AI solves just 3% of real knowledge work tasks in new benchmark

Key Takeaways
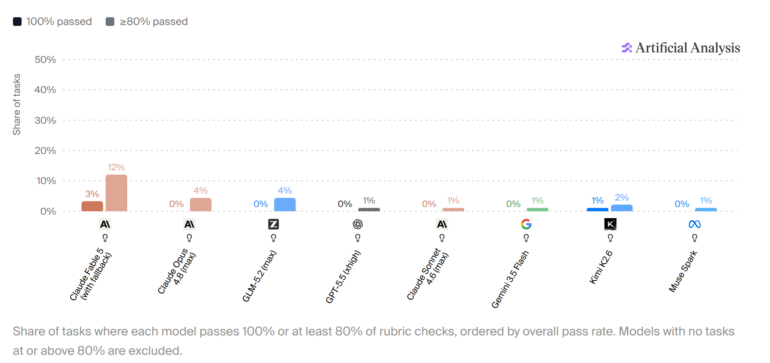
- Claude Fable 5 leads the AA-Briefcase benchmark but fully solves only 3% of 91 knowledge work tasks
- On 31 of 91 tasks, no AI model cleared even 50% of the rubric criteria
- Per-task costs range 800x, from $0.04 for DeepSeek V4 Flash to over $31 for Claude Fable 5
The best AI model available today fully completes just 3% of realistic workplace tasks. That's the headline finding from AA-Briefcase, a new benchmark from Artificial Analysis that tests AI against the kind of fragmented, multi-source work that defines most knowledge jobs.
Anthropic's Claude Fable 5 topped the benchmark's rubric pass rate. It still failed to nail every criterion on 97% of tasks. On 31 out of 91 total tasks, no model from any vendor cleared even half the requirements.
What makes this AI benchmark different?
Most AI benchmarks test clean, isolated questions. AA-Briefcase does not. It throws models into multi-week simulated projects built from thousands of fragmented source files: Slack threads, email chains, meeting transcripts, large data exports. The messiness is the point.
This design mirrors actual knowledge work. A consultant synthesizing information from client calls and scattered documents. A product manager piecing together feature requests from support tickets and user interviews. A financial analyst pulling numbers from quarterly reports and internal memos. The task isn't answering a question; it's finding the question buried across twenty sources.
The benchmark's 91 tasks span different types of knowledge work. Each task has a rubric with multiple criteria, and models receive scores based on how many criteria they satisfy. Full completion means hitting every requirement.
Why stronger AI models fail differently
The benchmark reveals a pattern in how models break down. Weaker models fail loudly. They miss relevant files entirely or produce outputs that don't work at all. Basic execution problems.
Stronger models fail quietly. Claude Fable 5 and its peers hit the obvious requirements. They deliver something usable. But they miss the details you'd only catch by cross-referencing information scattered across multiple sources. A deadline mentioned in a Slack thread three weeks ago. A budget constraint buried in an email attachment. A stakeholder preference noted in meeting notes from a different project.
This failure mode is more dangerous for enterprises. A model that produces nothing gets caught immediately. A model that produces 80% of the right answer looks reliable until that missing 20% causes a problem.
The 800x cost gap
Performance isn't the only variable. Per-task costs range from about $0.04 for DeepSeek V4 Flash to over $31 for Claude Fable 5. That's an 800x spread.
For enterprises deploying AI assistants at scale, the math gets complicated fast. Claude Fable 5 completes more tasks fully, but at what cost per incremental success? If you're running thousands of knowledge work tasks daily, that $31 per task adds up. DeepSeek V4 Flash fails more often but costs almost nothing.
The benchmark doesn't publish exact scores for mid-tier models, so direct cost-effectiveness comparisons remain limited. But the spread suggests that model selection should depend heavily on task value. High-stakes analysis might justify Claude Fable 5's price. Routine summarization probably doesn't.
What this means for AI deployment
AA-Briefcase arrives as enterprises accelerate AI adoption for knowledge work. Consulting firms, financial services companies, and tech startups are all deploying AI assistants for research, analysis, and documentation. The benchmark suggests most are overestimating what these tools can handle autonomously.
The 3% full completion rate doesn't mean AI is useless for knowledge work. Partial completion still delivers value. A model that hits 70% of requirements saves time even if it misses details. But the benchmark indicates that AI works best as an assistant that drafts and surfaces information, not as an autonomous worker that handles projects end-to-end.
The failure patterns also point toward where improvement is needed. Current models struggle with information retrieval across fragmented sources. They don't maintain context well over long, multi-step projects. They miss implicit requirements that humans would infer from organizational context.
Who is Artificial Analysis?
Artificial Analysis has built a reputation for independent, rigorous AI model evaluations. The firm runs performance benchmarks comparing response quality, latency, and pricing across major AI providers. Their work is widely cited in enterprise AI procurement decisions.
AA-Briefcase represents a shift in their methodology. Previous benchmarks focused on isolated tasks. This one attempts to capture the full complexity of real workplace scenarios. The result is a more realistic picture of AI capabilities, and that picture is not flattering.
Logicity's Take
This benchmark will likely become a standard reference for enterprise AI buyers, and it should. The 3% figure sounds damning, but the real insight is subtler: AI failure modes shift as models improve. Enterprises aren't at risk from models that obviously fail. They're at risk from models that look competent until a missed detail causes real damage. The smart play isn't abandoning AI for knowledge work. It's building review processes that catch the 20% of requirements current models miss.
Frequently Asked Questions
What is the AA-Briefcase benchmark?
AA-Briefcase is an AI evaluation from Artificial Analysis that tests models on multi-week knowledge work projects using fragmented sources like Slack threads, emails, and meeting transcripts. It measures how well AI handles realistic workplace tasks.
Which AI model performed best on the benchmark?
Anthropic's Claude Fable 5 achieved the highest rubric pass rate, but still fully completed only 3% of the 91 tasks in the benchmark.
Why do AI models struggle with knowledge work?
Models fail to synthesize information scattered across multiple fragmented sources. Stronger models miss subtle details that require cross-referencing documents, while weaker models fail at basic execution like finding relevant files.
How much does it cost to run AI on these tasks?
Per-task costs range from approximately $0.04 for DeepSeek V4 Flash to over $31 for Claude Fable 5, an 800x spread that significantly impacts enterprise deployment economics.
Should enterprises stop using AI for knowledge work?
No, but the benchmark suggests AI works better as an assistant than an autonomous worker. Partial completion still saves time, but human review remains essential for catching missed requirements.
Need Help Implementing This?
Evaluating AI tools for your team's knowledge work? Logicity helps enterprises benchmark AI assistants against their actual workflows. Contact us for a custom assessment of which models fit your use cases and budget.
Source: The Decoder / Maximilian Schreiner
Manaal Khan
Tech & Innovation Writer
Related Articles
Browse allZuckerberg's Superintelligence Lab Faces Setback
The first AI model from Zuckerberg's superintelligence lab has failed to impress compared to its rivals, sparking concerns about the lab's direction. We take a closer look at what happened and why it matters.

Muse Spark Launch Propels Meta AI App to Top 5
The recent launch of Muse Spark has significantly boosted the popularity of Meta AI app, pushing it into the top 5. We explore what this means for the AI landscape.

Meta's Muse Spark AI Model Lags Behind ChatGPT and Claude
Meta's Muse Spark AI model still can't outperform ChatGPT and Claude in key areas, despite its advancements. We explore what this means for the AI landscape.

Meta Launches Muse Spark AI To Challenge ChatGPT
Meta launches Muse Spark AI to challenge ChatGPT and Claude, we explore what this means for the AI landscape. Muse Spark AI is a significant development in the AI chatbot space.


