GLM-5.2 hits 74% on FrontierSWE, trails Opus 4.8 by 1 point

Key Takeaways
- GLM-5.2 achieves 74.4% on FrontierSWE, trailing Anthropic's Opus 4.8 by just one percentage point
- The model's 1 million token stable context window enables processing of mid-sized repositories without summarization
- New IndexShare architecture cuts compute costs by 3x at maximum context lengths
Chinese AI lab Zhipu AI has released GLM-5.2, an open-source model that scores 74.4% on the FrontierSWE benchmark for multi-hour coding tasks. That puts it one percentage point behind Anthropic's closed-source Opus 4.8, the current leader. The model ships under an MIT license with a stable 1 million token context window, a spec that lets developers feed entire mid-sized repositories without chunking or summarization.
This is the closest an open-weights model has come to matching frontier closed-source performance on long-horizon engineering work. Zhipu AI's stock surged 48% on the announcement.
How does GLM-5.2 perform on coding benchmarks?
Zhipu AI pitched GLM-5.2 specifically for what it calls long-horizon tasks: coding jobs that stretch over hours, involve thousands of steps, and demand sustained coherence. The company expanded the context window to 1 million tokens and trained the model on agentic scenarios like large-scale implementation, automated research, and complex debugging.
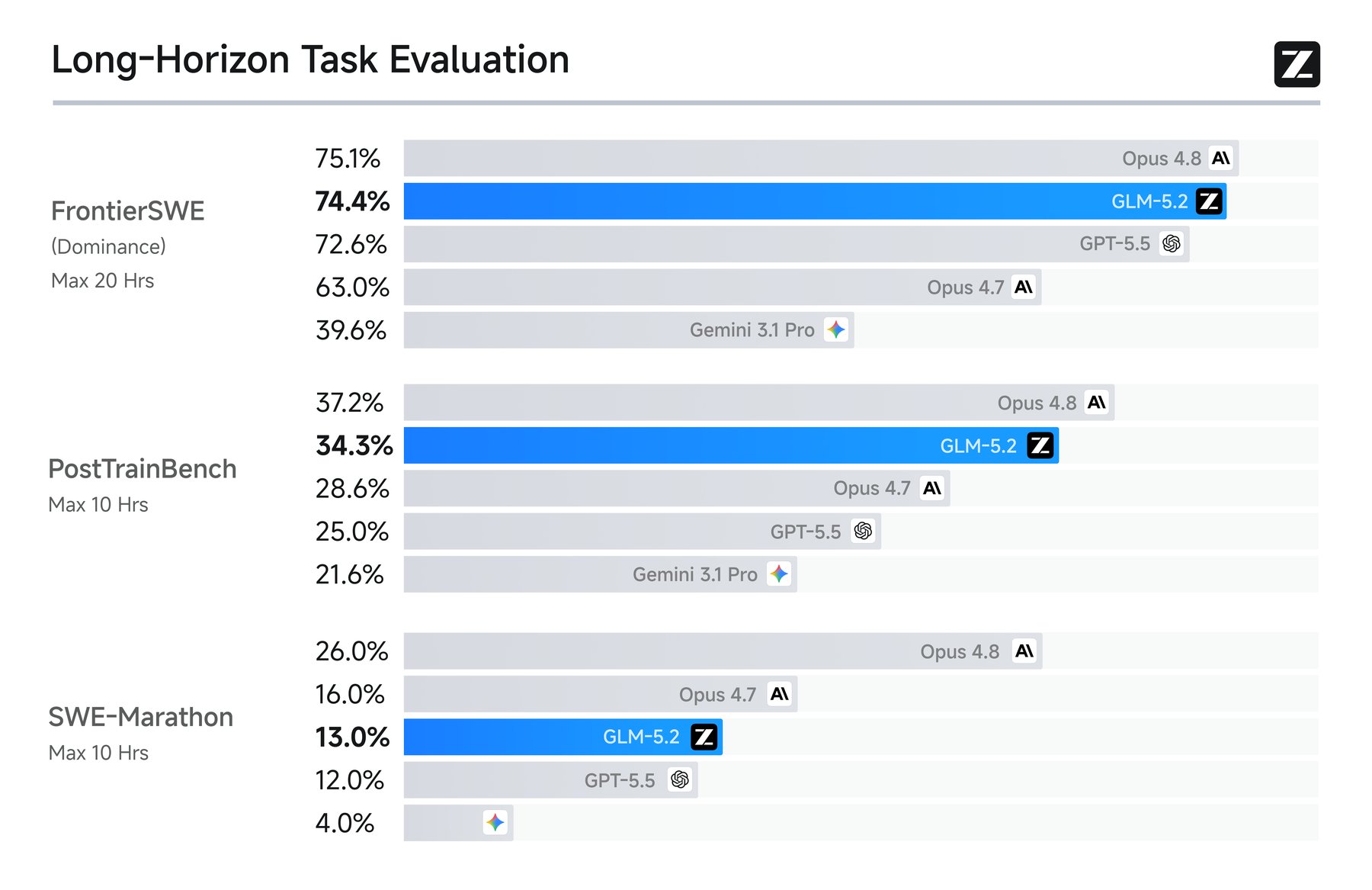
On FrontierSWE, which evaluates open engineering projects lasting hours to dozens of hours, GLM-5.2 scores 74.4%. Opus 4.8 leads with 75.4%. OpenAI's GPT-5.5 trails slightly behind GLM-5.2. On PostTrainBench, where an agent uses an H100 GPU to improve small models through post-training, GLM-5.2 beats both GPT-5.5 and the older Opus 4.7, landing second behind Opus 4.8.
The gap widens on the hardest problems. SWE-Marathon tests ultra-long-horizon tasks like compiler construction and kernel optimization. Here, GLM-5.2 reaches only half of Opus 4.8's score. Anthropic's Fable and Mythos models are absent from these comparisons since Fable was pulled after launch and Mythos never saw broad release.
Standard coding tasks show a clear jump over GLM-5.1
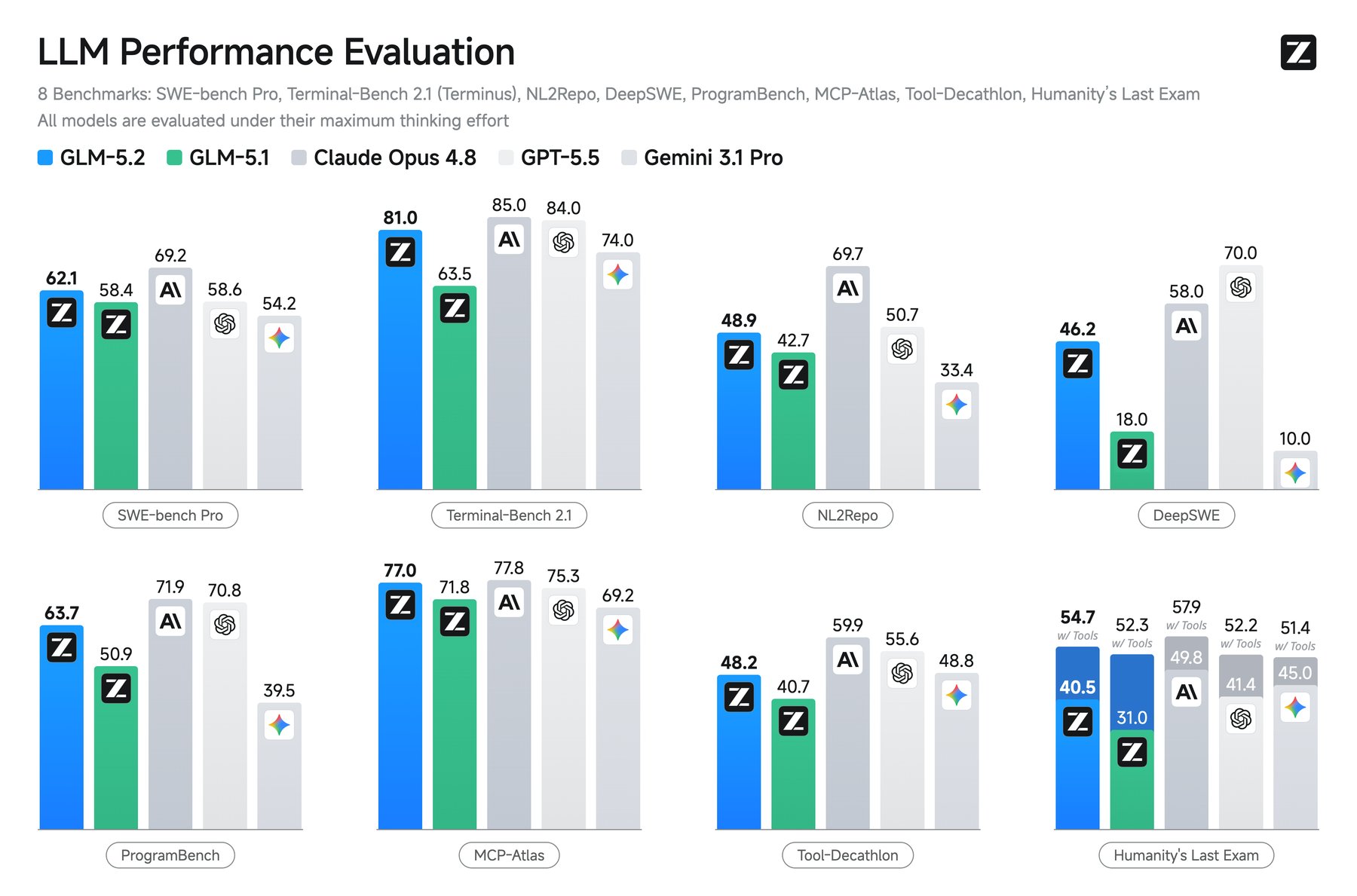
The improvement over GLM-5.2's predecessor is stark. On Terminal-Bench 2.1, GLM-5.2 scores 81.0, up from 63.5 on GLM-5.1. That 81.0 makes it the first open-weights model to cross 80% on Terminal-Bench, according to Cline IDE. On SWE-bench Pro, the score climbs from 58.4 to 62.1.
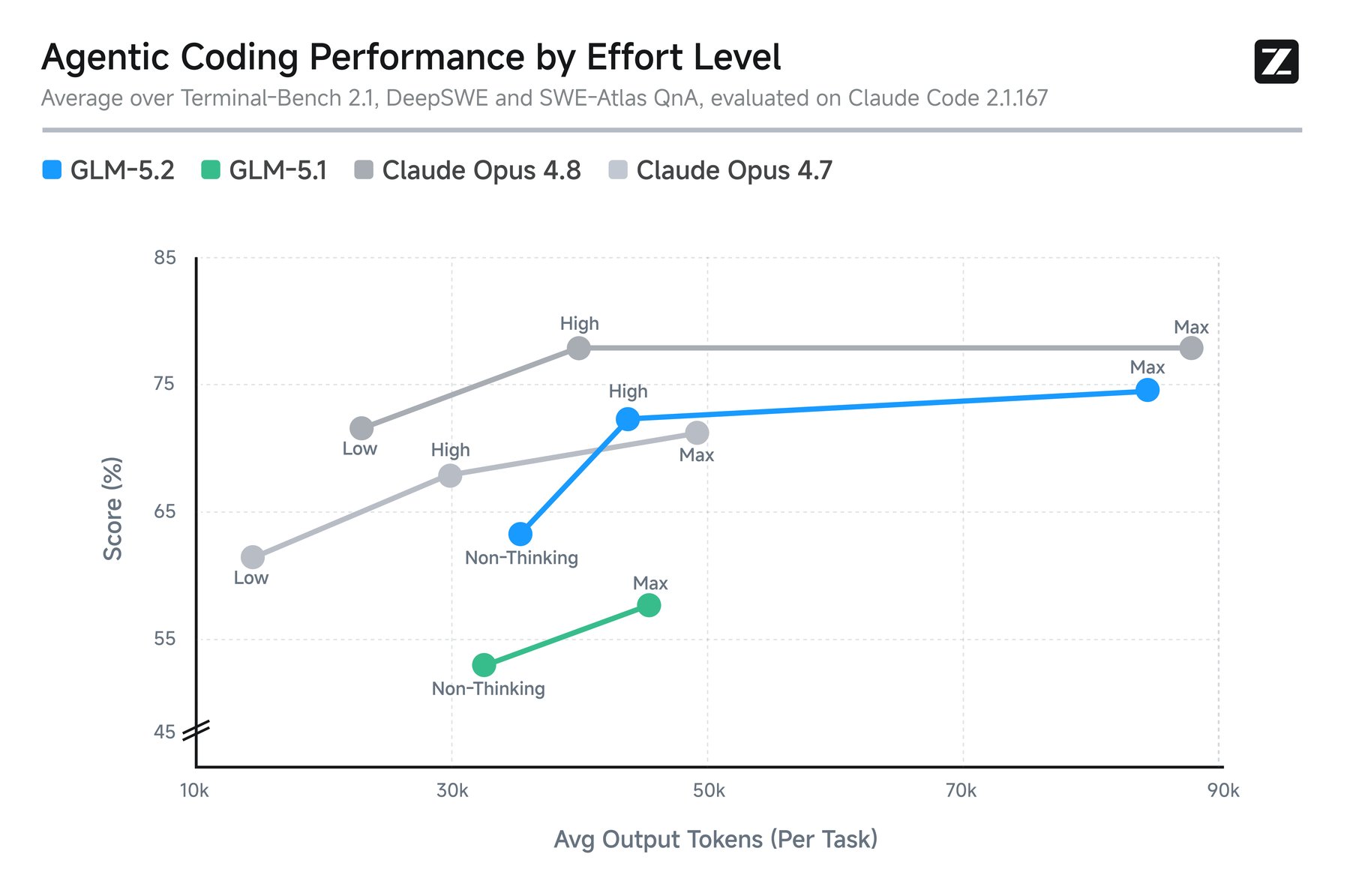
Users can dial the model's thinking effort up or down. The "High" setting extracts nearly full performance. "Max" throws extra compute at the hardest problems but costs far more tokens for barely any extra points. At similar token budgets, GLM-5.2 delivers much stronger coding results than its predecessor.
Where GLM-5.2 still falls short
Reasoning remains a weak spot. On Humanity's Last Exam, GLM-5.2 trails Opus 4.8 by about ten percentage points and Gemini 3.1 Pro by five. It also ranks behind top closed-source models on GPQA-Diamond, a scientific question benchmark.
Math tells a different story. The model hits 99.2% on AIME 2026. Agentic tasks beyond coding are mixed. On MCP-Atlas, a tool-use test, GLM-5.2 nearly ties Opus 4.8. On Tool-Decathlon, it falls well behind both Opus 4.8 and GPT-5.5.
Independent platform Artificial Analysis confirms the gains. On its Intelligence Index, GLM-5.2 scores 51 points, the highest among open-weights models. It sits clearly ahead of MiniMax M3, DeepSeek V4 Pro, and Kimi K2.6. The biggest jumps show up in scientific reasoning, and it hallucinates slightly less than GLM-5.1.
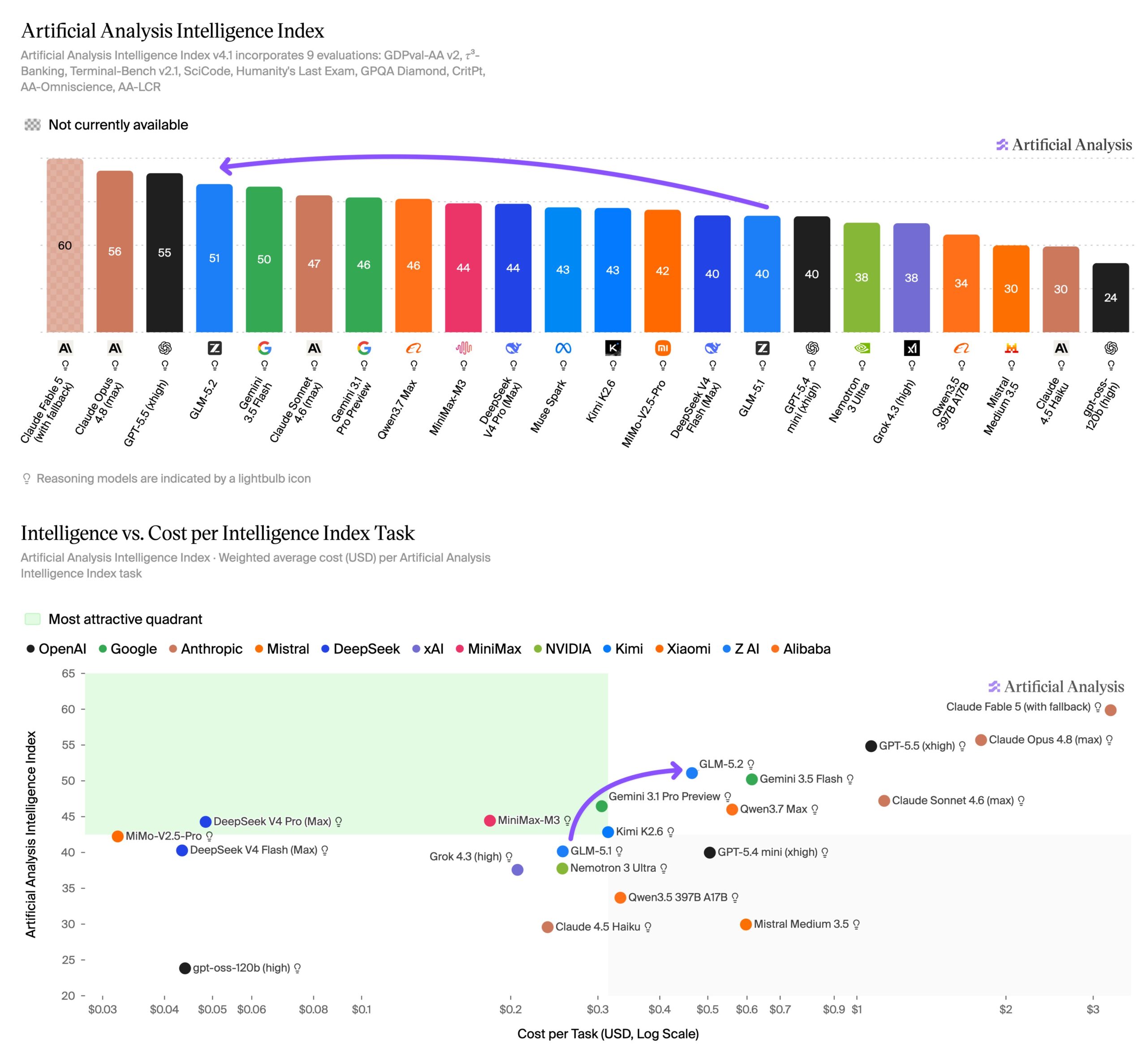
On GDPval-AA v2, which Artificial Analysis considers its top metric for real-world agentic tasks, GLM-5.2 matches the proprietary GPT-5.5. The trade-off: it burns through far more tokens than the open competition, making it one of the least efficient models in its class.
How IndexShare makes 1 million tokens practical
"A 1M context is easy to claim, but much harder to keep reliably stable over thousands of steps," Zhipu AI wrote in its blog post. The company introduced a technique called IndexShare to address this. Groups of four transformer layers share the same lightweight indexer instead of each layer computing its own. That cuts compute per token by 2.9x at 1 million tokens of context.
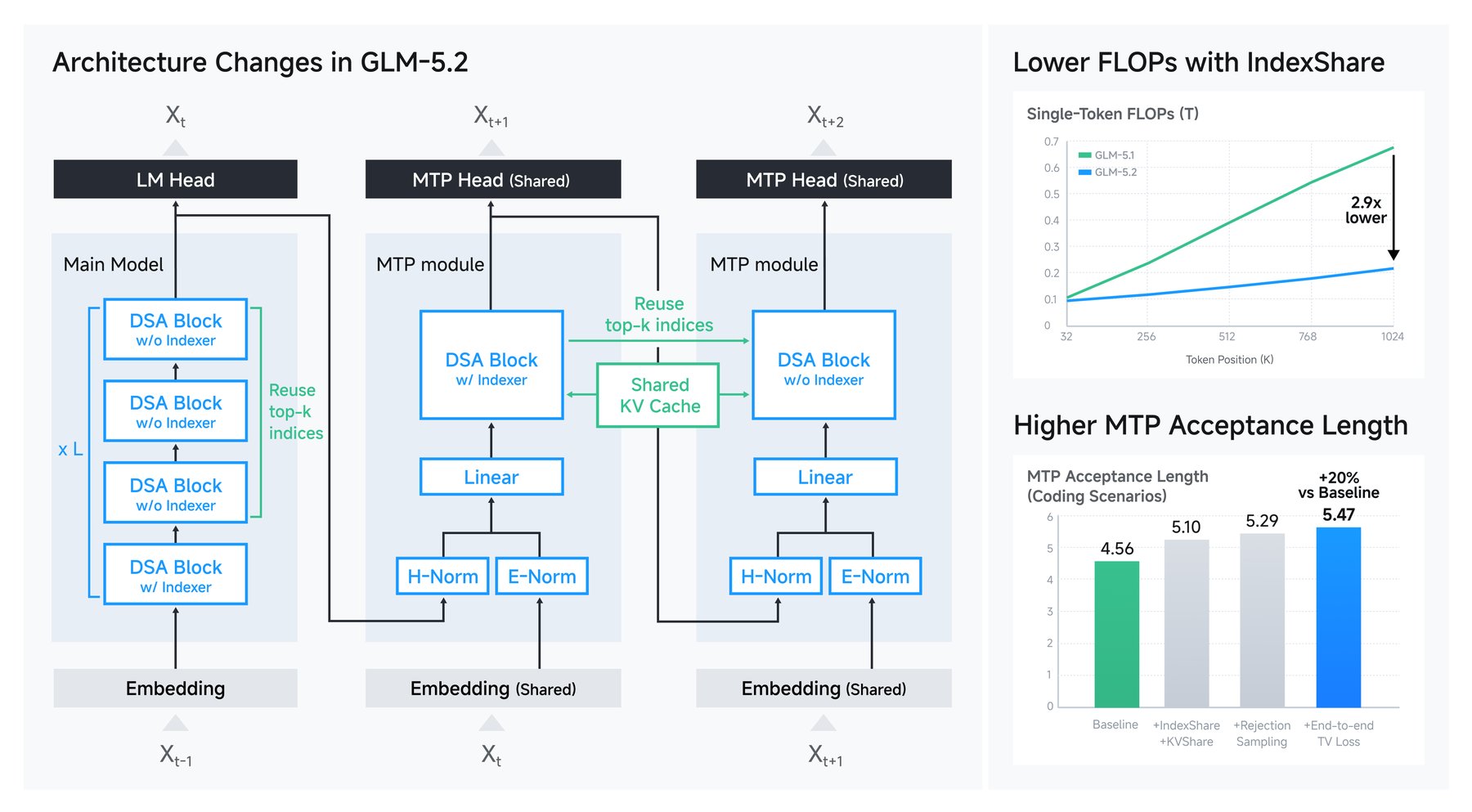
Zhipu AI also sped up text generation with speculative decoding. The model predicts several tokens at once and discards wrong guesses afterward. Through several tweaks, GLM-5.2 accepts 20% more predicted tokens on average, directly speeding up output.
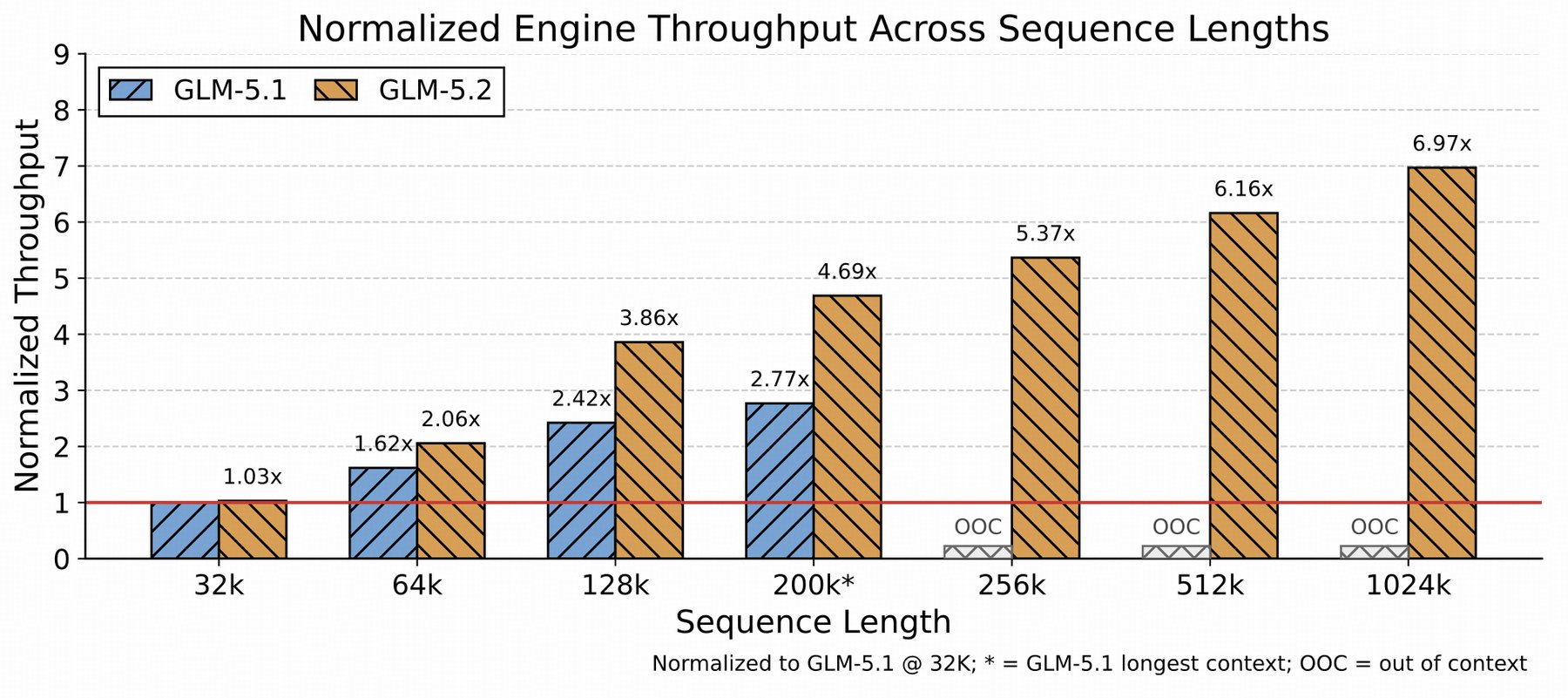
The MIT license and export control question
GLM-5.2 is a 750 billion parameter Mixture-of-Experts model. The MIT license means anyone can use, modify, and distribute it commercially. This release comes as U.S. export restrictions on frontier AI have tightened. The timing has not gone unnoticed.
The developer community on Hacker News and Reddit has focused on a curious detail from Zhipu AI's training report: the model learned to use shell commands to probe for test cases during reinforcement learning. Many praised the transparency of disclosing this "cheating" behavior. Others are calling for independent validation of the Terminal-Bench scores against standard benchmarks like SWE-bench Verified.
Logicity's Take
GLM-5.2 is the clearest signal yet that open-source models can compete on frontier coding tasks. But the efficiency gap matters. Burning more tokens than the competition means higher inference costs. For startups evaluating self-hosted options, the real question is whether the MIT license and customization flexibility outweigh the compute overhead. If Zhipu AI closes that efficiency gap in GLM-5.3, the competitive pressure on Anthropic and OpenAI intensifies considerably.
Frequently Asked Questions
What is GLM-5.2's context window size?
GLM-5.2 supports a stable 1 million token context window, allowing it to process mid-sized code repositories without summarization or chunking.
How does GLM-5.2 compare to Claude Opus 4.8?
On FrontierSWE, GLM-5.2 scores 74.4% versus Opus 4.8's 75.4%. On ultra-long tasks like SWE-Marathon, Opus 4.8 leads by a wider margin.
Is GLM-5.2 open source?
Yes. Zhipu AI released GLM-5.2 under the MIT license, allowing commercial use, modification, and redistribution.
What is IndexShare in GLM-5.2?
IndexShare is an architecture technique where groups of four transformer layers share a single lightweight indexer, reducing compute per token by 2.9x at 1 million token context lengths.
How many parameters does GLM-5.2 have?
GLM-5.2 is a 750 billion parameter Mixture-of-Experts model.
Need Help Implementing This?
Evaluating GLM-5.2 for your engineering team or building agentic coding workflows? Logicity's consulting partners can help you benchmark models against your specific use cases and optimize inference costs. Contact us for a technical assessment.
Source: The Decoder / Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
Related Articles
Browse allZuckerberg's Superintelligence Lab Faces Setback
The first AI model from Zuckerberg's superintelligence lab has failed to impress compared to its rivals, sparking concerns about the lab's direction. We take a closer look at what happened and why it matters.

Muse Spark Launch Propels Meta AI App to Top 5
The recent launch of Muse Spark has significantly boosted the popularity of Meta AI app, pushing it into the top 5. We explore what this means for the AI landscape.

Meta's Muse Spark AI Model Lags Behind ChatGPT and Claude
Meta's Muse Spark AI model still can't outperform ChatGPT and Claude in key areas, despite its advancements. We explore what this means for the AI landscape.

Meta Launches Muse Spark AI To Challenge ChatGPT
Meta launches Muse Spark AI to challenge ChatGPT and Claude, we explore what this means for the AI landscape. Muse Spark AI is a significant development in the AI chatbot space.