Felix regarding the limitations of using AI for financial advice and clarifying that it is not a substitute for professionals. It also includes insights from NYU professor Srikanth Jagabathula on why hallucinations persist as a fundamental statistical trait in newer models.
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.





