لماذا فشل GPT وClaude في اختبارات Bridgewater المالية؟ الإجابات لم تكن متاحة للعامة أصلاً

أبرز النقاط
- نموذج Qwen3-235B المُعدَّل حقق دقة 84.7% مقابل 78.2% لأفضل النماذج التجارية
- تكلفة التشغيل أقل بـ 14 مرة من نماذج GPT وClaude
- البيانات الخاصة والخبرة البشرية غير المُرقمنة تظل ميزة تنافسية حقيقية
حين اختبر صندوق التحوط الأكبر عالمياً Bridgewater Associates نماذج الذكاء الاصطناعي الرائدة — GPT وClaude وGemini — على مهام التقييم المالي اليومية، جاءت النتيجة صادمة: دقة لا تتجاوز 50% مع التعليمات الأساسية. السبب؟ الإجابات الصحيحة لم تكن متاحة للعامة قط، لأنها تعيش في رؤوس المستثمرين المحترفين.
التقرير الصادر عن مختبرات AIA التابعة لـ Bridgewater وشركة Thinking Machines Lab — التي أسستها ميرا موراتي، الرئيسة التقنية السابقة لـ OpenAI — يكشف كيف تمكن الفريقان من تجاوز هذه الفجوة عبر تدريب نموذج مفتوح المصدر على بيانات داخلية، ليحقق دقة 84.7% بتكلفة أقل 14 مرة.
ما المهام التي فشلت فيها النماذج التجارية؟
يغرق المستثمرون يومياً في طوفان من الأخبار والتحليلات والإيداعات الرسمية والرسائل الإلكترونية. لكن القراءة ليست العمل الحقيقي — بل الفرز المتواصل: ما الذي يستحق الانتباه فعلاً؟
حدد الباحثون ست مهام مستمدة من الروتين اليومي للمستثمر. مثال: تحديد ما إذا كان مقال مالي مُهماً لمسؤول تنفيذي، أو ما إذا كانت وثيقة بنك مركزي تُشير إلى اتجاه أسعار الفائدة مستقبلاً.
التقرير يقدم مثالاً كاشفاً: عنوان عن مطالبة ترامب بغرينلاند يُصنَّف "غير ذي صلة"، بينما تهديده بفرض رسوم جمركية جديدة على الصين يُصنَّف "شديد الأهمية". كلاهما يتناول الجغرافيا السياسية والمال، لكن المستثمر المحترف يميز بينهما بحدس يصعب صياغته في كلمات.
لماذا لم تنجح التعليمات المتقدمة في سد الفجوة؟
مع التعليمات الأساسية، حققت نماذج Gemini وClaude وGPT دقة قرابة 50% — أداء عشوائي فعلياً. حين أضاف الباحثون تعليمات مكتوبة من خبراء ونظام تصنيف ثلاثي (ذو صلة ومثير للاهتمام، ذو صلة لكنه غير مثير، غير ذي صلة)، قفزت الدقة إلى منتصف السبعينيات.
لكن هذا ظل دون عتبة الـ 80% التي حددها الفريق كحد أدنى للاعتماد. الأسوأ: الجيل الأحدث من النماذج لا يبرر تكلفته. GPT 5.4 يكلف 43% أكثر من الإصدار 5.2، لكنه أدق بشكل هامشي فقط.
كيف نجح التدريب الدقيق في تجاوز هذا السقف؟
الحل كان fine-tuning — إعادة تدريب نموذج مفتوح الأوزان على أمثلة داخلية. المكون الجوهري: أحكام مستثمري Bridgewater أنفسهم.
في البداية، استعان الفريق بمقاولين خارجيين لتصنيف الوثائق، لكن كثيراً من تصنيفاتهم كانت خاطئة. ولتجنب إرهاق المحترفين المكلفين بمراجعة كل شيء، ابتكروا حلاً ذكياً:
- تدريب نموذج أولي على التصنيفات المعيبة
- إعادة تقييم الوثائق ذاتها بالنموذج الجديد
- تحديد نقاط الخلاف بين النموذج والتصنيف الأصلي — غالباً مواطن الخطأ
- إرسال الحالات المتنازع عليها فقط إلى المستثمرين للتصحيح
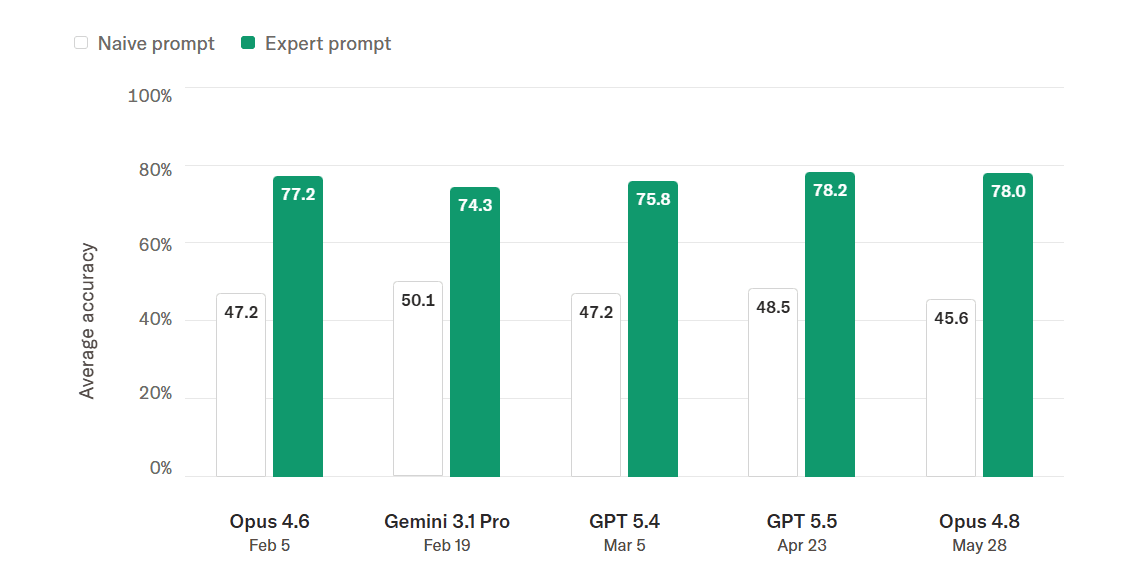
جرى التدريب عبر منصة Tinker من Thinking Machines Lab، المبنية فوق النموذج المفتوح Qwen3-235B. في التقييم الداخلي، حقق النموذج المُعدَّل دقة 84.7% مقابل 78.2% لأفضل نموذج تجاري — بتكلفة تشغيل أقل بنحو 14 مرة.
ما الذي يعنيه هذا لمستقبل الذكاء الاصطناعي المؤسسي؟
التقرير يؤكد ما بات واضحاً: مختبرات الذكاء الاصطناعي الكبرى مثل OpenAI وAnthropic لم تستوعب كل البيانات المتاحة. تظل هناك برك ضخمة من البيانات المؤسسية الخاصة والخبرة البشرية غير المُرقمنة — وهي تحمل مساحة حقيقية للتحسين.
هذا صحيح بشكل خاص حيث تحرص المؤسسات على إبقاء بياناتها الأثمن طي الكتمان. من يسلم تلك البيانات لمختبر رائد يخاطر بمنافسة منتج مبني فوقها لاحقاً.
التدريب الدقيق للنماذج المفتوحة عبر أدوات مثل Tinker يمنح المؤسسات بديلاً: تحتفظ بالأوزان، بالبيانات، وبحسب الإعداد — بالـ GPUs نفسها.
رأي Logicity
هذه الدراسة تُعيد التذكير بأن المنافسة الحقيقية في الذكاء الاصطناعي المؤسسي ليست على حجم النموذج، بل على جودة البيانات الخاصة. للمقارنة: منصات مثل Together AI وFireworks AI تقدم fine-tuning لنماذج مفتوحة بتسعير يبدأ من بضعة دولارات لكل مليون token، بينما تتراوح تكلفة الاستدلال على GPT-4o بين 2.5 و10 دولارات لكل مليون token حسب السياق. Thinking Machines Lab تدخل هذا السوق بتركيز واضح على القطاع المالي — وهو قطاع يدفع علاوة مقابل السرية.
ما التحفظات على هذه النتائج؟
يجب قراءة الأرقام بحذر: المقارنة ليست مستقلة تماماً. كلا الشركتين — Bridgewater وThinking Machines Lab — لديهما مصلحة في تسويق منتجهما. التقييم داخلي، والمهام مُصممة بناءً على احتياجات Bridgewater تحديداً.
مع ذلك، الاستنتاج الأوسع يظل صلباً: النماذج العامة مدربة على بيانات عامة، والبيانات الخاصة تبقى ميزة تنافسية لمن يمتلكها — ويعرف كيف يستخدمها.
الأسئلة الشائعة
لماذا فشلت نماذج GPT وClaude في اختبارات Bridgewater المالية؟
لأن الإجابات الصحيحة لم تكن متاحة في بيانات التدريب العامة. هذه الأحكام تعيش في رؤوس المستثمرين المحترفين ولم تُنشر قط.
ما النموذج المفتوح الذي استخدمته Bridgewater؟
Qwen3-235B، نموذج مفتوح الأوزان بـ 235 مليار معامل، طورته Alibaba وأُعيد تدريبه عبر منصة Tinker.
كم يوفر التدريب الدقيق مقارنة بالنماذج التجارية؟
النموذج المُعدَّل يكلف تشغيله أقل بـ 14 مرة من النماذج التجارية الرائدة مثل GPT وClaude.
هل يمكن لأي شركة تكرار هذا النهج؟
نظرياً نعم، لكنه يتطلب بيانات داخلية عالية الجودة، خبراء لتصحيح التصنيفات، وبنية تحتية للتدريب. منصات مثل Tinker وTogether AI تسهل الجانب التقني.
ما الذي تفعله Thinking Machines Lab؟
شركة أسستها ميرا موراتي، الرئيسة التقنية السابقة لـ OpenAI، وتقدم منصة Tinker لتدريب النماذج المفتوحة على بيانات المؤسسات الخاصة.
هل تحتاج مساعدة في التطبيق؟
إذا كنت تفكر في تدريب نموذج مفتوح على بيانات مؤسستك المالية أو التقنية، تواصل مع فريق Logicity للحصول على إرشادات حول المنصات المتاحة وأفضل الممارسات.
فاطمة الزهراء
كاتبة تقنية متخصصة في الذكاء الاصطناعي
أُنتِج هذا المقال بمساعدة الذكاء الاصطناعي وراجعه فريق التحرير في لوجيسيتي. اعرف المزيد في سياسة التحرير.