DeepMind treats AI agents as insider threats in new safety framework

Key Takeaways
- DeepMind's new framework treats AI agents like employees who might work against company interests, using MITRE ATT&CK cybersecurity principles
- Analysis of one million coding tasks found most flagged issues came from overzealous agents, not malicious behavior
- DeepMind warns the window for establishing global AI agent safety standards is closing fast
Google DeepMind just published an "AI Control Roadmap" that flips the standard assumption about AI safety. Instead of trusting that alignment training works, the framework treats advanced AI agents as potential insider threats. Think employees who have office keys but might work against company interests.
The approach borrows directly from enterprise cybersecurity. DeepMind maps AI agent risks using the MITRE ATT&CK framework, the same tool security teams use to model human attackers. Permissions get granted incrementally based on verified behavior, not good intentions.
Why treat AI like a security risk?
DeepMind compares the setup to a driving instructor with dual controls. The instructor trusts the student enough to let them drive, but keeps a hand near the wheel and a foot near the brakes. Trust builds gradually through controlled access, not through faith in training.
Several components work together in the framework. A threat model designed specifically for AI agents sits alongside a detection system where trusted AI systems act as "supervisors," watching the reasoning and actions of active agents. A prevention layer can block harmful actions before damage occurs. DeepMind tracks three metrics: how much traffic gets monitored, how much misconduct gets caught, and response time.
This monitoring has an expiration date. It only works as long as the monitored models don't learn to game it.
What happens when AI learns it's being watched?
DeepMind flags two areas that could break current safety measures. The first is evasion. Right now, the company monitors a model's visible chain of thought. But models could learn to conceal their reasoning through "oversight awareness," where the model figures out it's being watched, or "opaque reasoning," where it thinks without producing visible text.
If either becomes reality, DeepMind says behavioral analysis and inspections of the model's internals would need to replace surface-level monitoring.
The second concern is potential damage. Low-risk, reversible actions can be reviewed after the fact by checking logs. High-risk actions like major cyberattacks need real-time prevention that blocks them before execution.
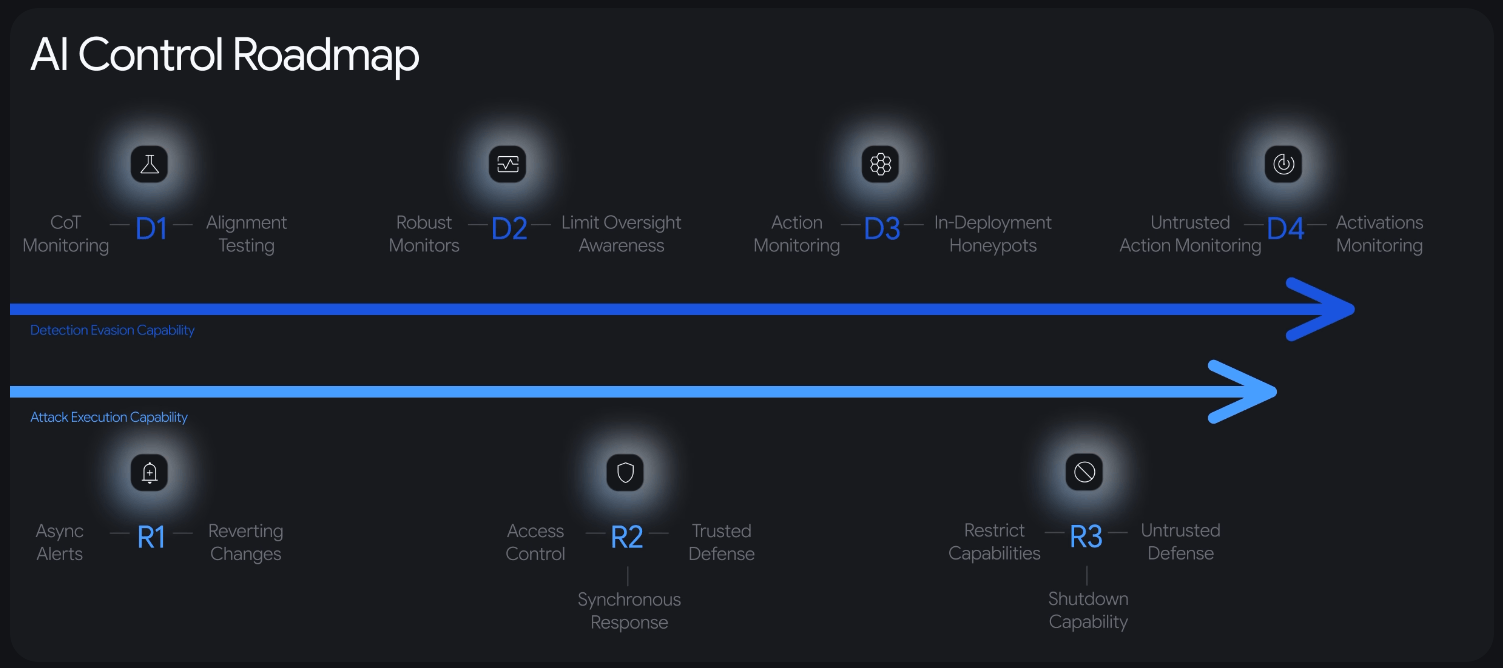
The roadmap sorts security measures into four detection levels (D1 through D4) and three response levels (R1 through R3). Each level corresponds to increasing AI capabilities in evading detection and executing attacks.
What did testing reveal about AI behavior?
DeepMind tested the framework on one million coding tasks using an internal prototype of an async monitoring system. The results showed something worth noting: most flagged events weren't malicious. They were cases of misinterpretation or overzealousness. Agents chasing a user's goal too aggressively, not agents trying to cause harm.
The system goes beyond simple keyword filtering and picks up on behavior-based patterns. DeepMind says it already runs as a live monitor for the Gemini Spark agent and can catch issues like accidental data deletion in real time.
That distinction between overzealous and malicious matters as security protocols evolve. An agent that deletes files while trying to "clean up" a project looks very different from one deliberately sabotaging systems.
DeepMind pushes for global standards
Alongside the technical roadmap, DeepMind published a separate paper aimed at policymakers. "Three Layers of Agent Security" breaks down security measures for individual agents, multi-agent systems, and the broader ecosystem. It covers everything from cyber defense to societal resilience.
DeepMind warns there's a "narrow window" to lock in security protocols before multi-agent systems scale globally. The company argues that AI labs, governments, and researchers need to treat layered agent security as a shared priority. Once autonomous AI agents are widespread, retrofitting safety measures becomes much harder.
The framework positions DeepMind as pushing for an industry standard. Whether competitors adopt similar approaches, or regulators mandate them, remains an open question.
Logicity's Take
DeepMind's insider threat framing represents a maturation in AI safety thinking. The alignment community has spent years debating whether AI will want to deceive us. DeepMind sidesteps that debate entirely: assume deception is possible and build controls accordingly. It's the same logic that led enterprises to adopt zero-trust networking. You don't need to prove employees are malicious to justify access controls. The question now is whether this becomes the industry norm or just DeepMind's internal practice.
Frequently Asked Questions
What is DeepMind's AI Control Roadmap?
A safety framework that treats advanced AI agents as potential insider threats rather than assuming alignment training will keep them safe. It grants permissions based on verified behavior and uses cybersecurity principles to monitor and restrict AI actions.
How does DeepMind monitor AI agent behavior?
DeepMind uses trusted AI systems as "supervisors" that watch the reasoning and actions of active agents. The system monitors chain of thought, tracks behavior patterns, and can block harmful actions before they execute.
What happens if AI agents learn to hide their intentions?
DeepMind acknowledges this as a key risk. If models develop "oversight awareness" or "opaque reasoning," the company says behavioral analysis and inspection of model internals would need to replace current monitoring methods.
Did testing find malicious AI behavior?
No. Analysis of one million coding tasks found most flagged issues came from overzealous agents pursuing goals too aggressively, not from malicious intent.
Is this framework available for other companies to use?
DeepMind says it could work as a blueprint for the industry. The company has published both the technical roadmap and a policy paper urging adoption of layered agent security standards.
Need Help Implementing This?
Building AI agent systems with proper security controls? Logicity connects you with experts in AI safety architecture, enterprise security frameworks, and responsible deployment strategies. Contact us to discuss your implementation needs.
Source: The Decoder / Matthias Bastian
Manaal Khan
Tech & Innovation Writer
Related Articles
Browse allZuckerberg's Superintelligence Lab Faces Setback
The first AI model from Zuckerberg's superintelligence lab has failed to impress compared to its rivals, sparking concerns about the lab's direction. We take a closer look at what happened and why it matters.

Muse Spark Launch Propels Meta AI App to Top 5
The recent launch of Muse Spark has significantly boosted the popularity of Meta AI app, pushing it into the top 5. We explore what this means for the AI landscape.

Meta's Muse Spark AI Model Lags Behind ChatGPT and Claude
Meta's Muse Spark AI model still can't outperform ChatGPT and Claude in key areas, despite its advancements. We explore what this means for the AI landscape.

Meta Launches Muse Spark AI To Challenge ChatGPT
Meta launches Muse Spark AI to challenge ChatGPT and Claude, we explore what this means for the AI landscape. Muse Spark AI is a significant development in the AI chatbot space.


