Key Takeaways

- GPT, Claude, and Gemini scored around 50% on Bridgewater's finance relevance tests with basic prompts
- A fine-tuned Qwen3-235B model achieved 84.7% accuracy at 14x lower cost than frontier models
- The gap exists because correct answers live in proprietary expert judgment, not public training data
Bridgewater Associates and Thinking Machines Lab, the startup founded by former OpenAI CTO Mira Murati, claim a fine-tuned open-weight model beats GPT, Claude, and Gemini at evaluating financial documents. The reason the frontier models failed? The right answers were never in their training data.
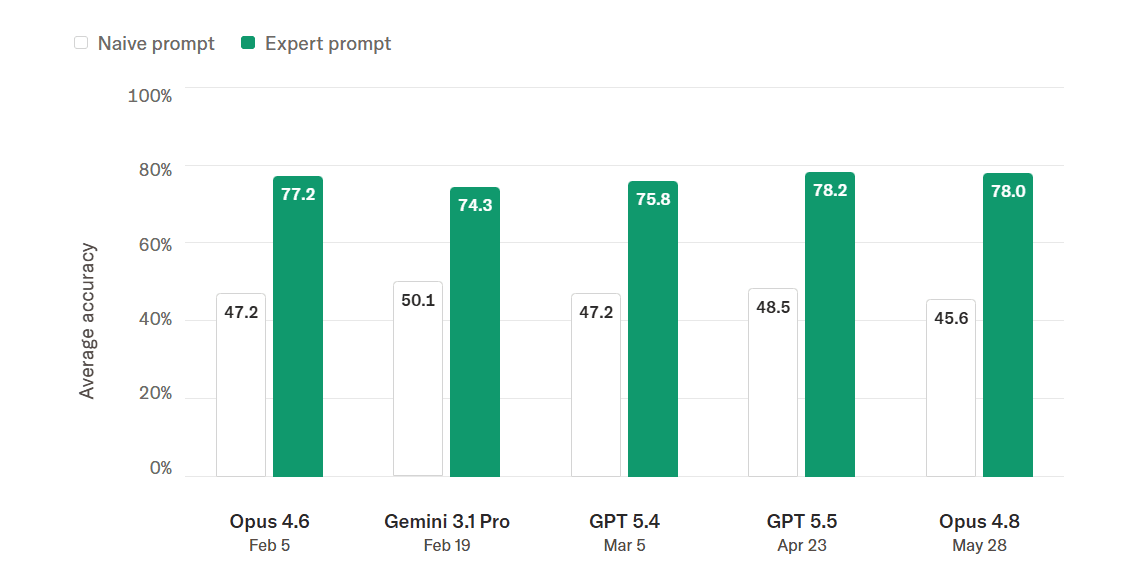
In internal tests, GPT and Claude variants hit only about 50% accuracy on basic prompts for financial relevance tasks. Expert-crafted prompts pushed accuracy into the mid-70s. That still fell short of the 80% threshold Bridgewater set for production deployment. The fine-tuned Qwen3-235B model, by contrast, reached 84.7% accuracy and costs 14 times less to run.
What tasks did the models fail at?
The researchers defined six tasks drawn from an investor's daily routine. One example: deciding whether a financial article is relevant to an executive. Another: whether a central bank document signals the direction of future rate changes.
These judgment calls are trivial for experienced investors but almost impossible to articulate as rules. The report gives a telling example. A headline about Trump's claim to Greenland gets flagged as irrelevant, while Trump's threat of new China tariffs is highly relevant. Both touch on geopolitics and finance. The difference lives entirely in context and investor intuition.
Frontier models couldn't bridge that gap because they were trained on public text. The judgment calls Bridgewater's analysts make every day, the implicit rules about what matters, never appeared in any dataset OpenAI or Anthropic could scrape.
Why fine-tuning worked where prompting failed
The solution was fine-tuning an open-weight model on proprietary examples. The key ingredient was the Bridgewater investors' judgment itself, distilled into training labels.
Initially, cheap outside contractors labeled documents, but many labels were wrong. The researchers used a clever workaround: a first model learned from the flawed labels, then re-evaluated the same documents. Wherever the model's prediction disagreed with the original label, there was likely an error. Only those disputed cases went to expensive internal investors for correction.
Training ran on Tinker, a fine-tuning platform from Thinking Machines Lab, using Alibaba's open-weight Qwen3-235B as the base. In Bridgewater's evaluation, the fine-tuned model hit 84.7% accuracy versus 78.2% for the best frontier model tested.
The cost trap of chasing frontier models
Newer models barely improve per dollar, according to the report. GPT 5.4 costs 43% more than 5.2 but delivers only marginal accuracy gains. For Bridgewater's specific use case, throwing money at the biggest model wasn't the answer.
This finding matters beyond finance. Any company with proprietary expertise, judgment calls their staff makes daily that never appear in public data, faces the same ceiling with off-the-shelf models. Fine-tuning lets them break through it.
Why companies might avoid frontier labs for sensitive data
The report hints at a strategic concern: anyone who hands proprietary data to a frontier lab risks competing against a product built on top of it. If Bridgewater fine-tuned GPT on their internal judgment, that knowledge might eventually flow back into OpenAI's general model.
Fine-tuning open models through platforms like Tinker gives companies an alternative. They keep the weights, the data, and depending on the setup, the GPUs themselves. No dependency on a vendor who might become a competitor.
Caveats worth noting
This isn't a truly independent comparison. Bridgewater and Thinking Machines Lab both have clear incentives to sell their approach. The evaluation was internal, not third-party audited. The 84.7% figure comes from their own benchmark.
Still, the broader point holds. The big labs haven't absorbed all the data that matters. Huge pools of proprietary corporate knowledge and untrained human expertise still exist. They represent real room for improvement, especially where companies deliberately keep their most valuable insights private.
Logicity's Take
For AI builders evaluating build-vs-buy for domain-specific tasks, this is a useful data point. If your use case involves judgment calls that experts make intuitively but can't articulate as rules, prompting frontier models may hit a ceiling around 75-80% accuracy. Fine-tuning open-weight models like Qwen3, Llama, or Mistral on proprietary labels could push past it. The economics favor fine-tuning when you need high-volume inference: 14x cost savings compounds fast. But the real question is whether you can extract your experts' judgment into clean training labels without burning through their time. Bridgewater's approach, using model disagreement to flag likely labeling errors, is a pattern worth stealing.
Frequently Asked Questions
Why did GPT and Claude fail Bridgewater's finance tests?
The correct answers depend on proprietary investor judgment that was never part of their public training data. Both models scored around 50% accuracy on basic prompts because they couldn't replicate reasoning that only exists inside Bridgewater.
What model did Bridgewater use instead?
They fine-tuned Qwen3-235B, an open-weight model from Alibaba, on their internal expert labels using the Tinker platform from Thinking Machines Lab.
How much cheaper is the fine-tuned model to run?
The fine-tuned Qwen3-235B costs approximately 14 times less to operate than frontier models like GPT or Claude for the same finance tasks.
Can other companies replicate this approach?
Yes, if they have domain experts whose judgment can be captured as training labels. The challenge is extracting that expertise efficiently. Bridgewater used a model-disagreement method to minimize how much expert time was required.
Is this evaluation reliable?
The 84.7% accuracy figure comes from Bridgewater's internal testing, not an independent audit. Both Bridgewater and Thinking Machines Lab have commercial incentives, so treat the specific numbers with appropriate skepticism.
Need Help Implementing This?
If you're evaluating fine-tuning strategies for domain-specific AI or comparing open-weight models for enterprise deployment, reach out to the Logicity team. We can help you navigate the tradeoffs between build, buy, and fine-tune.
Source: The Decoder / Maximilian Schreiner
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






