أبرز النقاط
- Fugu Ultra يدّعي مطابقة أداء Fable 5 وMythos Preview في المعايير المرجعية، لكن المستخدمين الأوائل يشككون في ذلك
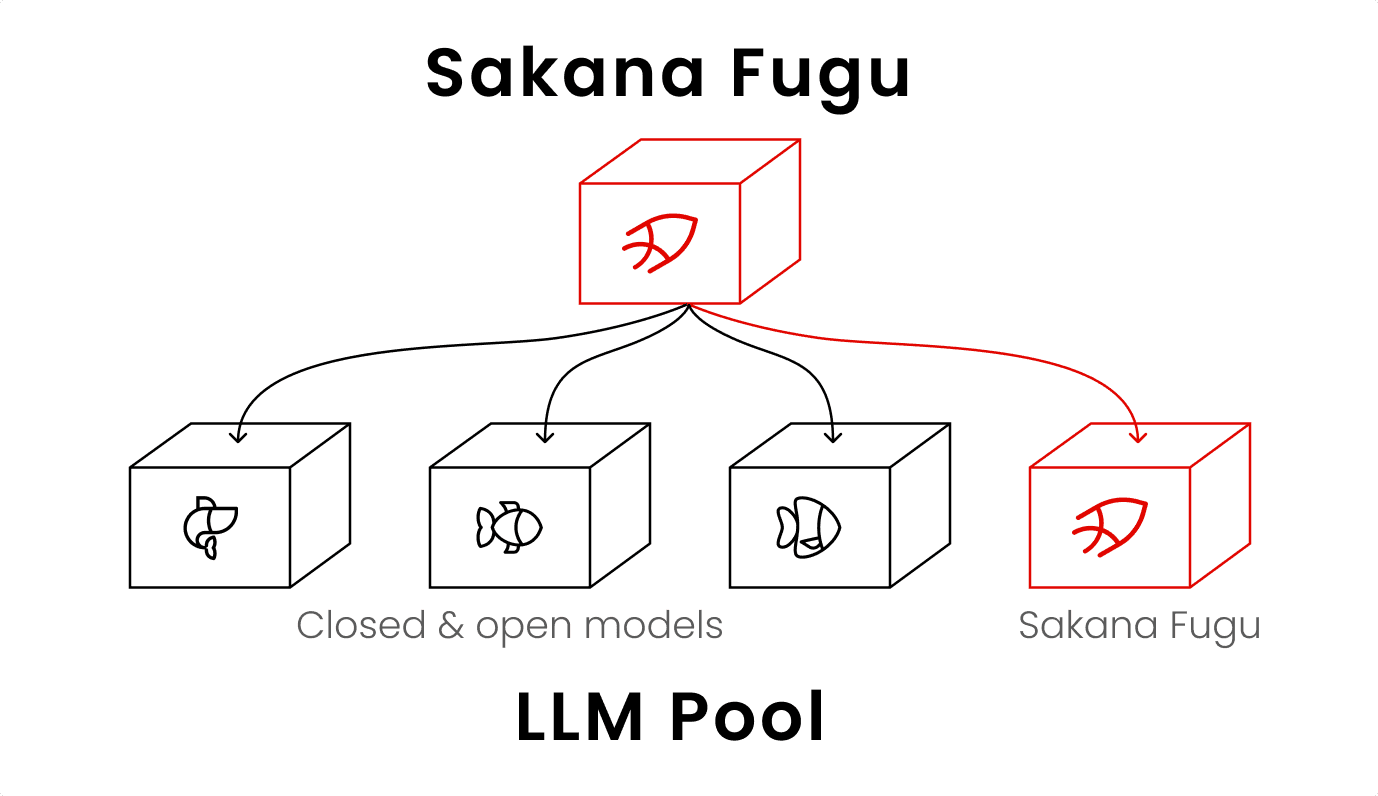
- النظام يعمل كمنسّق يستدعي نماذج متعددة ديناميكياً، مما يقلل الاعتماد على مزوّد واحد
- الاختبارات العملية تُظهر بطئاً ملحوظاً واستهلاكاً سريعاً للحصص، رغم تفوّق محدود في مراجعة الأكواد
أعلنت شركة Sakana AI اليابانية عن إطلاق نظام Fugu، وهو منسّق ذكي يجمع بين نماذج لغوية متعددة ويقدّمها للمستخدم وكأنها نموذج واحد متكامل. تدّعي الشركة أن الإصدار المتقدم Fugu Ultra يُضاهي في أدائه نموذجَي Fable 5 وMythos Preview من Anthropic، لكن الاختبارات الأولية من المستخدمين ترسم صورة مختلفة تماماً.
كيف يعمل Fugu كمنسّق للنماذج اللغوية؟
على عكس النماذج التقليدية التي تعتمد على بنية واحدة ضخمة، صمّمت Sakana AI نظام Fugu ليكون هو ذاته نموذجاً لغوياً مدرَّباً على استدعاء نماذج أخرى من مجموعة وكلاء تضم نسخاً منه ومن نماذج متخصصة. عند تلقّي طلب، يقرر Fugu إما معالجته بنفسه أو تشكيل فريق من النماذج المتخصصة، ثم يتولى داخلياً عمليات الاختيار والتفويض والتحقق والتوليف النهائي.
يصل المستخدمون إلى كل ذلك عبر واجهة برمجية واحدة متوافقة مع معيار OpenAI، مما يُبسّط الدمج في التطبيقات القائمة. هذه البنية تتيح للفرق التي لديها متطلبات خصوصية أو امتثال استبعاد وكلاء معيّنين من المجموعة.
ما الفرق بين Fugu وFugu Ultra؟
تطرح Sakana AI إصدارين: الإصدار الأساسي Fugu يستهدف زمن استجابة منخفضاً وأداءً يومياً متوازناً في البرمجة ومراجعة الأكواد والمحادثات. أما Fugu Ultra فمصمَّم لتحقيق أعلى جودة ممكنة في المهام المعقدة متعددة الخطوات، ويستخدمه المختبرون الأوائل في أبحاث الذكاء الاصطناعي وإعادة إنتاج الأوراق العلمية وتحليل الأمن السيبراني والبحث في براءات الاختراع.
ماذا تقول المعايير المرجعية؟
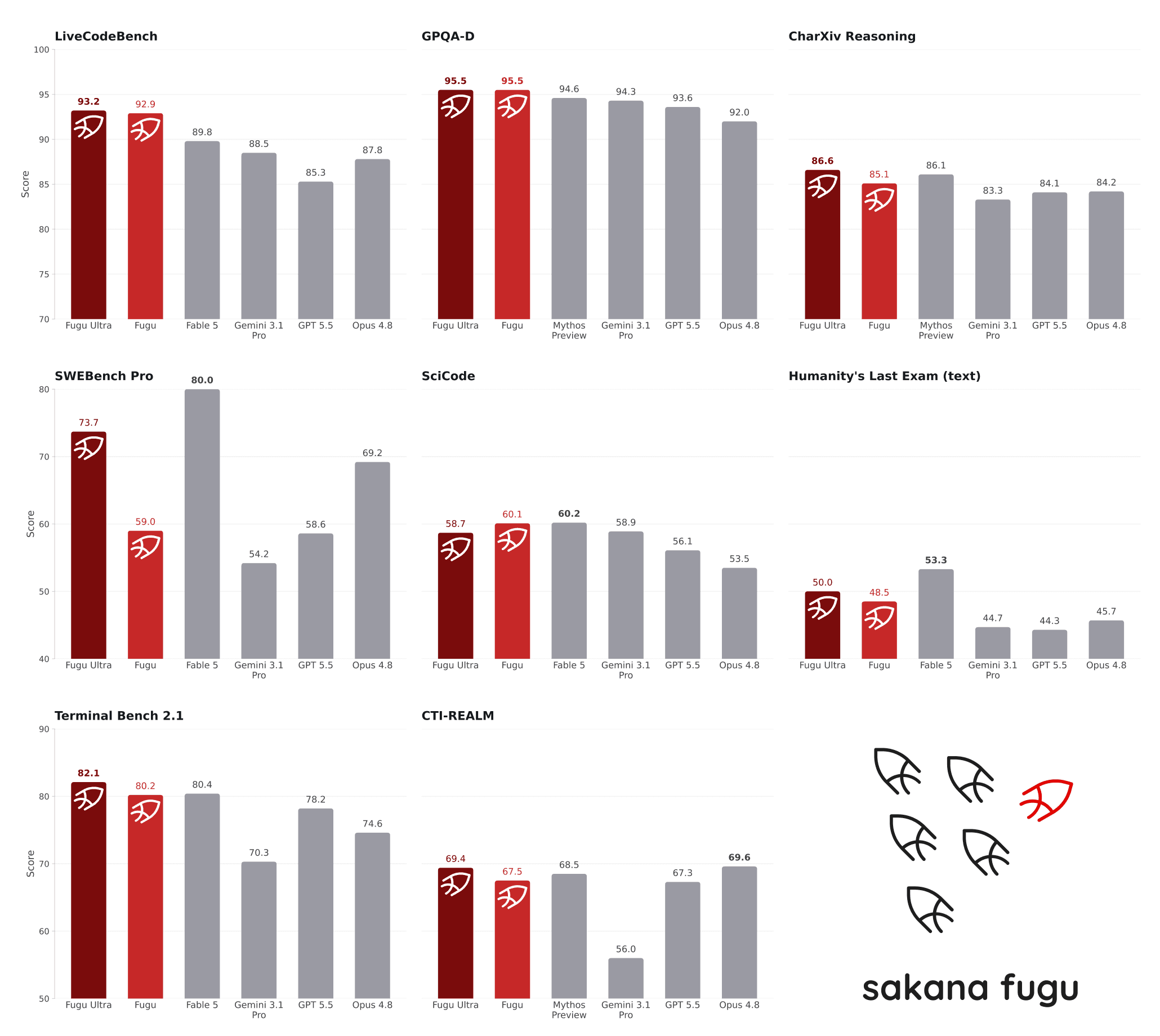
وفقاً للنتائج التي نشرتها Sakana AI، يتفوق Fugu Ultra أو يتساوى مع Fable 5 وMythos Preview في مجموعة من معايير البرمجة والاستدلال والعلوم والوكلاء. لكن ثمة تحفّظ جوهري: نموذجا Anthropic غير متاحَين للعموم، وبالتالي لم يُدرجا في مجموعة وكلاء Fugu. تقول Sakana إن أرقام المقارنة الأساسية مأخوذة من مزوّدي النماذج أنفسهم.
- SWE Bench Pro: Fugu Ultra 73.7% مقابل Opus 4.8 بنسبة 69.2%
- TerminalBench 2.1: Fugu Ultra 82.1% مقابل GPT 5.5 بنسبة 78.2%
- LiveCodeBench: Fugu Ultra 93.2% مقابل Gemini 3.1 Pro بنسبة 88.5%
- Humanity's Last Exam: Fugu Ultra 50.0% مقابل GPT 5.5 بنسبة 41.4%
لماذا يختلف المستخدمون مع هذه النتائج؟
الانطباعات الأولى من المختبرين الفعليين جاءت أقل حماساً بكثير. أشار الباحث في الذكاء الاصطناعي Ethan Mollick عبر منصة X إلى أن Fugu Ultra "بطيء بشكل لا يُصدّق"، حيث استغرقت اختباراته البرمجية المعتادة ثلاثين دقيقة، والنتائج كانت "مقبولة" لكنها أقل من Fable في التطبيق العملي.
أما المستخدم @LLMJunky فاستنفد حصته الكاملة البالغة خمس ساعات في خطة العشرين دولاراً بأمر واحد فقط. مهمة برمجية بـ ThreeJS جاءت "أسوأ بشكل ملحوظ من GPT 5.5" واحتاجت سبع أو ثماني جولات تصحيح قبل أن تعمل اللعبة أصلاً.
على منصة Hacker News، اشتكى مطورون من أن خطة المئتي دولار شهرياً تمنحك أقل من ثلاث ساعات أسبوعياً، مع بطء في الواجهة البرمجية وجودة إخراج بعيدة عن Fable.
هل هناك نقاط قوة حقيقية؟
رغم الانتقادات، برزت مراجعة الأكواد كنقطة مضيئة، حيث وصفها المختبرون بأنها تُضاهي تقريباً أداء Opus 4.8 أو GPT 5.5. أشار Hamel Husain عبر X إلى أن النظام قوي في مراجعة الأكواد لكنه أضعف في أعمال الواجهات الأمامية، واصفاً قدراته بأنها "متفاوتة بعض الشيء".
في مقارنة مباشرة أجراها المستخدم Mark Santos على استنساخ لعبة Crossy Road، أنهى Fugu Ultra المهمة في اثنتين وعشرين دقيقة بتكلفة 7.32 دولار، مقابل تسع وسبعين دقيقة و37.85 دولار لـ Opus 4.8. لكن Santos أعجبه الناتج النهائي أقل.
هل يحقق Fugu فعلاً الاستقلالية عن المزوّدين؟
تروّج Sakana AI لنظام Fugu كوسيلة للتحوّط ضد الاعتماد على مزوّد واحد، مستشهدةً بقيود التصدير الأخيرة على نموذجَي Fable وMythos من Anthropic كمثال ملموس. لكن هذا الادعاء واجه انتقادات: النظام يظل معتمداً على النماذج الموجودة في مجموعته، وSakana نفسها تستخدم نماذج مغلقة المصدر مثل Claude Opus في اختباراتها المرجعية.
ما تفعله Sakana هو تحسين هندسي ذكي يُعرف بـ "harness engineering" لاستخلاص أقصى أداء من النماذج المتاحة، وهو أسلوب راسخ في عالم الذكاء الاصطناعي الوكيلي، لكنه ليس ابتكاراً جذرياً.
ما سجل Sakana AI السابق؟
Sakana AI شركة ناشئة تأسست في طوكيو عام 2023 على يد David Ha وLlion Jones، وكلاهما باحثان سابقان في Google. جمعت الشركة تمويلاً بقيمة مئتي مليون دولار بتقييم يقارب ملياري دولار. فلسفتها تقوم على الذكاء الاصطناعي المستوحى من الطبيعة، باستخدام الخوارزميات التطورية وذكاء الأسراب.
قبل Fugu، حققت الشركة نتائج لافتة مع وكيلها ALE-Agent الذي احتل المرتبة الحادية والعشرين من بين ألف خبير بشري في مسابقة برمجية، مما يمنح ادعاءاتها الجديدة بعض المصداقية التقنية.
رأي Logicity
الفجوة بين المعايير المرجعية والأداء الفعلي لـ Fugu Ultra تعكس مشكلة متكررة في صناعة الذكاء الاصطناعي: الاختبارات المعيارية لا تُترجم دائماً إلى تجربة مستخدم حقيقية. للفرق التي تدرس بدائل، يبقى Claude Opus 4.8 خياراً موثوقاً للمهام البرمجية المعقدة (تسعير الوصول عبر API)، بينما يتفوق GPT 5.5 في بعض مهام الاستدلال الطويل. أما Fugu فقد يناسب من يريد تقليل الاعتماد على مزوّد واحد، بشرط تقبّل بطء الأداء وتكلفة الحصص العالية نسبياً.
الأسئلة الشائعة
ما هو Fugu من Sakana AI وكيف يختلف عن النماذج التقليدية؟
Fugu هو نظام تنسيق يستدعي نماذج لغوية متعددة ديناميكياً ويقدمها للمستخدم كنموذج واحد عبر API متوافق مع OpenAI، بدلاً من الاعتماد على بنية ضخمة واحدة.
كم تكلفة استخدام Fugu Ultra شهرياً؟
الخطة الأساسية تبدأ من 20 دولاراً مع حصة خمس ساعات، بينما الخطة المتقدمة بـ 200 دولار شهرياً تمنح أقل من ثلاث ساعات أسبوعياً وفقاً لتقارير المستخدمين.
هل Fugu Ultra أفضل من Claude Opus 4.8 فعلياً؟
المعايير المرجعية تُظهر تفوقاً في بعض الاختبارات، لكن المستخدمين الأوائل يشيرون إلى بطء ملحوظ وجودة إخراج أقل في المهام العملية مقارنة بـ Opus 4.8 وGPT 5.5.
هل يمكن لـ Fugu تحقيق الاستقلالية عن Anthropic وOpenAI؟
نظرياً نعم لأنه يدعم تبديل النماذج في مجموعة الوكلاء، لكن عملياً يظل معتمداً على النماذج المتاحة، وSakana نفسها تستخدم نماذج مغلقة المصدر في اختباراتها.
ما أفضل استخدام لـ Fugu حالياً بناءً على الاختبارات الأولية؟
مراجعة الأكواد تبدو نقطة القوة الرئيسية، حيث يُضاهي أداء Opus 4.8، بينما مهام الواجهات الأمامية والبرمجة السريعة أضعف.
هل تحتاج مساعدة في التطبيق؟
إذا كنت تبني تطبيقات تعتمد على نماذج لغوية متعددة أو تدرس استراتيجيات التحوّط ضد الاعتماد على مزوّد واحد، تواصل مع فريق Logicity للحصول على استشارة تقنية متخصصة.
فاطمة الزهراء
كاتبة تقنية متخصصة في الذكاء الاصطناعي
أُنتِج هذا المقال بمساعدة الذكاء الاصطناعي وراجعه فريق التحرير في لوجيسيتي. اعرف المزيد في سياسة التحرير.