Key Takeaways

- Fugu Ultra matches Anthropic's Fable 5 on benchmarks like SWE Bench Pro (73.7 vs 69.2) but early users report 30-minute waits for coding tasks
- The $200/month plan offers less than three hours of weekly usage, with one user burning five hours on a single prompt
- Sakana pitches the multi-LLM approach as protection against vendor lock-in after Anthropic's models faced export controls
Tokyo-based Sakana AI launched Fugu, a system that coordinates multiple language models to tackle complex tasks. The company claims Fugu Ultra matches Anthropic's Fable 5 and Mythos Preview on coding and reasoning benchmarks. Early users tell a different story: painfully slow responses, expensive quota burns, and output that falls short of the competition in practice.
What is Fugu and how does it work?
Fugu is itself a language model, trained to call other LLMs from a pool of available agents. When a request comes in, Fugu decides whether to handle it alone or assemble a team of specialized models. Selection, delegation, verification, and synthesis all happen internally. Users interact through a single OpenAI-compatible API, so the multi-model orchestration stays invisible.
Sakana offers two variants. The base Fugu model targets low latency for everyday coding, code review, and chatbot tasks. Teams with compliance requirements can exclude specific agents from the pool. Fugu Ultra aims for maximum quality on complex, multi-step problems. Early adopters have used it for AI research, reproducing scientific papers, cybersecurity analysis, and patent searches.
The benchmark numbers look impressive
Sakana's published results put Fugu Ultra ahead of or matching Anthropic's Fable 5 across several tests. On SWE Bench Pro, Fugu Ultra scored 73.7 compared to Opus 4.8's 69.2. LiveCodeBench shows 93.2 versus 87.8 for Opus. On Humanity's Last Exam, a reasoning benchmark, Fugu Ultra hit 50.0 while GPT 5.5 scored 41.4.
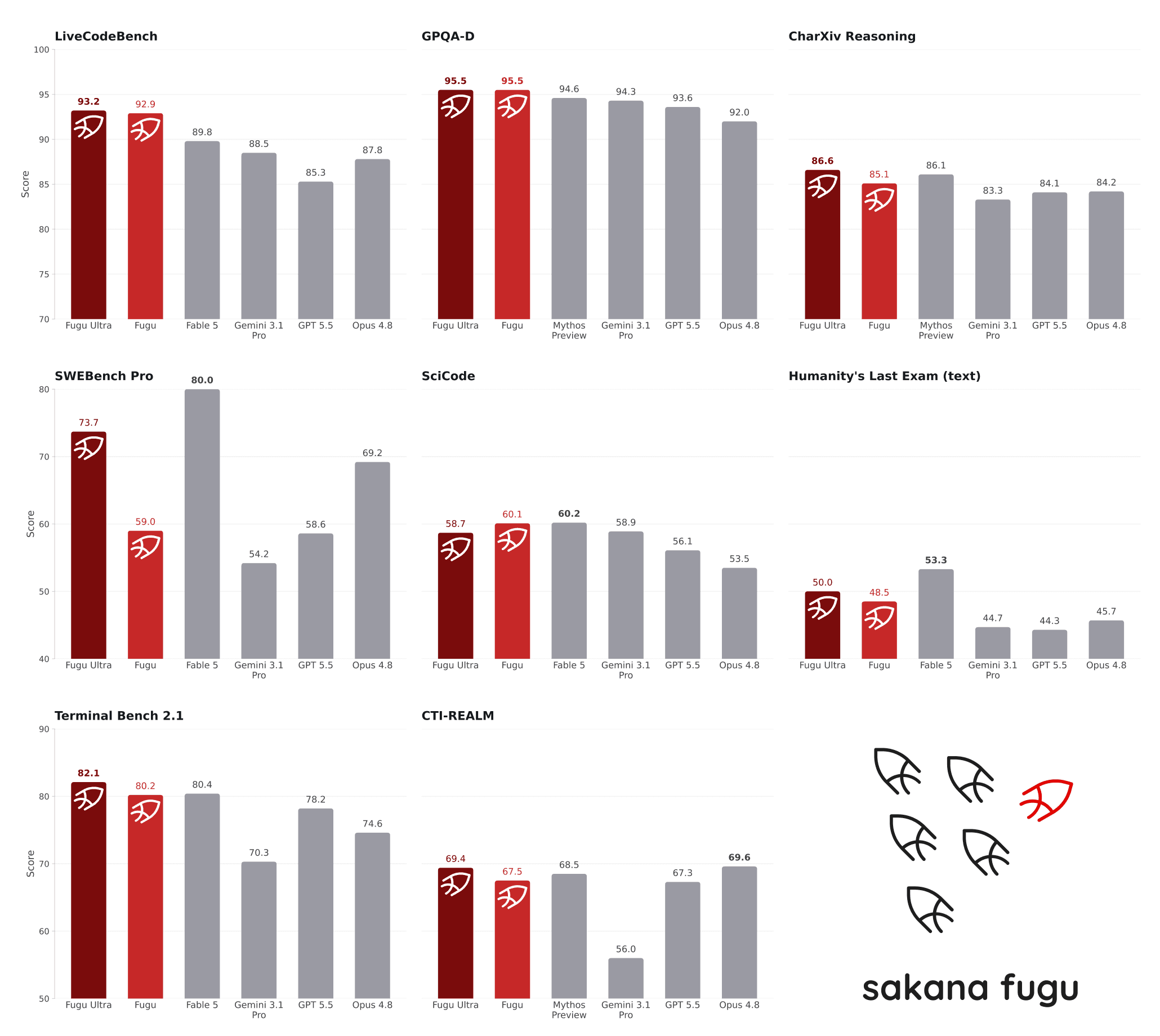
One caveat: neither Fable 5 nor Mythos Preview sits in Fugu's agent pool because they aren't publicly available. Sakana says adding those models would push scores even higher. The baseline comparison numbers come from the model providers themselves.
Early users report a rougher experience
AI researcher Ethan Mollick tested Fugu Ultra and called it "incredibly slow." His standard coding tests took 30 minutes. Results were "fine" but fell short of Fable in practice.
X user @LLMJunky had a worse experience. A single ThreeJS coding prompt burned through his entire five-hour quota on the $20 plan. The output came back "notably worse than GPT 5.5" and needed seven or eight fix rounds before the game even ran.
On Hacker News, developers complained that the $200/month plan delivers less than three hours of weekly usage. The API is reportedly slow, and output quality doesn't match Fable. Code reviews were a bright spot, roughly matching Opus 4.8 or GPT 5.5.
Hamel Husain agreed Fugu handles code reviews well but struggles with frontend work. He called it "a bit jagged in its abilities."
Speed versus quality: one head-to-head test
X user Mark Santos ran both systems on a Crossy Road clone. Fugu Ultra finished in 22 minutes at $7.32. Opus 4.8 took 79 minutes and cost $37.85. But Santos preferred the Opus output.
The tradeoff is clear: Fugu can be faster and cheaper, but you may spend more time fixing results. Whether that math works depends on the task and your tolerance for iteration.
The vendor lock-in argument
Sakana pitches Fugu as a hedge against single-provider dependence. The company points to recent export controls on Anthropic's Fable and Mythos models as a concrete example. Access to top AI systems can vanish overnight due to regulatory shifts or foreign policy decisions.
Critics pushed back on this sovereignty claim. Fugu still depends on whatever models sit in its pool. For benchmarks, Sakana used proprietary models like Claude Opus. Smart engineering can squeeze more out of existing AI models, but that's not new. This "harness engineering" already plays a big role in agentic AI systems.
Sakana had prior success with orchestration. Its ALE-Agent placed 21st out of 1,000 human experts in a coding competition. Whether that translates to consistent, production-ready performance is the open question.
Logicity's Take
For AI builders, Fugu represents a bet that orchestration overhead is worth the flexibility. The benchmark scores are real, but benchmarks measure tasks in isolation. Production workloads hit latency and cost constraints that matter more than leaderboard position. Teams evaluating Fugu should run their actual use cases, not generic tests, and budget for the quota limits. The vendor lock-in argument has merit in principle, but execution matters. If Fugu's pool still relies on the same handful of frontier models, you've added a layer of abstraction without gaining independence. Watch for Sakana to expand the agent pool with open-weight models like Llama or Mistral variants. That's when the sovereignty pitch gets real.
Frequently Asked Questions
How much does Sakana Fugu cost?
Sakana offers a $20/month plan with a five-hour quota and a $200/month plan. Users report the higher tier provides less than three hours of weekly usage for complex tasks.
Is Fugu faster than Claude Opus or GPT 5.5?
In one head-to-head test, Fugu Ultra completed a coding task in 22 minutes versus 79 minutes for Opus 4.8. However, multiple users report 30-minute waits for individual requests.
Can Fugu use any LLM in its agent pool?
Fugu can call from a configurable pool of models. Teams can exclude specific agents for compliance reasons. Anthropic's Fable and Mythos are not in the pool because they aren't publicly available.
Does Fugu actually beat Anthropic's benchmarks?
Sakana's published results show Fugu Ultra matching or exceeding Fable 5 on tests like SWE Bench Pro. Early users report real-world output quality falls short of the benchmark numbers.
Examines how AI model capabilities translate to real-world task performance
Need Help Implementing This?
Building with multi-model orchestration or evaluating AI systems for your product? Logicity helps technical teams cut through benchmark hype. Contact us for independent assessments of AI tooling decisions.
Source: The Decoder / Matthias Bastian
Manaal Khan
Tech & Innovation Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






