
Key Takeaways

- Zero AI outputs from any tested model were rated ready for client delivery
- 41% of AI outputs needed major rework, 27% were completely unusable
- GPT-5.4 scored highest but still failed nearly half the evaluation criteria
The finance industry keeps asking: can AI replace junior bankers? A new benchmark from Handshake AI and McGill University offers an answer. It's no.
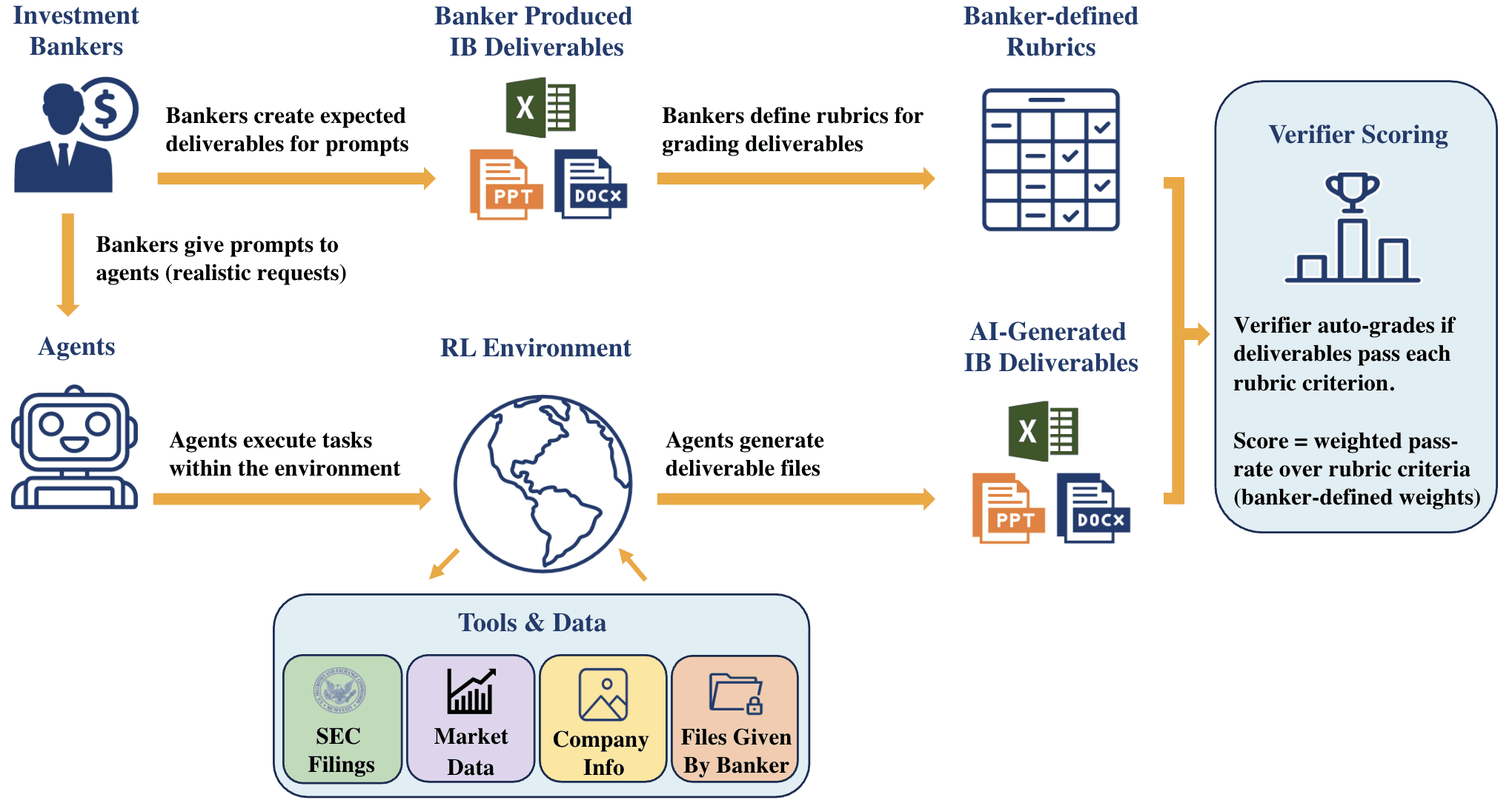
BankerToolBench tested nine top AI models, including GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro Preview, against 100 real investment banking tasks. The tasks weren't trivia questions or summarization exercises. They were actual deliverables: Excel financial models with working formulas, PowerPoint decks for client meetings, PDF reports, and Word memos.
The verdict from the roughly 500 current and former investment bankers who reviewed the outputs? Not a single result was ready to send to a client.
How the benchmark works
The research team recruited bankers from Goldman Sachs, JPMorgan, Evercore, Morgan Stanley, and Lazard. Of the 500 participants, 172 designed the tasks themselves. That work took more than 5,700 hours. Each of the 100 tasks required a human banker an average of five hours to complete. Some ran up to 21 hours.
These weren't simplified test cases. The AI agents had to dig through data rooms, pull information from market data platforms like FactSet and Capital IQ, and parse SEC filings. A single task could trigger up to 539 calls to the language model. According to the paper, 97% of those calls involved tool use or code execution.
Each deliverable was graded against a rubric averaging 150 individual criteria. The criteria covered six areas: technical correctness, client readiness, compliance, auditability, and consistency across files. An AI verifier called Gandalf, built on Gemini 3 Flash Preview, handled the grading. It agreed with human reviewers 88.2% of the time. That's slightly better than the 84.6% agreement rate between two human reviewers.
The results: failing grades across the board
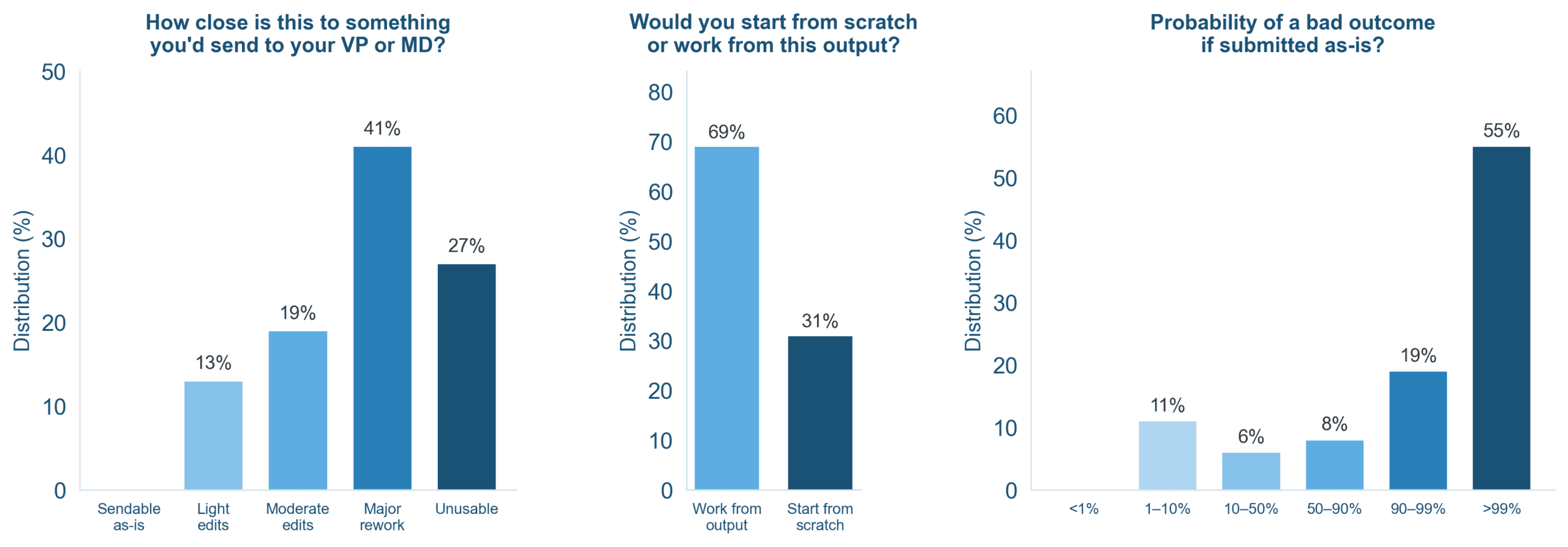
The bankers sorted AI outputs into four categories. Here's how the work landed:
- 0% ready to send to a client as-is
- 13% could pass with light edits
- 41% needed major rework
- 27% were completely unusable
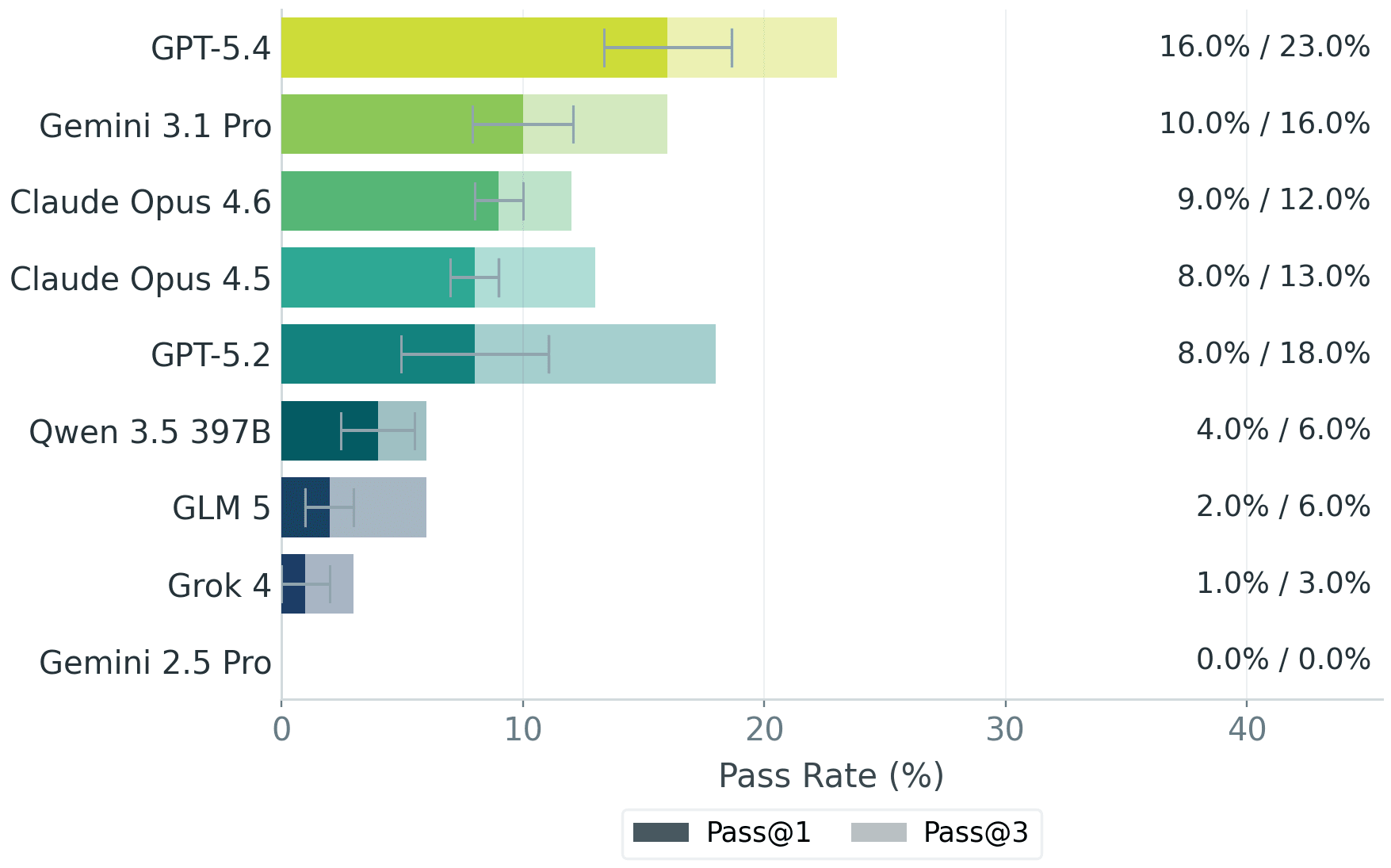
GPT-5.4 performed best among the tested models but still failed nearly half the evaluation criteria. Only 16% of its outputs cleared the bar where bankers would accept them as a useful starting point. Require three consistent runs, and that drops to 13%.
Model-by-model comparison
The team tested nine models in total: GPT-5.2, GPT-5.4, Claude Opus 4.5, Claude Opus 4.6, Gemini 2.5 Pro, Gemini 3.1 Pro Preview, Grok 4, Qwen-3.5-397B, and GLM-5.
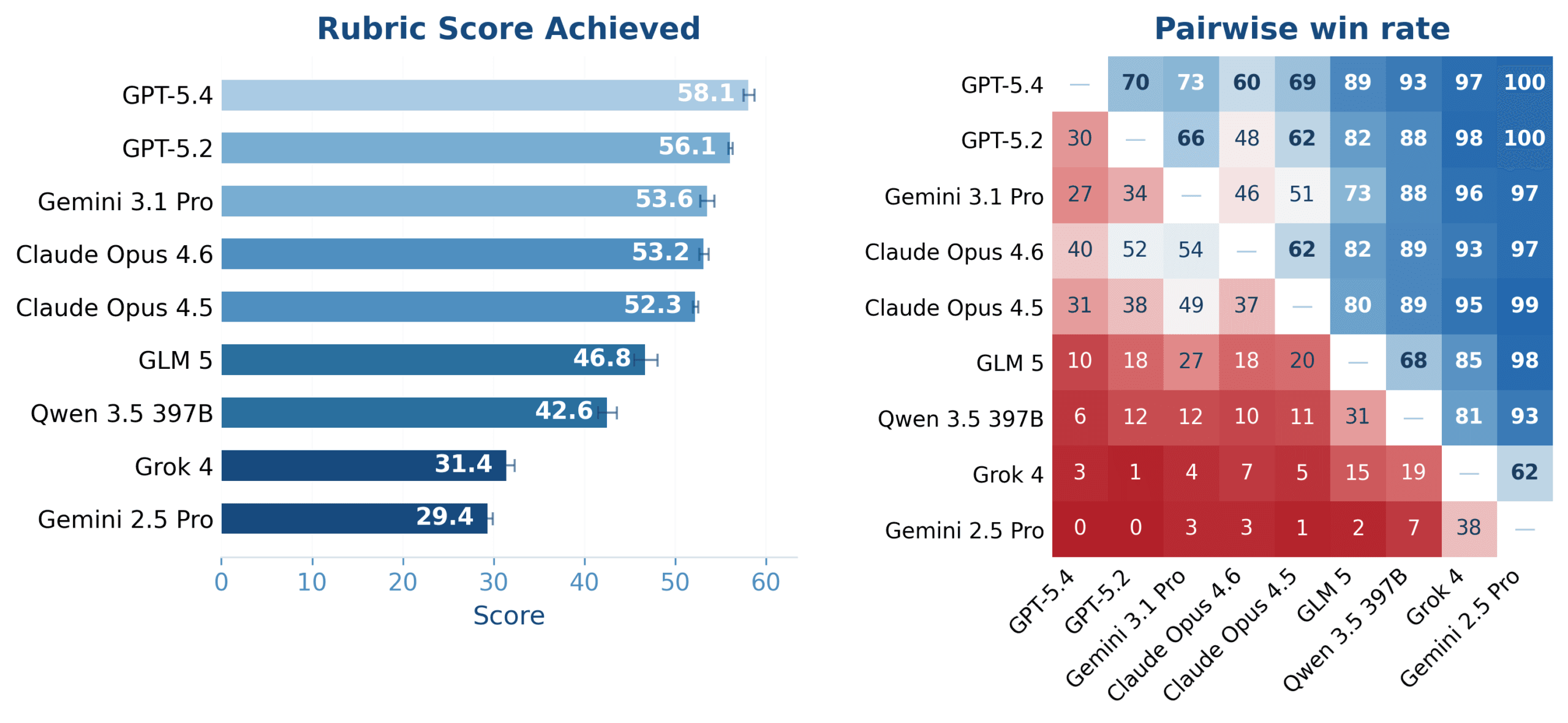
The rubric scores tell a similar story. GPT-5.4 scored 58.1 out of 100. GPT-5.2 followed behind. The open-source models Qwen-3.5-397B and GLM-5 trailed the proprietary options.
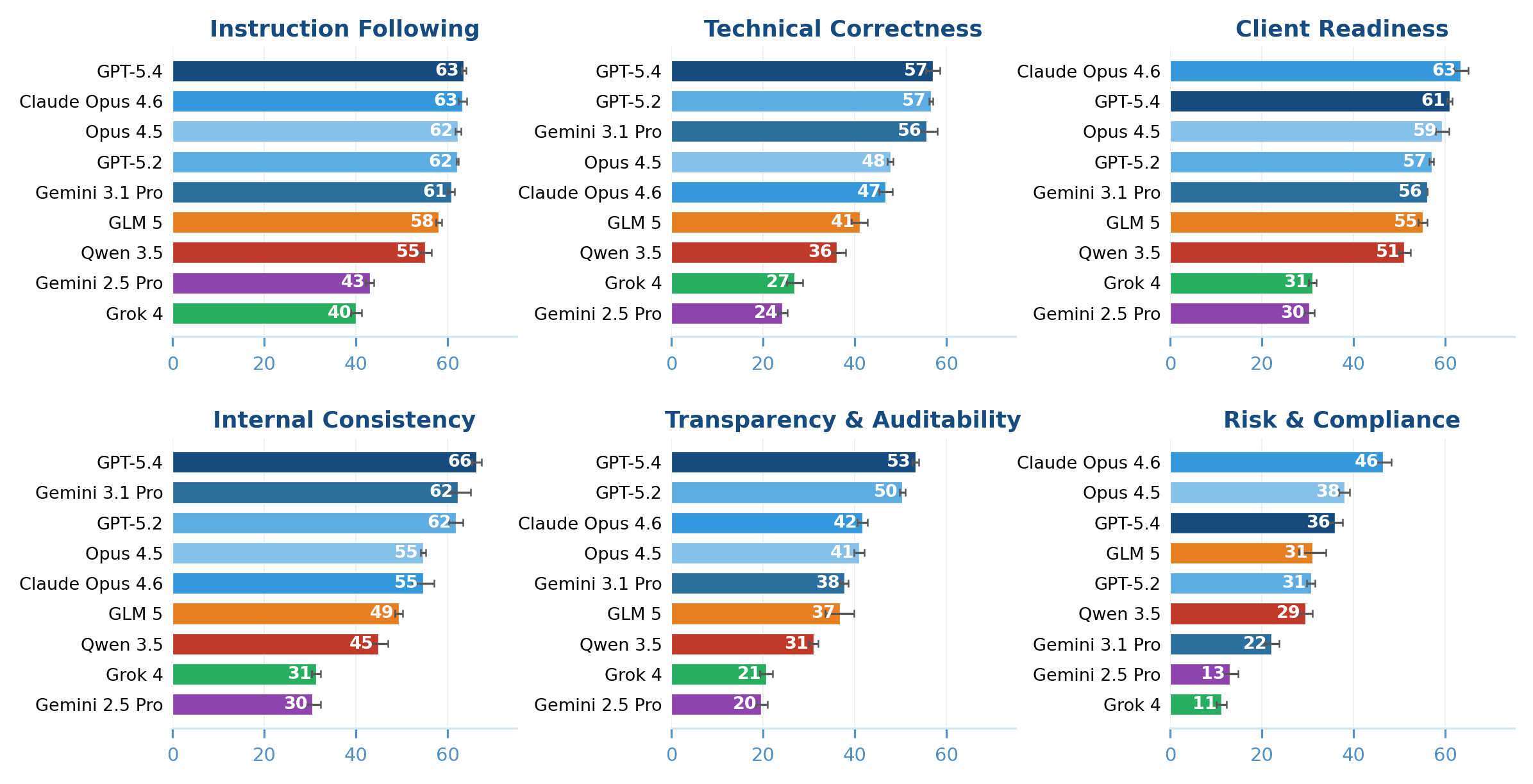
Across the six evaluation categories, no model showed consistent strength. Technical correctness and auditability proved especially difficult. Client readiness scores were low across the board.
The silver lining: starting points, not replacements
Despite the poor scores, more than half the bankers said they would use AI outputs as a starting point. The models can generate rough drafts, pull together data, and handle some formatting. The problem is reliability. Bankers can't trust the output without checking every cell, every formula, every number.
For tasks that take five to 21 hours, that's still meaningful. An AI draft that needs two hours of cleanup beats starting from scratch. But it's far from the autonomous AI agents that some vendors promise.
Logicity's Take
What this means for AI deployment in finance
BankerToolBench is open-source, so other researchers can replicate and extend the work. Handshake AI, the business arm of the career platform Handshake, built the benchmark to help AI labs understand real-world performance gaps.
The benchmark matters because it tests what actually matters in finance: deliverables, not chat responses. A model that can discuss DCF analysis in conversation might still produce an Excel model with broken formulas. BankerToolBench catches that gap.
For banks evaluating AI tools, the takeaway is clear. Current models can accelerate work but require substantial human oversight. The ROI case depends on how much time review takes versus starting fresh.
Another look at how AI agents perform in complex, real-world tasks
Frequently Asked Questions
Which AI model performed best on investment banking tasks?
GPT-5.4 scored highest with 58.1 out of 100 on the rubric, but still failed nearly half the evaluation criteria. No model produced client-ready output.
What percentage of AI outputs were usable for investment banking?
Only 13% of outputs could pass with light edits. 41% needed major rework, 27% were completely unusable, and 0% were ready to send to clients as-is.
What tasks did BankerToolBench test AI models on?
The benchmark tested real investment banking deliverables: Excel financial models with working formulas, PowerPoint decks, PDF reports, and Word memos. Tasks involved parsing SEC filings and pulling data from platforms like FactSet and Capital IQ.
Who created the BankerToolBench AI benchmark?
Handshake AI and McGill University created BankerToolBench. About 500 current and former investment bankers from firms including Goldman Sachs, JPMorgan, and Morgan Stanley participated in designing tasks and reviewing outputs.
Can AI replace junior investment bankers?
Not yet. While 53% of bankers said AI outputs are useful as a starting point, none of the outputs were client-ready. AI can accelerate drafting but requires substantial human review.
Need Help Implementing This?
Source: The Decoder / Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.





