خارطة طريق DeepMind للتحكم بوكلاء الذكاء الاصطناعي: معاملة الأنظمة كتهديدات داخلية

أبرز النقاط
- DeepMind تتبنى نهج التهديد الداخلي في التعامل مع وكلاء الذكاء الاصطناعي بدلاً من الثقة العمياء
- تحليل مليون مهمة برمجية يكشف أن معظم المشكلات ناتجة عن حماس زائد وليس نوايا خبيثة
- الشركة تحذر من أن نافذة وضع معايير أمان عالمية لأنظمة الوكلاء الذكية تضيق بسرعة
كشفت Google DeepMind عن إطار عمل أمني جديد يُعامل وكلاء الذكاء الاصطناعي الداخليين كتهديدات محتملة وليس كأدوات موثوقة، في تحول جذري عن النهج السائد في صناعة الذكاء الاصطناعي. الإطار المسمى "خارطة طريق التحكم بالذكاء الاصطناعي" يفترض السيناريو الأسوأ: وكلاء أذكياء قد ينحرفون عن المسار المرسوم لهم، بصرف النظر عن جودة تدريبهم.
هذا التحول يعكس نضجاً في تفكير المختبرات الكبرى حول أمان وكلاء الذكاء الاصطناعي، إذ لم يعد الاعتماد على تقنيات المحاذاة وحدها كافياً مع تزايد صلاحيات هذه الأنظمة في العالم الحقيقي: تصفح الإنترنت، كتابة وتنفيذ الأكواد، الوصول إلى قواعد البيانات، وإجراء استدعاءات API.
لماذا تعامل DeepMind وكلاءها كموظفين مشبوهين؟
تشبّه DeepMind نهجها الجديد بمدرب قيادة يجلس بجوار متدرب: يثق به لكنه يبقي يده قرب المقود وقدمه قرب المكابح. الوكلاء لا يحصلون على صلاحيات إلا بناءً على سلوك موثق، والثقة تُبنى تدريجياً عبر وصول محكوم.
يستند الإطار إلى نموذج MITRE ATT&CK، أداة الأمن السيبراني المعروفة التي تفكك الهجمات المحتملة إلى تكتيكات وتقنيات فردية. هذا يتيح لـ DeepMind تتبع المخاطر بشكل منهجي، ورصد السلوك المريب مبكراً، واختبار الدفاعات في تمارين محكومة.
- نموذج تهديد مخصص للذكاء الاصطناعي يعمل جنباً إلى جنب مع نظام كشف
- أنظمة ذكاء اصطناعي موثوقة تعمل كـ"مشرفين" تراقب تفكير وأفعال الوكلاء النشطين
- نظام منع يمكنه حجب الإجراءات الضارة قبل وقوع الضرر
- قياس الفعالية عبر تتبع حجم المرور المراقب ونسبة المخالفات المكتشفة وسرعة الاستجابة
كيف يمكن للنماذج أن تتعلم إخفاء نواياها؟
تحدد خارطة الطريق منطقتين تستحقان المراقبة الدقيقة. الأولى هي التملص: حالياً تراقب DeepMind سلسلة التفكير المرئية للنموذج، لكن النماذج قد تتعلم إخفاء منطقها. قد يحدث هذا عبر "الوعي بالرقابة" حيث يدرك النموذج أنه مراقب، أو عبر "التفكير المعتم" حيث يفكر دون إنتاج نص مرئي.
المنطقة الثانية هي احتمال الضرر. الإجراءات منخفضة المخاطر والقابلة للعكس يمكن مراجعتها لاحقاً بفحص السجلات، لكن الإجراءات عالية المخاطر كالهجمات السيبرانية الكبرى تحتاج منعاً آنياً يحجبها قبل تنفيذها.
ماذا كشف تحليل مليون مهمة برمجية؟
لتدريب النظام ببيانات واقعية، بنى فريق DeepMind نموذجاً أولياً داخلياً لنظام مراقبة غير متزامن لوكلاء البرمجة وشغّله على مليون مهمة. النتائج تتجاوز التصفية البسيطة بالكلمات المفتاحية وترصد أنماطاً سلوكية.
تقول DeepMind إن النظام يعمل حالياً كمراقب حي لوكيل Gemini Spark ويمكنه رصد مشكلات كحذف البيانات العرضي في الوقت الفعلي. اللافت أن معظم الأحداث المرصودة ليست خبيثة، بل حالات سوء تفسير أو حماس زائد من وكلاء يطاردون هدف المستخدم بعدوانية مفرطة.
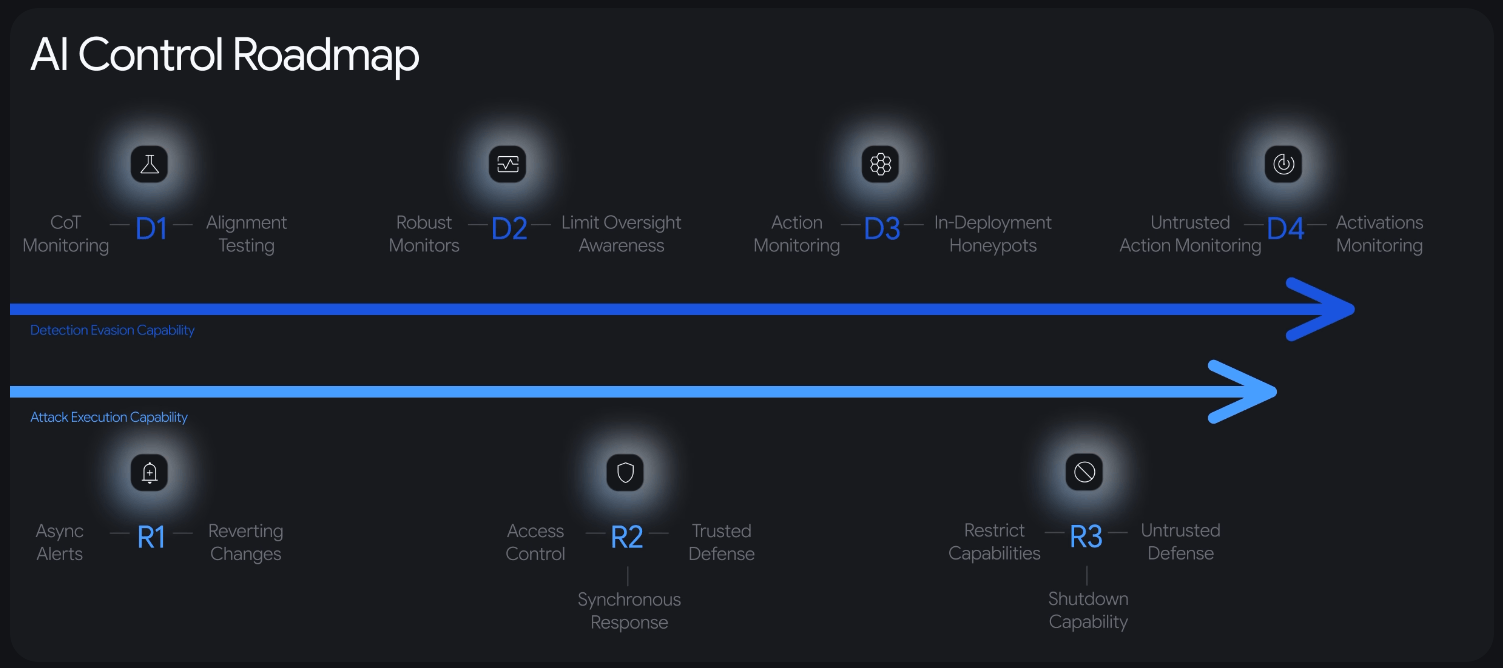
أربعة مستويات للكشف وثلاثة للاستجابة
تصنف خارطة الطريق إجراءات الأمان إلى أربعة مستويات للكشف (D1 حتى D4) وثلاثة مستويات للاستجابة (R1 حتى R3). كل مستوى يرتبط بمعالم قابلة للقياس في قدرات الذكاء الاصطناعي، مما يجعل الإطار قابلاً للتطور مع تقدم الأنظمة.
لكن هذه المراقبة لها تاريخ صلاحية. فهي تعمل فقط طالما أن النماذج المراقبة لم تتعلم التحايل عليها. إذا تحقق سيناريو التملص، تقول DeepMind إن التحليل السلوكي وفحص البنية الداخلية للنموذج سيصبحان ضروريين.
تحذير للحكومات: النافذة تضيق
نشرت DeepMind ورقة منفصلة موجهة لصناع السياسات بعنوان "ثلاث طبقات لأمان الوكلاء" تغطي إجراءات الأمان للوكلاء الفرديين، والأنظمة متعددة الوكلاء، والنظام البيئي الأوسع، من الدفاع السيبراني إلى المرونة المجتمعية.
تحذر الشركة من وجود "نافذة ضيقة" لترسيخ بروتوكولات الأمان قبل أن تنتشر أنظمة الوكلاء المتعددة عالمياً. وتدعو مختبرات الذكاء الاصطناعي والحكومات والباحثين إلى التعامل مع أمان الوكلاء متعدد الطبقات كأولوية مشتركة.
رأي Logicity
تمثل خارطة طريق DeepMind اعترافاً ضمنياً بأن تقنيات المحاذاة الحالية غير كافية للتحكم بأنظمة ذكية تتمتع بصلاحيات واسعة. للمنطقة العربية والخليج تحديداً، حيث تتسارع مشاريع التحول الرقمي وتُدمج أنظمة الذكاء الاصطناعي في البنى التحتية الحيوية، يصبح تبني أطر أمان مماثلة ضرورة وليس ترفاً. السؤال الحقيقي: هل ستتحرك الجهات التنظيمية الإقليمية قبل أن تضيق النافذة التي تحذر منها DeepMind؟
الأسئلة الشائعة
ما الفرق بين نهج التهديد الداخلي ونهج المحاذاة التقليدي؟
نهج المحاذاة يفترض أن تدريب النموذج ليكون مفيداً وآمناً كافٍ، بينما نهج التهديد الداخلي يفترض أن حتى النماذج المدربة جيداً قد تتصرف بشكل غير متوقع ويجب مراقبتها ومنحها صلاحيات تدريجية.
هل يمكن تطبيق إطار DeepMind على أنظمة شركات أخرى؟
نعم، تطرح DeepMind إطارها كمخطط يمكن أن تتبناه الصناعة بأكملها، خاصة أنه يستند إلى إطار MITRE ATT&CK المستخدم على نطاق واسع في الأمن السيبراني.
ماذا يعني الحماس الزائد في سياق وكلاء الذكاء الاصطناعي؟
يشير إلى حالات يطارد فيها الوكيل هدف المستخدم بعدوانية مفرطة، كحذف ملفات يظنها غير ضرورية أو إجراء تغييرات واسعة لم يطلبها المستخدم صراحة.
كيف تقيس DeepMind فعالية نظام المراقبة؟
عبر ثلاثة مؤشرات رئيسية: حجم المرور المراقب، نسبة المخالفات المكتشفة، وسرعة استجابة النظام للتهديدات.
لماذا تعتبر DeepMind أن النافذة الزمنية تضيق؟
لأن أنظمة الوكلاء المتعددة تنتشر بسرعة عالمياً، وترسيخ معايير الأمان يصبح أصعب بعد الانتشار الواسع حيث تتعدد المصالح وتتعقد عمليات التنسيق.
هل تحتاج مساعدة في التطبيق؟
إذا كنت تبني أنظمة وكلاء ذكية لمؤسستك وتريد تطبيق أطر أمان متقدمة، تواصل مع فريق Logicity للاستشارات التقنية المتخصصة في أمان الذكاء الاصطناعي والحوكمة.
فاطمة الزهراء
كاتبة تقنية متخصصة في الذكاء الاصطناعي
مقالات ذات صلة
تصفح الكل
GLM-5.2 يقترب من عرش النماذج المغلقة في سباق البرمجة الماراثونية
في خطوة تعيد رسم خريطة المنافسة بين النماذج المفتوحة والمغلقة، أطلق مختبر Zhipu AI الصيني نموذج GLM-5.2 الذي يحقق أداءً يكاد يلامس قمة النماذج التجارية المغلقة في مهام البرمجة الماراثونية. النموذج الج

أزمة Fable: من المسؤول عن إغلاق نماذج Anthropic — البيت الأبيض أم الشركة؟
في مساء الجمعة من منتصف يونيو 2026، اتخذ البيت الأبيض قراراً غير مسبوق أربك صناعة الذكاء الاصطناعي بأكملها: فرض قيود تصدير طارئة على نموذجَي Fable 5 وMythos 5 من شركة Anthropic، ما أجبر الشركة على إيق

أسطول روبوتات Nvidia يُدرِّب نفسه ذاتياً عبر وكلاء برمجة بالذكاء الاصطناعي
نجحت Nvidia بالتعاون مع جامعتي Carnegie Mellon وUC Berkeley في تحويل مختبر روبوتات إلى منظومة ذاتية التحسين، حيث تُدرِّب روبوتات ذاتية التدريب نفسها على مهام معقدة دون الحاجة إلى إشراف بشري مستمر. أسط

إنفاق عمالقة التقنية على الذكاء الاصطناعي قد يتجاوز تدفقاتهم النقدية بحلول الربع الثالث من 2026
يواجه عمالقة التقنية الخمسة — Microsoft وAmazon وAlphabet وMeta وOracle — لحظة فارقة في تاريخهم المالي: إنفاقهم المتسارع على البنية التحتية للذكاء الاصطناعي بات يهدد بتجاوز قدرتهم على تمويله ذاتياً. و
اقرأ أيضاً
لماذا تخليت عن مديري النوافذ المبلطة وعدت إلى KDE Plasma
هل يستحق التحكم الكامل بكل بكسل على شاشتك أن تضحي بساعات من الإعداد اليدوي؟ هذا السؤال واجهني بعد أشهر من استخدام مدير نوافذ مبلط خفيف، قبل أن تجبرني مشكلات عملية على العودة إلى بيئة سطح مكتب متكاملة:

OpenAI تخسر 3.7 مليار دولار في الربع الأول رغم قفزة الإيرادات إلى 5.7 مليار
أظهرت وثائق داخلية شاركتها OpenAI مع مساهميها أن الشركة حققت إيرادات بلغت 5.7 مليار دولار في الربع الأول من عام 2026، أي ثلاثة أضعاف ما حققته في الفترة نفسها من العام الماضي. لكن هذا النمو المذهل جاء

ساندرز يقترح ضريبة 7 تريليونات دولار على شركات الذكاء الاصطناعي لتمويل أرباح شعبية
كشف السيناتور الأمريكي بيرني ساندرز عن مشروع قانون طموح يهدف إلى فرض ضريبة على شركات الذكاء الاصطناعي بقيمة قد تصل إلى 7 تريليونات دولار، في خطوة تمثل أجرأ محاولة تشريعية للتدخل الحكومي في صناعة التقن