معيار AA-Briefcase يكشف عجز الذكاء الاصطناعي عن إتمام سوى 3% من مهام العمل المعرفي

أبرز النقاط
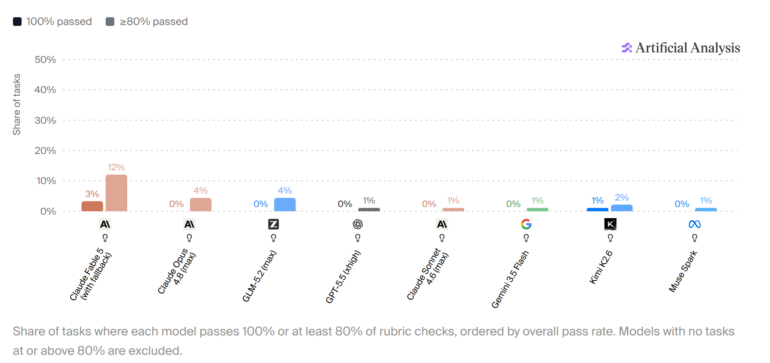
- أفضل نموذج ذكاء اصطناعي (Claude Fable 5) أتمّ 3% فقط من مهام العمل المعرفي الواقعية بالكامل
- في 31 مهمة من أصل 91، لم يتجاوز أي نموذج عتبة 50% من معايير التقييم
- فجوة التكلفة تتخطى 800 ضعف بين أرخص النماذج وأغلاها لكل مهمة
كشف معيار AA-Briefcase الذي أطلقته شركة Artificial Analysis عن فجوة صادمة بين الضجة المحيطة بالذكاء الاصطناعي وقدرته الفعلية على إنجاز العمل المعرفي الحقيقي: أفضل النماذج المتاحة اليوم تُتمّ 3% فقط من المهام بشكل كامل. هذه النتيجة تُعيد طرح السؤال الجوهري الذي يشغل صنّاع القرار في المؤسسات الخليجية وغيرها: هل الذكاء الاصطناعي جاهز فعلاً لتولّي مهام الموظفين المعرفيين؟
ما الذي يختلف في معيار AA-Briefcase عن الاختبارات التقليدية؟
تعتمد معظم معايير تقييم الذكاء الاصطناعي على أسئلة منفصلة ومُنظّمة، أشبه بامتحانات مدرسية. لكن AA-Briefcase يُحاكي بيئة العمل الفعلية بفوضاها المعتادة: مشاريع تمتد لأسابيع، ومصادر معلومات مُشتّتة عبر آلاف الملفات من محادثات Slack ورسائل بريد إلكتروني ومحاضر اجتماعات وتصدير بيانات ضخمة.
هذا التصميم يُجبر النماذج على فعل ما يفعله الموظف المعرفي يومياً: تجميع معلومات متناثرة، وربط سياقات مختلفة، واستخلاص استنتاجات تتطلب فهماً شاملاً لا مجرد استرجاع بيانات.
لماذا فشلت أقوى النماذج في ثلث المهام تماماً؟
من أصل 91 مهمة في المعيار، لم يتجاوز أي نموذج عتبة 50% من معايير النجاح في 31 مهمة. بمعنى آخر: ثُلث الاختبارات كان عصياً على جميع النماذج بشكل شبه كامل.
اللافت أن طبيعة الأخطاء تتغيّر مع تحسّن النماذج. النماذج الأضعف تفشل في الأساسيات: تتجاهل ملفات ذات صلة أو تُخرج نتائج غير قابلة للاستخدام. أما النماذج الأقوى مثل Claude Fable 5 فتفشل بصمت: تُلبّي المتطلبات الواضحة لكنها تُخطئ التفاصيل الدقيقة التي لا تتكشّف إلا بربط معلومات من مصادر متعددة.
- النماذج الضعيفة: أخطاء تنفيذية واضحة (ملفات مفقودة، مخرجات تالفة)
- النماذج القوية: أخطاء سياقية خفية (تفاصيل مُهملة تتطلب ربط مصادر متعددة)
- جميع النماذج: صعوبة في المهام التي تستلزم استدلالاً عبر وثائق متفرقة
كم تكلّف هذه النماذج لكل مهمة؟
الفجوة السعرية مذهلة: تتراوح التكلفة لكل مهمة بين 0.04 دولار تقريباً لنموذج DeepSeek V4 Flash، وأكثر من 31 دولاراً لنموذج Claude Fable 5. هذا يعني فارقاً يتجاوز 800 ضعف.
للمؤسسات التي تُخطط لنشر وكلاء ذكاء اصطناعي على نطاق واسع، هذه الأرقام تفرض حسابات دقيقة: النموذج الأفضل أداءً (وإن كان أداؤه متواضعاً) يكلّف مئات أضعاف البدائل الأرخص، مع ضمانات نجاح لا تتجاوز 3%.
ماذا يعني ذلك للمؤسسات الخليجية؟
تتسارع موجة تبنّي الذكاء الاصطناعي في مؤسسات الخليج ضمن مبادرات التحول الرقمي ورؤى التنويع الاقتصادي. لكن نتائج AA-Briefcase تُوجّه رسالة واضحة: الاعتماد الكامل على وكلاء الذكاء الاصطناعي في المهام المعرفية المعقدة لا يزال سابقاً لأوانه.
هذا لا يعني التوقف عن التجريب، بل يعني ضبط التوقعات: الذكاء الاصطناعي اليوم أداة مساعدة للموظف المعرفي، لا بديل عنه. المهام التي تتطلب تجميع سياقات متعددة واستدلالاً دقيقاً تحتاج إشرافاً بشرياً وثيقاً.
رأي Logicity
معيار AA-Briefcase يُقدّم خدمة جليلة للقطاع بكشفه الفجوة بين التسويق والواقع. النماذج تتحسّن سريعاً، لكن التحسّن في المهام المُنظّمة لا ينتقل تلقائياً إلى الفوضى الحقيقية لبيئات العمل. المؤسسات الذكية ستستثمر في بناء بنية بيانات أنظف —توثيق قرارات أوضح، أرشفة محادثات مُهيكلة— لتُسهّل على الذكاء الاصطناعي القادم فهم سياقاتها، بدلاً من انتظار نموذج سحري يفهم الفوضى.
الأسئلة الشائعة
ما هو معيار AA-Briefcase؟
معيار تقييم أطلقته Artificial Analysis يختبر نماذج الذكاء الاصطناعي على مشاريع معرفية واقعية تمتد لأسابيع، باستخدام آلاف الملفات المُشتّتة من محادثات ورسائل ومحاضر اجتماعات.
أي نموذج ذكاء اصطناعي حقق أفضل أداء؟
Claude Fable 5 من Anthropic تصدّر القائمة، لكنه أتمّ 3% فقط من المهام بالكامل وفق جميع معايير التقييم.
لماذا فشلت النماذج في ثلث المهام؟
المهام التي تتطلب ربط معلومات من مصادر متعددة واستدلالاً سياقياً معقداً أثبتت صعوبتها على جميع النماذج الحالية.
هل يعني ذلك أن الذكاء الاصطناعي غير مفيد للعمل المؤسسي؟
لا، لكنه يعني أن الذكاء الاصطناعي حالياً أداة مساعدة تحتاج إشرافاً بشرياً، وليس بديلاً مستقلاً للموظفين المعرفيين في المهام المعقدة.
هل تحتاج مساعدة في التطبيق؟
إذا كنت تُقيّم نشر حلول ذكاء اصطناعي في مؤسستك وتريد فهم ما يناسب سياقك الفعلي، تواصل مع فريق Logicity للاستشارات التقنية المتخصصة في المنطقة.
فاطمة الزهراء
كاتبة تقنية متخصصة في الذكاء الاصطناعي
مقالات ذات صلة
تصفح الكل
GLM-5.2 يقترب من عرش النماذج المغلقة في سباق البرمجة الماراثونية
في خطوة تعيد رسم خريطة المنافسة بين النماذج المفتوحة والمغلقة، أطلق مختبر Zhipu AI الصيني نموذج GLM-5.2 الذي يحقق أداءً يكاد يلامس قمة النماذج التجارية المغلقة في مهام البرمجة الماراثونية. النموذج الج

أزمة Fable: من المسؤول عن إغلاق نماذج Anthropic — البيت الأبيض أم الشركة؟
في مساء الجمعة من منتصف يونيو 2026، اتخذ البيت الأبيض قراراً غير مسبوق أربك صناعة الذكاء الاصطناعي بأكملها: فرض قيود تصدير طارئة على نموذجَي Fable 5 وMythos 5 من شركة Anthropic، ما أجبر الشركة على إيق

أسطول روبوتات Nvidia يُدرِّب نفسه ذاتياً عبر وكلاء برمجة بالذكاء الاصطناعي
نجحت Nvidia بالتعاون مع جامعتي Carnegie Mellon وUC Berkeley في تحويل مختبر روبوتات إلى منظومة ذاتية التحسين، حيث تُدرِّب روبوتات ذاتية التدريب نفسها على مهام معقدة دون الحاجة إلى إشراف بشري مستمر. أسط

إنفاق عمالقة التقنية على الذكاء الاصطناعي قد يتجاوز تدفقاتهم النقدية بحلول الربع الثالث من 2026
يواجه عمالقة التقنية الخمسة — Microsoft وAmazon وAlphabet وMeta وOracle — لحظة فارقة في تاريخهم المالي: إنفاقهم المتسارع على البنية التحتية للذكاء الاصطناعي بات يهدد بتجاوز قدرتهم على تمويله ذاتياً. و
اقرأ أيضاً
Grimmory: خادم كتب إلكترونية مستضاف ذاتياً يتفوق على بدائل Plex المثقلة بالفيديو
إذا جرّبت يوماً تنظيم مكتبة كتب رقمية متنامية باستخدام خوادم الوسائط الشاملة مثل Plex أو Jellyfin، فأنت تعرف الإحباط جيداً: قوائم معقدة مصممة أساساً للفيديو، وميزات القراءة مدفونة كفكرة لاحقة. الآن يق

ثلاثة مسلسلات من Prime Video مرشحة لجوائز Emmy تستحق المشاهدة هذا الأسبوع
في مشهد تلفزيوني يزدحم بالمسلسلات الطموحة، قليلة هي الأعمال التي تنجح في الارتقاء فوق الضجيج لتحصد إشادة النقاد وترشيحات Emmy معاً. منصة Prime Video تقدم هذا الأسبوع ثلاثة مسلسلات مرشحة لجوائز Emmy تس

اكتتاب Jio: طرح بـ 4.5 مليار دولار يُقيّم الشركة عند 145 مليار دولار في أكبر طرح هندي على الإطلاق
قدّمت Jio Platforms أوراق طرحها الأوّلي إلى هيئة SEBI الهندية، لتُعلن رسمياً انطلاق مسار ما قد يصبح أكبر اكتتاب في تاريخ الهند. تخطط الشركة لإصدار نحو 270 مليون سهم جديد، يُتوقع أن تجمع من خلالها قراب