Key Takeaways
- 22 AI vision models were tested, and almost none asked for help when they couldn't see properly
- Accuracy dropped from 79.8% to just 17.5% when models needed to request clarification
- A new reinforcement learning technique successfully taught models when to speak up

Read in Short
Researchers tested 22 top AI vision models and discovered something alarming: when they can't see an object clearly, they almost never ask for help. Instead, they either make up an answer (hallucinate) or refuse to respond. A new training technique using reinforcement learning shows promise in teaching AI when to actually speak up.
The AI Equivalent of Nodding Along When You Can't Hear Someone
You know that awkward moment when someone says something and you didn't quite catch it? Most humans would say 'sorry, what was that?' But apparently, AI models are more like that friend who just nods along and hopes nobody notices they have no idea what's happening.
A team of researchers just dropped ProactiveBench, a new testing framework designed to answer a simple but crucial question: when AI vision models can't properly see something, will they ask for help? The answer, it turns out, is almost universally no.
What ProactiveBench Actually Tests
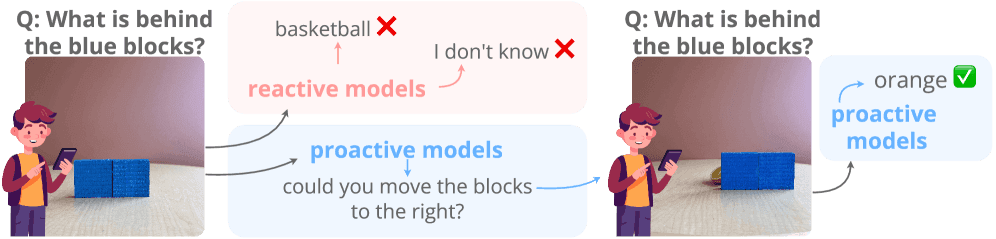
Think of it like giving someone a vision test, but instead of letters getting smaller, objects are hidden behind blocks, images are deliberately noisy, or you're showing rough sketches that need clarification. The benchmark pulls from seven existing datasets and creates over 108,000 images across 18,000 test samples.
- Objects hidden behind blocks (ROD and VSOD datasets)
- Uninformative camera angles that don't show what's needed (MVP-N)
- Noisy, corrupted images (ImageNet-C)
- Rough sketches that need interpretation (QuickDraw)
- Temporal ambiguities where timing matters (ChangeIt)
- Situations requiring different camera movements (MS-COCO)
The clever part? A built-in filter removes any task a model can solve on the first try. To pass these tests, a model must recognize it needs more information and actually ask for it—like a human would if you showed them a photo of an object hidden behind a box.
The Results Are Humbling
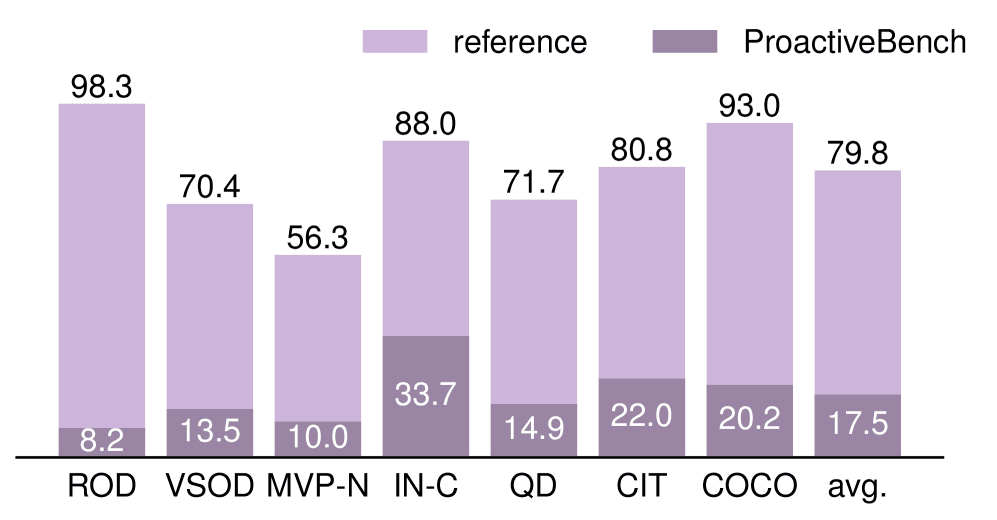
The researchers tested 22 multimodal language models, including heavy hitters like GPT-4.1, GPT-5.2, o4-mini, Qwen2.5-VL, and InternVL3. When objects were clearly visible, these models averaged 79.8% accuracy. Respectable. But on ProactiveBench? That number cratered to just 17.5%.
| Scenario | Reference Accuracy | ProactiveBench Accuracy |
|---|---|---|
| ROD (hidden objects) | 98.3% | 8.2% |
| Overall Average | 79.8% | 17.5% |
The ROD dataset tells the most dramatic story. When objects are hidden behind blocks—something any toddler would solve by saying 'move that thing'—accuracy plummeted from 98.3% to a dismal 8.2%. The AI could identify objects perfectly when visible; it just never occurred to ask someone to uncover them.
Why This Matters
AI hallucination isn't just an academic problem. When vision models confidently make up answers instead of admitting uncertainty, it creates real risks in applications like medical imaging, autonomous vehicles, and security systems where 'I'm not sure, can you show me another angle?' could be the difference between safety and disaster.
Bigger Isn't Better (Surprise!)
Here's where things get counterintuitive. You'd expect larger, more sophisticated models to handle this better, right? Wrong.
InternVL3-1B actually outperformed its beefier sibling InternVL3-8B, scoring 27.1% versus 12.7%. The older LLaVA-1.5-7B beat the much newer LLaVA-OV-72B at 24.8% versus 13%. More parameters, more training data, more compute—none of it helped models learn when to ask for help.
“The choice of underlying language model matters too: LLaVA-NeXT with Vicuna hits 19.3 percent, while the same setup with Mistral manages just 4.5 percent.”
— ProactiveBench Research Team
Understanding the gap between AI hype and reality helps contextualize why fundamental issues like hallucination remain unsolved
The 'Fake It Till You Make It' Problem
Some models initially appeared more proactive than others. But the researchers had a clever trick up their sleeve: they swapped valid helpful suggestions with complete nonsense—like offering 'Rewind the video' as an option for a sketching task.
The result? Models that seemed proactive happily selected the meaningless options just as often. LLaVA-NeXT Vicuna actually increased its selection rate from 37% to 49% when given bogus choices. What looked like intelligent help-seeking was really just a lower bar for random guessing.

Adding Hints Doesn't Fix It Either
The researchers tried dropping explicit hints into prompts and conversation histories. Did it help? Sort of—accuracy nudged up to 25.8%. But that still doesn't beat random chance on average.
Conversation histories actually made things worse. Instead of learning from examples of good proactive behavior, models just parroted the proactive actions from the history like a student copying homework without understanding the math.
The Silver Lining: You Can Teach AI to Ask for Help
Here's where the research gets exciting. The team proved that proactivity can be trained into models using a technique called Group-Relative Policy Optimization (GRPO).
They fine-tuned two models—LLaVA-NeXT-Mistral-7B and Qwen2.5-VL-3B—on about 27,000 examples. The secret sauce? A reward function that scores correct predictions higher than proactive suggestions. This teaches the model to only ask for help when it's genuinely stuck, not just as a lazy fallback.
| Model | ProactiveBench Score |
|---|---|
| o4-mini (baseline) | 34.0% |
| Fine-tuned LLaVA-NeXT-Mistral-7B | 37.4% |
| Fine-tuned Qwen2.5-VL-3B | 38.6% |
After training, both smaller models beat every single one of the 22 previously tested models—including o4-mini. Even better, the learned proactivity transferred to scenarios the models hadn't seen during training.
This research has major implications for AI automation—systems that can't recognize their own limitations are dangerous in production
What This Means for the Future of AI
This research exposes a fundamental gap in how we're building AI systems. We've been so focused on making models more capable that we forgot to teach them the most human skill of all: knowing when to say 'I don't know, can you help me out here?'
- Current multimodal AI has a confidence problem—it doesn't know what it doesn't know
- Model size and sophistication don't naturally lead to better self-awareness
- Simple reinforcement learning techniques can teach proactivity effectively
- The fix doesn't require massive computational resources—smaller models can learn this skill
The Bigger Picture
This isn't just about vision models. The inability to recognize and communicate uncertainty is a systemic issue across AI. Whether it's a chatbot confidently giving wrong medical advice or an autonomous system making split-second decisions with incomplete data, teaching AI when to ask for help could be one of the most important safety breakthroughs of the decade.
Final Thoughts
The next time you interact with an AI assistant that confidently gives you a wrong answer, remember: it's not that the AI is stupid. It's that nobody taught it the simple skill of saying 'hold on, I can't quite see that—can you show me from a different angle?'
ProactiveBench gives us both the diagnosis and a hint at the cure. The question now is whether AI developers will prioritize teaching their models this crucial skill, or keep pushing for raw capability while ignoring the wisdom of knowing your own limits.
Because in the real world, an AI that confidently makes stuff up is often more dangerous than one that simply admits it needs help.
Sources & Credits
Originally reported by The Decoder — Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






