Key Takeaways
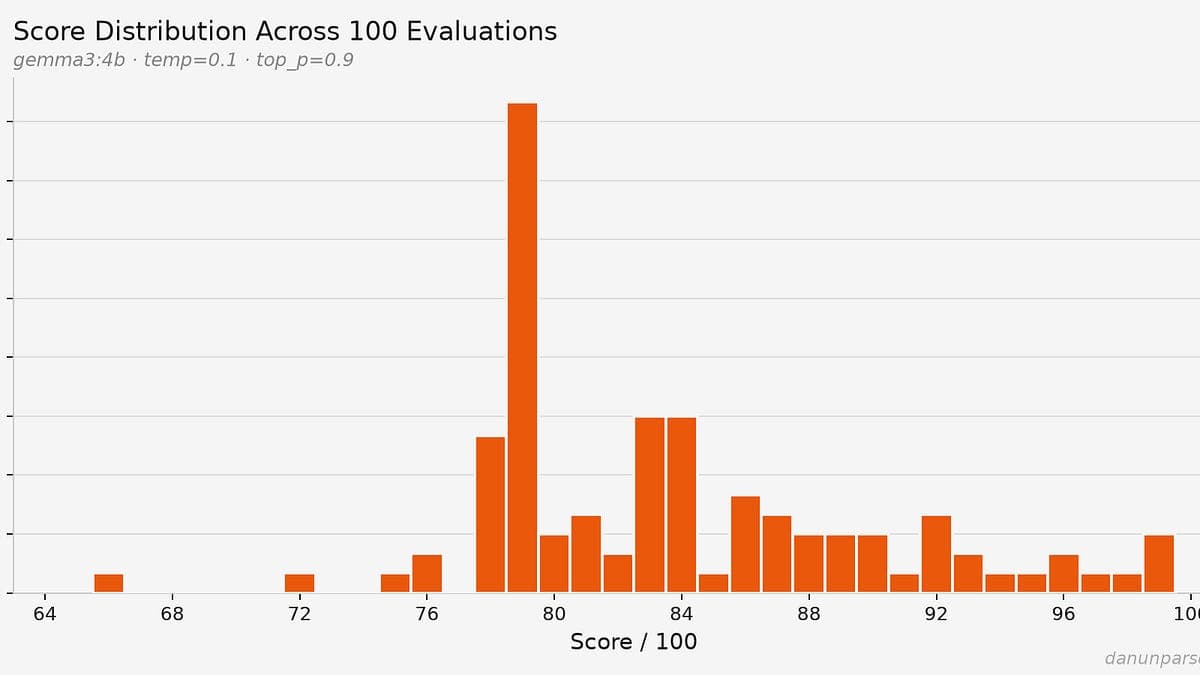
- The same resume scored anywhere from 66 to 99 out of 100 across 100 identical runs
- At an 85-point cutoff, a qualified candidate would fail 65% of the time purely due to LLM variance
- Technical skills scoring was consistent (98/100 runs at 8/10), but project evaluation varied wildly
HackerRank's open-source AI hiring agent has a consistency problem. Developer Dan Kinsky ran his resume through the tool 100 times, changed nothing between runs, and got scores ranging from 66 to 99. If a company sets its cutoff at 85, he fails 65% of the time. Not because of his qualifications. Because of luck.
The project, hosted at github.com/interviewstreet/hiring-agent, has blown up on LinkedIn and Reddit over the past few weeks. It promises to automate resume screening using LLMs. Parse a PDF, extract structured data, grade candidates on a 100-point scale with bonus points. The default model is gemma3:4b running at temperature 0.1, which should nudge outputs toward consistency.
It doesn't.
How does the scoring system actually work?
The tool parses your resume PDF into text, then calls an LLM six times to extract your basics, work history, education, skills, projects, and awards. It pulls your GitHub profile, scans your top repos, and appends them as context. Everything feeds into one final LLM call for grading.
The scoring breakdown: 35 points for open source contributions, 30 for personal projects, 25 for work experience, 10 for technical skills, plus up to 20 bonus points for startup experience, portfolios, or technical blogs.
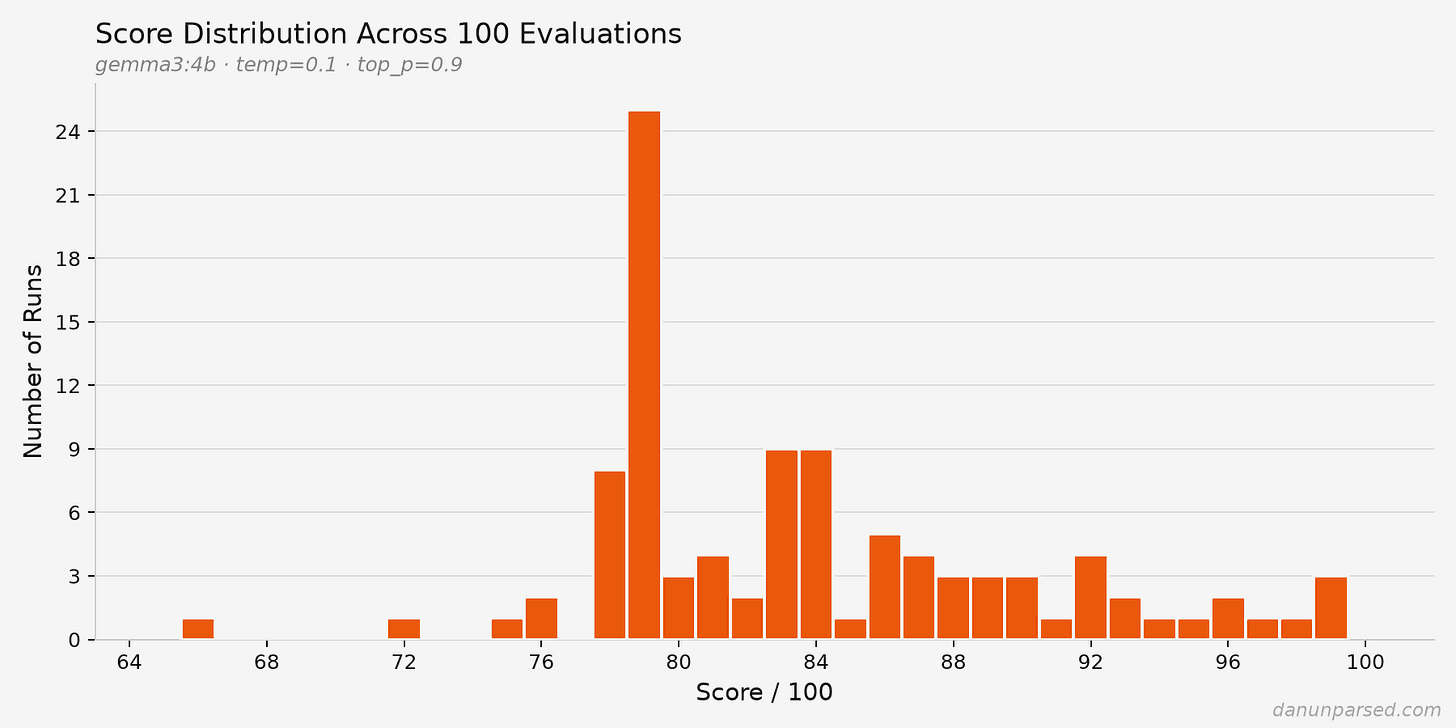
That weighting matters. Open source and projects account for 65% of the base score. A principal engineer with a decade of distributed systems experience but no public GitHub presence loses over half their potential score before any human sees their application.
Which categories are consistent and which are noise?
Kinsky broke down the variance by category, and the results explain why LLM grading falls apart for subjective evaluation.
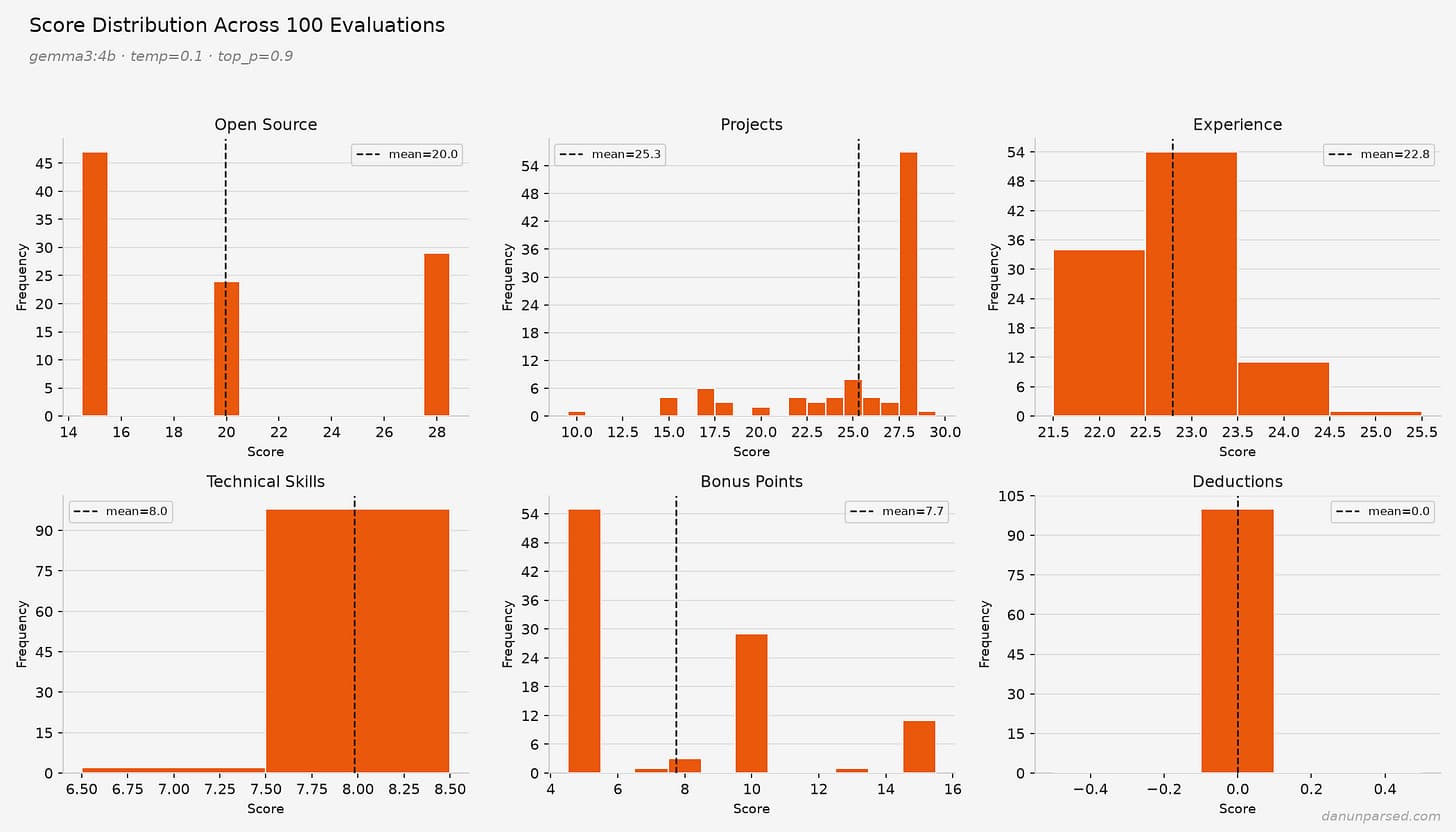
Technical skills: 8/10 in 98 out of 100 runs. Near-perfect consistency. Why? Because it's a checklist. You either know React or you don't. A five-year-old could match keywords to requirements.
Projects: all over the place. Sometimes Kinsky's projects "lack architectural complexity." Sometimes they "demonstrate real-world deployment." The LLM's judgment call is a coin flip.
Experience: 25/25 every single run. Sounds good until you realize a junior engineer with one internship also scores 25/25. The prompt is two lines long with no rubric, no examples, no anchors for what earns 15 versus 25. Consistent, but meaningless.
Does lowering temperature fix the randomness?
No. Temperature 0.1 is already low, supposedly nudging the model toward deterministic outputs. Someone opened a GitHub issue back in October showing scores of 27, 34, 32, 34, 34, 30 across six consecutive runs at temperature 0.
Kinsky tested with Google's Gemini, which produced a tighter distribution. Scores clustered between 48 and 64. But if your cutoff is 60, you still fail 28% of the time through no fault of your own.
This isn't a bug you can fine-tune away. It's a fundamental design flaw. LLMs are probabilistic. Asking them to assign a precise numerical score to something as ambiguous as "project quality" produces outputs that vary with the random seed, the tokenization, and the model's internal state.
What can LLMs actually do well in hiring?
Parsing. Extraction. Matching keywords. Use an LLM to convert a messy PDF into structured JSON with name, email, work history, skills. It's good at that. Use it to check whether someone lists Python on their resume. Also fine.
Use it to judge whether a candidate's experience is worth 18 points or 24 points? You get a vibe check. HR teams, bar raisers, and a dozen other corporate initiatives have spent decades trying to remove exactly this kind of subjectivity from hiring decisions.
The 65% problem for engineering leaders
If you're an engineering manager or CTO with any say in resume screening, these numbers should concern you. A tool that can't differentiate isn't filtering for quality. It's just filtering. You might as well throw out half the resumes and tell applicants you don't hire people with bad luck.
The 65% weighting on open source and projects creates its own bias. Some of the best engineers have built things that never ended up on GitHub. Proprietary systems. Internal tools. Classified projects. That's over half their score gone before screening even begins.
Logicity's Take
The appeal of AI resume screening is obvious: companies receive 250+ applications per opening, and 75% of Fortune 500s already use some ATS. But there's a difference between using LLMs for parsing (where they excel) and using them for judgment calls (where they add randomness). If you're evaluating tools in this space, look for systems that use AI for extraction and structured matching, not numerical scoring of subjective criteria. Platforms like [HubSpot](https://logicity.in/r/hubspot) or [Salesforce](https://logicity.in/r/salesforce) integrate with hiring workflows but leave evaluation to humans. For automation that stays deterministic, [Zapier](https://logicity.in/r/zapier) and [Make](https://logicity.in/r/make) can route candidates based on binary criteria without pretending to score their potential.
Disclosure
Some links in this post are affiliate links — Logicity earns a commission if you sign up, at no extra cost to you. We only link products we have used or actively recommend.
Frequently Asked Questions
Is HackerRank's ATS tool actually open source?
Yes. The hiring-agent project is available on GitHub under the interviewstreet organization. You can run it locally with your own LLM or connect to cloud models like Gemini.
Why do LLM-based resume scores vary so much?
LLMs are probabilistic. Even at low temperature settings, they produce slightly different outputs on each run. For objective tasks like parsing, this doesn't matter. For subjective scoring, it creates randomness that can determine whether a candidate passes or fails.
What percentage of resumes do ATS systems typically reject?
Industry estimates suggest 75% of resumes are rejected before human review. AI-powered tools can increase throughput but may introduce new sources of variance if they rely on LLM judgment calls.
Should companies use AI for resume screening?
AI works well for parsing resumes into structured data and matching keywords to requirements. It's less reliable for scoring subjective qualities like project impact or experience depth, where the same input can produce wildly different outputs.
Need Help Implementing This?
Building hiring automation that actually works requires separating what AI does well (parsing, matching) from what it doesn't (subjective scoring). If you're evaluating ATS tools or building internal screening workflows, reach out to Logicity for guidance on implementation that won't randomly reject your best candidates.
Source: Hacker News: Best / Dan Kinsky
Manaal Khan
Tech & Innovation Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






