Key Takeaways

- CSAT response rates below 10% leave most AI-handled conversations unmeasured
- AI-powered scoring can evaluate every conversation, delivering roughly 5x more coverage than surveys
- Teams should build new targets from actual data rather than mapping old CSAT thresholds to new metrics
CSAT captures less than 10% of customer conversations. The responses you do get skew toward extremes: the delighted and the furious. Everyone else stays silent. That silence is a blind spot, and it grows larger as AI handles more of your support volume.
Disclosure
Some links in this post are affiliate links — Logicity earns a commission if you sign up, at no extra cost to you. We only link products we have used or actively recommend.
Intercom published a detailed breakdown of how AI customer experience measurement needs to evolve. The core argument: when AI handles conversations end-to-end, traditional survey-based metrics leave teams flying blind. You cannot coach agents, improve AI responses, or report accurately to leadership when 90% of interactions generate no feedback at all.
What's actually wrong with CSAT?
Coverage is the obvious problem. A sub-10% response rate means you are basing decisions on an unrepresentative sample. But coverage is not the only limitation.
CSAT compresses multiple problems into a single score. A negative rating could stem from the product itself, a frustrating policy, or poor service quality. The number alone does not tell you which. Teams end up questioning the data rather than acting on it.
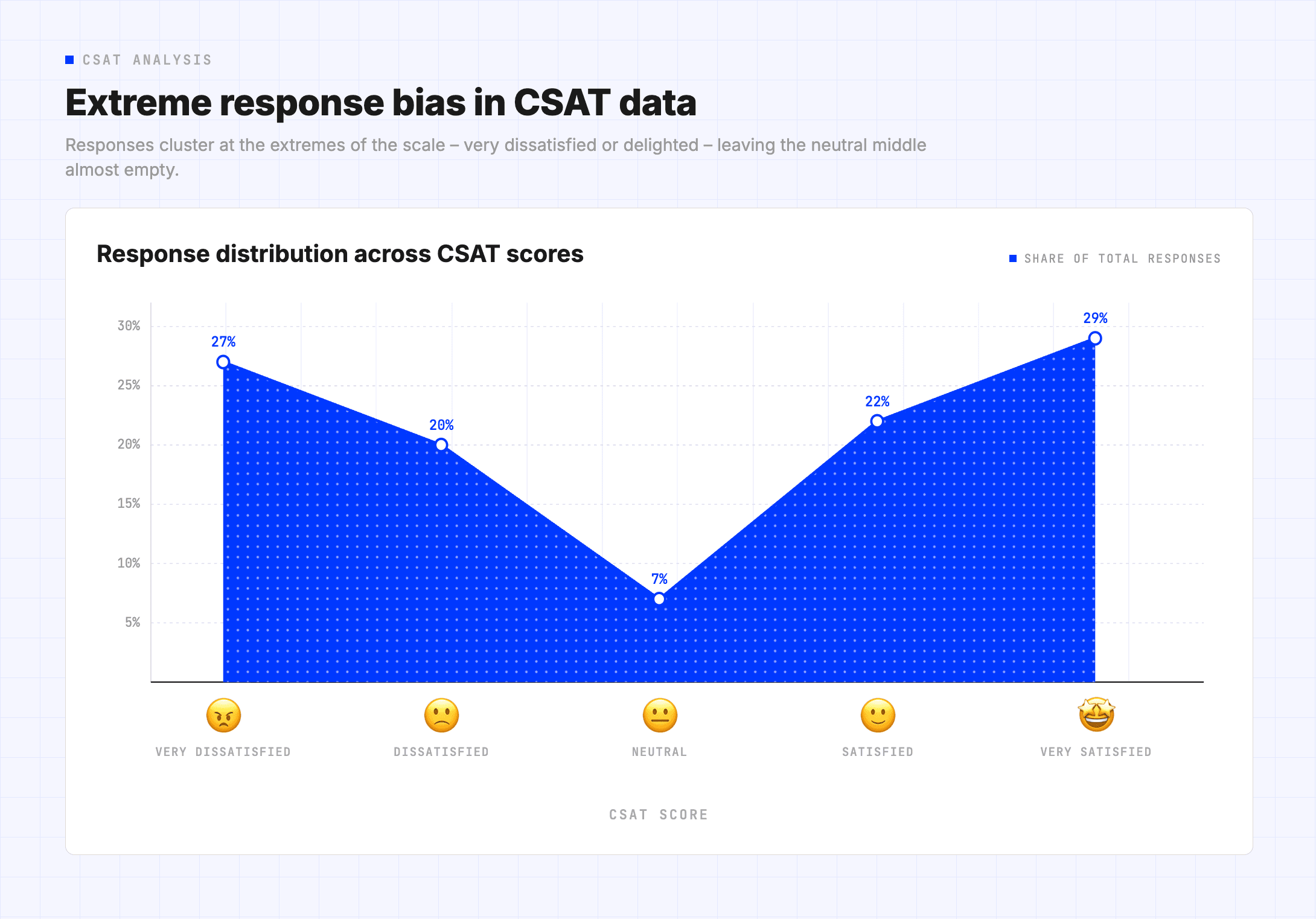
Worse, CSAT hides the friction that actually damages customer experience: repeated explanations, multiple handoffs, technically correct answers that still felt frustrating. These patterns never surface when you only hear from customers who bother to fill out surveys.
How AI enables full conversation coverage
AI lets support teams move from sampling to scoring every conversation. Instead of waiting for customers to tell you how it went, you can automatically evaluate each interaction.
When every conversation is visible, you get a complete picture of what customers actually experience across service quality, resolution, and customer effort. A single survey was never able to show this.

Intercom's Fin AI agent includes CX Score, which evaluates every interaction (both AI and human), assigns a score from 1-5, and surfaces the reasons behind each score. For most teams, this delivers roughly five times more conversation coverage than CSAT alone.
If you use a different support platform, the principle still applies. You need AI-powered visibility into every conversation, not just the ones that generate survey responses. Other platforms with AI scoring capabilities include Freshsales for sales conversations and Zendesk's AI features for support.
CSAT still has a role. It serves as an open door for customers who want to share their experience directly. But the scored view of every conversation tells you what's really happening across your entire customer experience.
How should teams set new targets?
You cannot map old CSAT targets onto a new metric. The coverage is different, so you need to build targets from the data itself.
Intercom's team started by correlating CX Score with operational metrics like first response time and time to close. That gave useful targets for human support. But they wanted deeper insight into how their AI agent was performing.
They broke CX Score down by underlying attributes: answer quality, customer effort, and product feedback. Answer quality had the biggest impact on the overall score, which makes sense since Fin handles the majority of conversations. That told them where to focus.

With an automation rate around 80%, they modeled what their score would look like if they eliminated low answer quality across both AI and human conversations. Initial targets based on those models, historical performance, and team ambition:
- Fin support: 80%
- Human support: 70%
- Overall: 78%
These targets have since been raised as performance improved. The point is building targets from what the data actually shows when you can see everything, rather than carrying over a threshold from a metric that measured something different.
Turning measurement into action
When every conversation is scored and the reasons behind each score are visible, recurring problems become traceable. You can identify which issues drive negative scores, how often they happen, and whether the root cause sits with support, product, or a specific workflow.
For example, you can see: which topics and conversation types score poorly and why, how scores differ across channels and between AI and human conversations, and which operational issues create friction for customers.
This changes the operational loop. Instead of working from a small number of survey responses and caveating how representative the data is, teams can route issues to the right owner, address them at the source, track whether the fix actually worked, and prevent the same problem from affecting the next customer.

A manager might spot that a particular topic is underperforming across the team and use that insight to update content or run a focused training session. Each pattern leads to a specific action. That is a fundamentally different workflow than hoping customers fill out surveys.
Logicity's Take
This shift from sampling to full-coverage scoring represents a structural change in how support teams operate. Intercom's CX Score is available on their Pro and Premium tiers (starting around $99/seat/month). Zendesk offers similar AI scoring in their Suite Professional tier ($115/agent/month). For smaller teams, Freshdesk's AI features start lower but with fewer analytics capabilities. The real question is not whether to adopt AI scoring, but whether your team can operationally act on the volume of insights full coverage generates. Most companies will need to invest in workflow automation tools like [Zapier](https://logicity.in/r/zapier) or [Make](https://logicity.in/r/make) to route issues automatically rather than drowning in data.
Frequently Asked Questions
Does AI scoring replace CSAT entirely?
No. CSAT still serves as an open channel for customers who want to share feedback directly. AI scoring supplements it by capturing the 90%+ of conversations where customers stay silent.
How accurate is AI-powered conversation scoring?
Accuracy depends on the model. Intercom reports that CX Score correlates with operational outcomes like resolution time and repeat contacts. Teams should validate AI scores against manual reviews during initial rollout.
What targets should I set for AI conversation scores?
Do not map old CSAT targets to new metrics. Build targets from your actual data by correlating scores with business outcomes, then model what improvement looks like based on specific attributes like answer quality.
Can I use AI scoring if I don't use Intercom?
Yes. The principle applies regardless of platform. Look for support tools with AI-powered quality scoring features. Zendesk, Freshdesk, and specialized QA tools like Klaus offer similar capabilities.
RevOps teams face similar measurement challenges across the customer lifecycle
Need Help Implementing This?
Evaluating AI scoring tools for your support stack? Reach out to the Logicity team for vendor comparisons and implementation guidance tailored to your team size and volume.
Source: The Intercom Blog / William Lane
Manaal Khan
Tech & Innovation Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.