Open-Source Voice AI Decides to Speak Every 0.4 Seconds

Key Takeaways
- Audio Interaction processes continuous audio in 0.4-second chunks, deciding after each whether to respond or stay silent
- The model was trained on 302,000 hours of synthetic audio data and combines multiple tasks previously requiring separate models
- It outperforms its base model on benchmarks and beats Gemini 3 Flash in proactive noise detection
Today's voice assistants have a problem. They wait for you to finish talking before they respond. It's like having a conversation with someone who stares blankly until you say "over." GPT-4o, Qwen 3.5-Omni, and similar models work this way. They process audio only after the recording ends.
A new open-source model called Audio Interaction takes a different approach. It listens continuously and makes a decision every 0.4 seconds: speak or stay silent. The model comes from researchers at institutions in China, Hong Kong, and Singapore.
How the 0.4-Second Loop Works
The system breaks incoming audio into 0.4-second chunks. After each chunk, it outputs one of two tokens: <silent> or <response>. If it picks <silent>, it keeps listening. Only when it outputs <response> does it start generating speech.
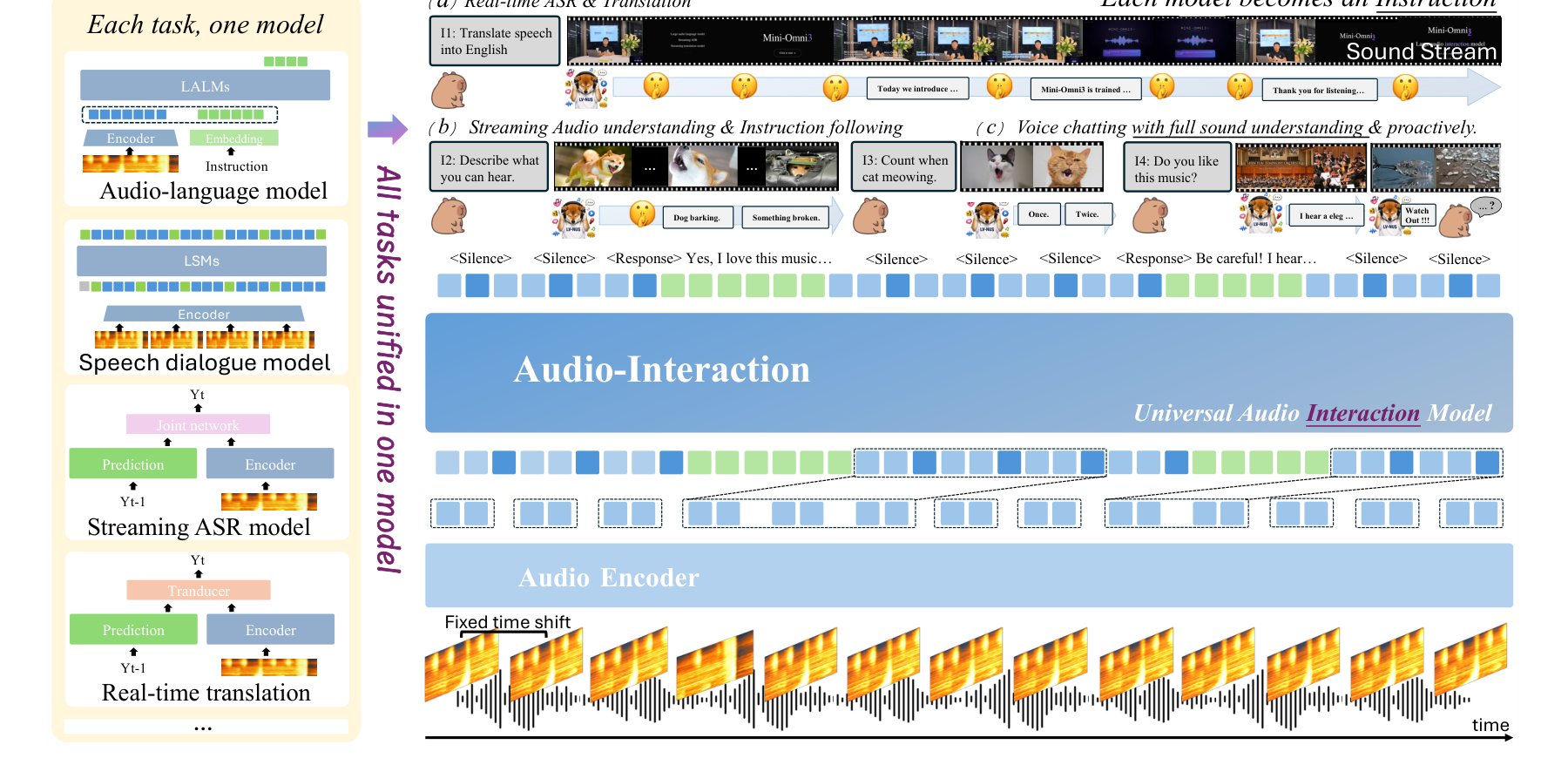
This lets the model handle multiple tasks in a single stream. Translation, transcription, dialogue, and reacting to everyday sounds all run through the same 3-billion-parameter architecture. Classic tasks like "Translate into English" become instructions within the continuous audio flow.
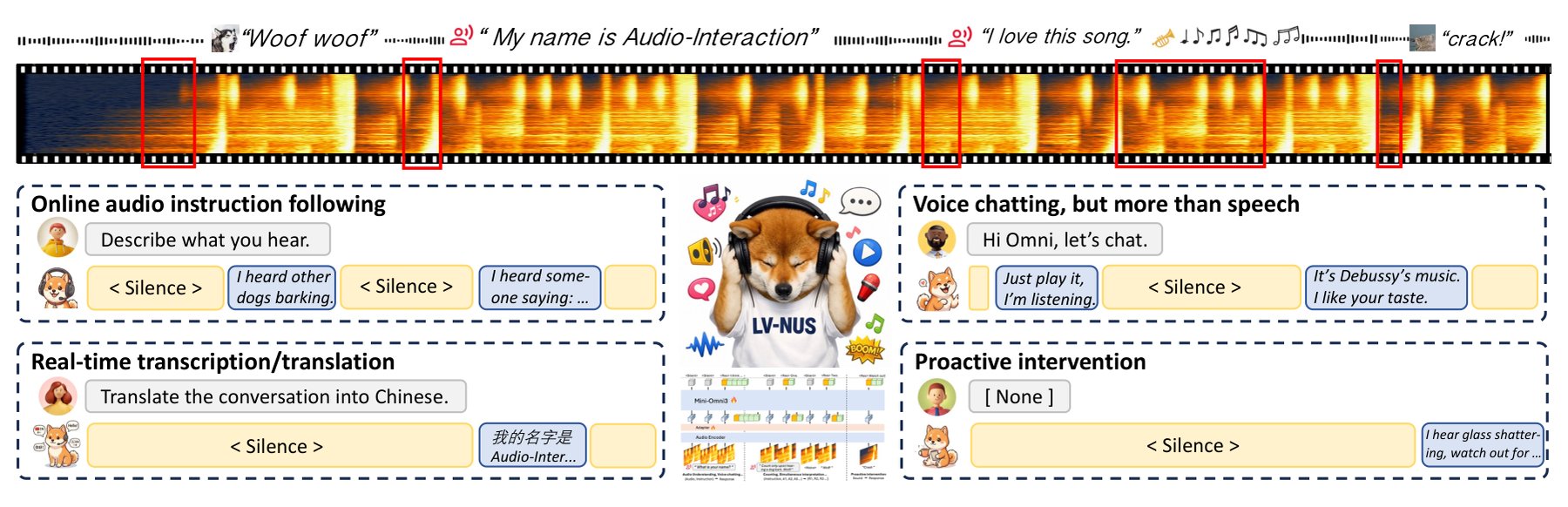
“By breaking the audio stream into atomic 0.4-second chunks, we move away from traditional 'turn-taking' AI and toward a model that can finally coexist with human conversation flows.”
— Zhifei Xie, Lead Researcher
One Model Replaces Many
Current streaming systems like Moshi for dialogue or Paraformer for live subtitles can listen in real-time, but they only handle one task. They also treat sounds like coughing as background noise to ignore.
Audio Interaction combines recognition, translation, dialogue, and proactive response in a single setup. The model scored 58.15 points on the MMAU audio benchmark, narrowly beating its base model Qwen2.5-Omni-3B. It also comes close to much larger 7B models on several tasks.
On English-Chinese translation, the model shows substantial improvement over the base. In proactive noise detection tests, it beat Gemini 3 Flash.
Training Data: 302,000 Hours of Synthetic Audio
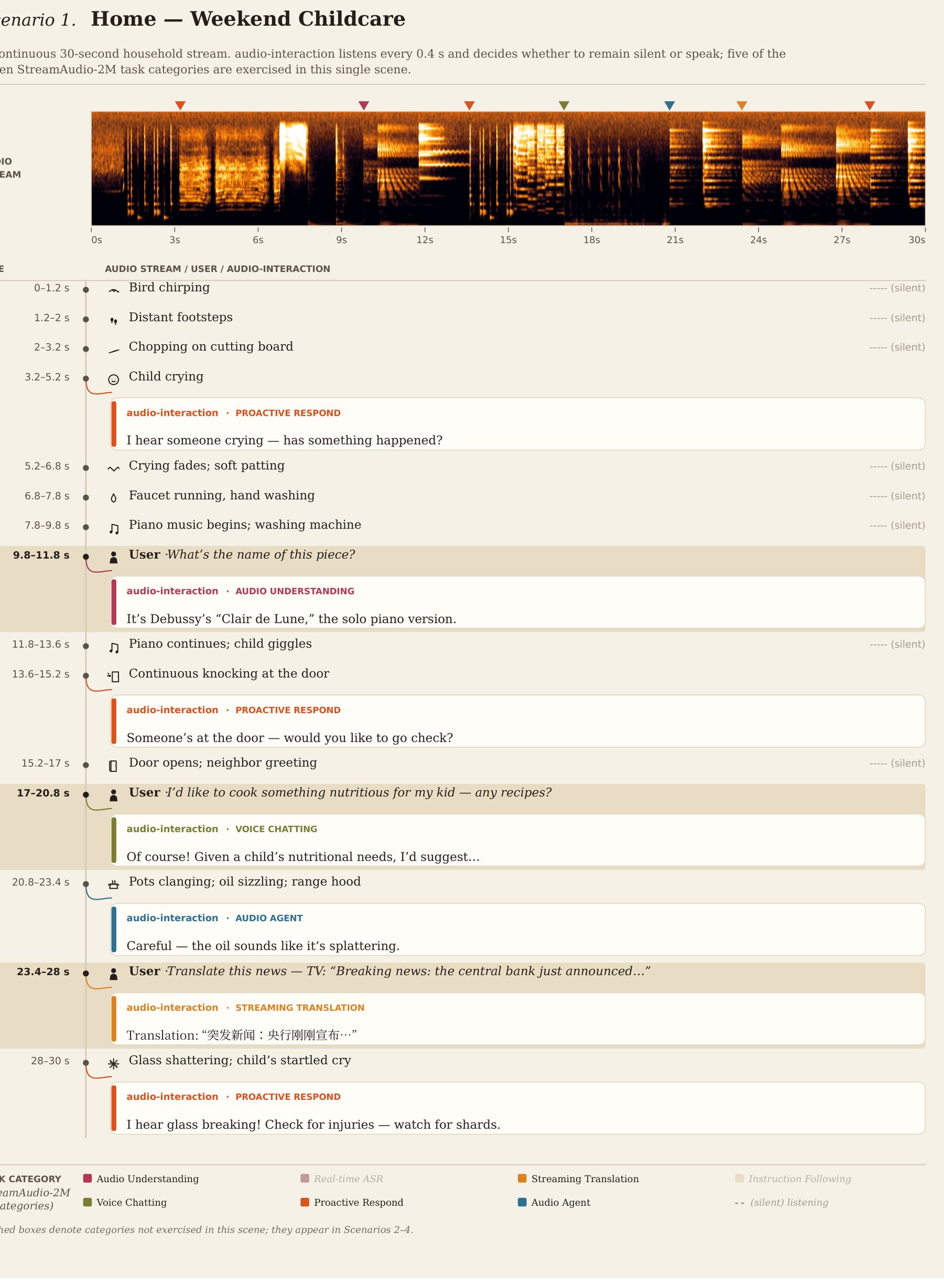
Teaching a model when to jump into a conversation requires specific training data. Existing audio datasets consist of short, isolated clips. They lack the long sequences with sparse response signals that Audio Interaction needs.
The research team built their own training data in three stages. First, a language model designed plausible settings, like a 30-second household scene. The team then generated 302,000 hours of synthetic audio to train the model's perceive-decide-respond loop.
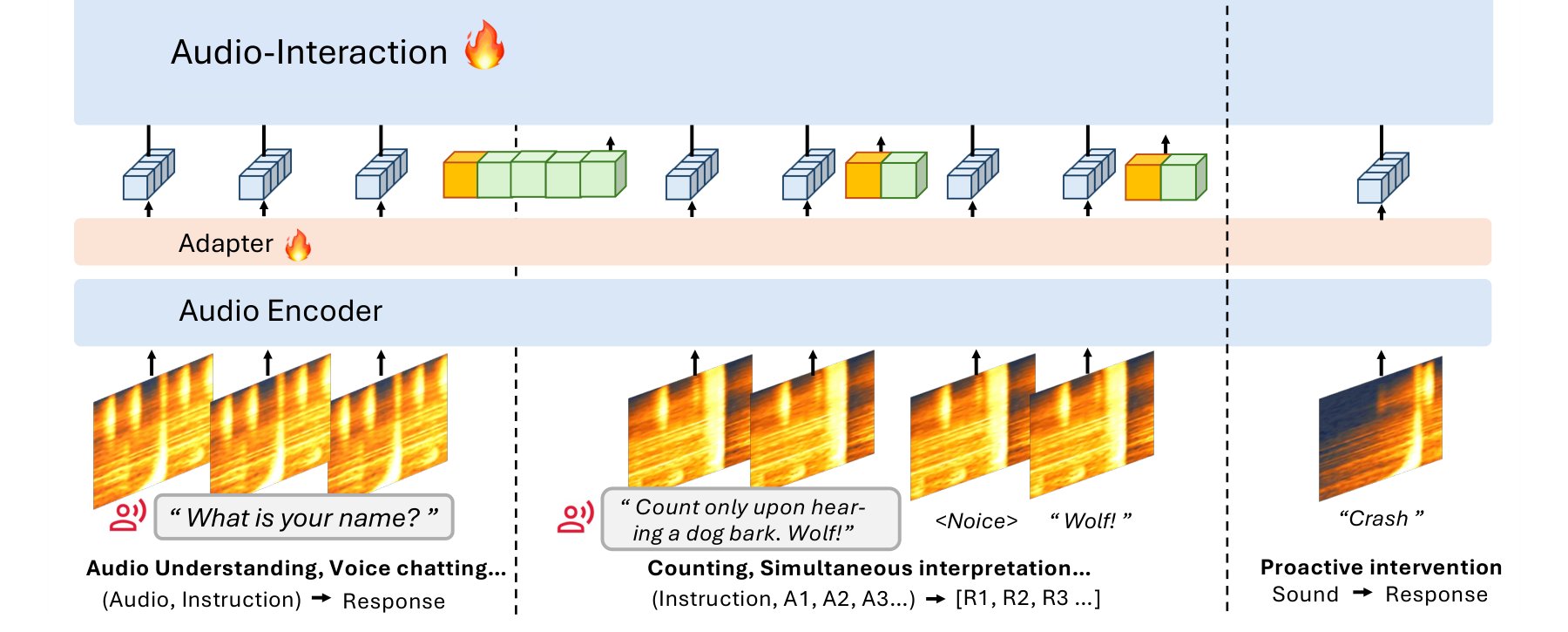
The architecture, called SoundFlow, uses an audio encoder, adapter, and model working together. This design lets the system process listening and speaking in parallel, minimizing the wait time for responses.
Open Source Under Apache 2.0
The model is released under an Apache 2.0 license. This has generated excitement in developer communities, particularly on Hacker News and Reddit's r/LocalLLaMA. The permissive license means developers can use it in commercial applications.
Some developers are already working on integrating Audio Interaction into open-source home automation projects. The SoundFlow architecture is designed to run on consumer-grade hardware, not just cloud infrastructure.
“This isn't just a chatbot that talks back; it's a model that understands the silence between words as much as the words themselves.”
— AI Research Analyst, The Decoder
There's debate about performance in highly noisy backgrounds. Some users report that proprietary models like Gemini 3 still handle certain edge cases better. But for an open-source model that developers can run locally, Audio Interaction represents a significant step forward.
Why This Matters for Voice Applications
For years, voice AI has forced users into unnatural patterns. Push-to-talk. Wait for the beep. Speak clearly into the microphone. These constraints exist because models needed discrete audio segments to process.
Audio Interaction's always-on loop mimics how humans actually converse. We decide constantly whether to interject, acknowledge with a "mm-hmm," or stay quiet. Making this work in a lightweight model that runs locally opens new possibilities for real-time voice agents.
Developers building voice interfaces no longer need to rely entirely on massive cloud APIs. A 3-billion-parameter model that handles multiple tasks gives them a foundation to build responsive, full-duplex voice applications.
Logicity's Take
Frequently Asked Questions
What makes Audio Interaction different from GPT-4o voice?
GPT-4o waits for you to finish speaking before responding. Audio Interaction listens continuously and decides every 0.4 seconds whether to speak, enabling more natural back-and-forth conversation.
Can Audio Interaction run on consumer hardware?
Yes. The 3-billion-parameter model is designed for local deployment on consumer-grade hardware, not just cloud infrastructure.
What tasks can Audio Interaction handle?
It combines dialogue, translation, transcription, and sound recognition in a single model. Previous systems needed separate models for each task.
Is Audio Interaction free to use commercially?
Yes. The model is released under an Apache 2.0 license, which permits commercial use.
How does Audio Interaction compare to Gemini 3 Flash?
Audio Interaction beat Gemini 3 Flash in proactive noise detection tests. However, some users report Gemini 3 still handles highly noisy backgrounds better in certain scenarios.
Need Help Implementing This?
Source: The Decoder / Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
Related Articles
Browse allZuckerberg's Superintelligence Lab Faces Setback
The first AI model from Zuckerberg's superintelligence lab has failed to impress compared to its rivals, sparking concerns about the lab's direction. We take a closer look at what happened and why it matters.

Muse Spark Launch Propels Meta AI App to Top 5
The recent launch of Muse Spark has significantly boosted the popularity of Meta AI app, pushing it into the top 5. We explore what this means for the AI landscape.

Meta's Muse Spark AI Model Lags Behind ChatGPT and Claude
Meta's Muse Spark AI model still can't outperform ChatGPT and Claude in key areas, despite its advancements. We explore what this means for the AI landscape.

Meta Launches Muse Spark AI To Challenge ChatGPT
Meta launches Muse Spark AI to challenge ChatGPT and Claude, we explore what this means for the AI landscape. Muse Spark AI is a significant development in the AI chatbot space.
Also Read

Nvidia RTX 3050 Ti Desktop Prototype Surfaces in Leaked Photos
An engineering sample of a desktop GeForce RTX 3050 Ti has appeared online, revealing a cancelled Ampere GPU that would have slotted between the RTX 3050 and RTX 3060. Hardware leaker Gok shared photos and benchmarks of the prototype, which Nvidia apparently shelved during the pandemic-era GPU shortage.

3 Hulu Shows to Stream This Weekend: June 5-7 Picks
Hulu's June 5-7 weekend lineup brings Mindy Kaling's Gen Z workplace comedy 'Not Suitable for Work,' the fifth season of 'Welcome to Wrexham,' and the critically acclaimed return of 'Deli Boys.' Here's what to watch and why each show deserves your time.

xAI Trained on Claude Outputs for Months Before Anthropic Cut Access
Elon Musk's xAI spent months distilling Anthropic's Claude to train its Grok coding models, according to The Information. After Anthropic revoked official API access in January, xAI engineers continued through personal accounts and third-party services. The company now rents its massive GPU infrastructure to Anthropic and Google instead of training frontier models.