Key Takeaways
- Claude Opus 4.7 leads the MirrorCode benchmark at 56% solve rate, followed by GPT-5.5 at 44%
- The longest task ran for 19 days continuous at $2,600 compute cost with zero human intervention
- No AI model has solved any of the large-scale tasks in the benchmark yet
Epoch AI and METR have released MirrorCode, a coding benchmark that pushed one AI model to program continuously for 19 days on a single task. The compute bill: $2,600. No human touched the keyboard. Claude Opus 4.7 leads the benchmark with a 56 percent solve rate, but every model tested fails completely on the hardest problems.
The benchmark differs sharply from existing tests like SWE-bench or HumanEval. Instead of fixing bugs or completing functions, MirrorCode requires AI models to reimplement entire programs from scratch. The models never see the original source code. They work only from the program's input-output behavior, essentially reverse-engineering software through black-box testing.
What does MirrorCode actually test?
The benchmark includes 25 target programs spanning Unix utilities, data serialization, bioinformatics tools, interpreters, static analysis, cryptography, and compression. Each AI-generated solution must exactly match the original program's output, including hidden end-to-end tests the model never sees during development.
Epoch AI deliberately removed the compute constraints that hobble most benchmarks. Existing software engineering tests often cap inference costs at $1 to $10 per task, even when a human would need weeks to finish the same work. MirrorCode lets models spend what they need. The largest task cost $2,600 and ran for 19 days straight.
This design tests something closer to real agentic capability. Can an AI model sustain coherent problem-solving over days or weeks? Can it debug its own code through iterative testing? Can it match human-level output on substantial engineering work?
How did Claude Opus 4.7 beat the competition?
The standout result came from Anthropic's Claude Opus 4.7 reimplementing gotree, a bioinformatics toolkit with roughly 16,000 lines of Go code and over 40 commands. Epoch AI estimates a human engineer would need 2 to 17 weeks for the same job. Opus 4.7 finished in 14 hours for $251.
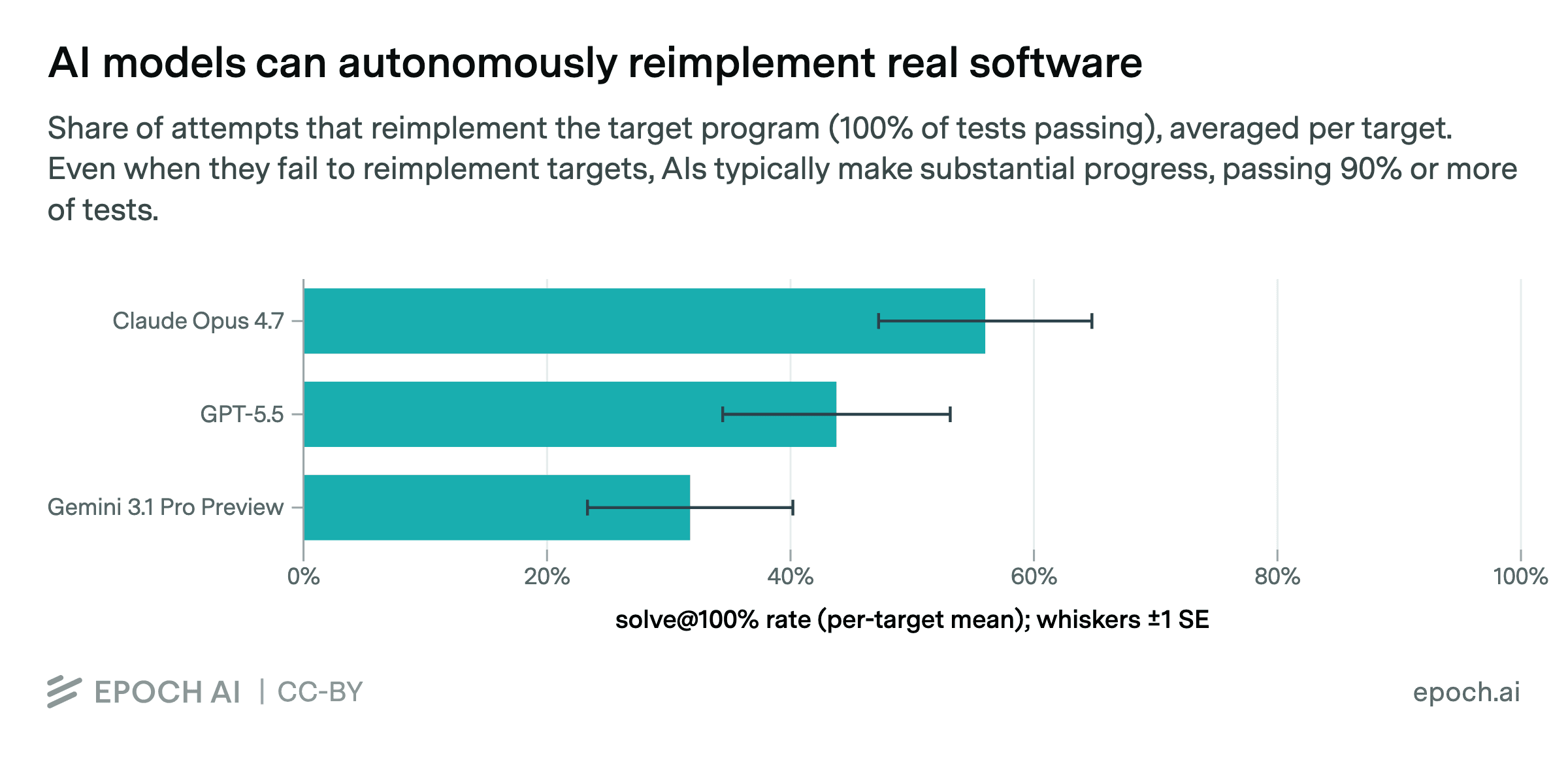
In the overall rankings, Claude Opus 4.7 hit 56 percent. GPT-5.5 followed at 44 percent. Gemini 3.1 Pro Preview came in at 32 percent. Even when models fail to fully reimplement a program, they typically pass 90 percent or more of the individual tests. Partial success is common. Complete success remains rare.
Cost efficiency varies wildly between models. GPT-5.5 costs three times as much as GPT-5 for the same tasks. Claude Opus 4.7 runs three times cheaper than Claude Opus 4.1. Price does not correlate cleanly with performance.
Where do all AI models still fail?
MirrorCode tasks fall into three categories: small, medium, and large. Small programs like uuid generators or CSV parsers get reliably solved by all tested models. Medium tasks show mixed results. The largest tasks beat every model tested.
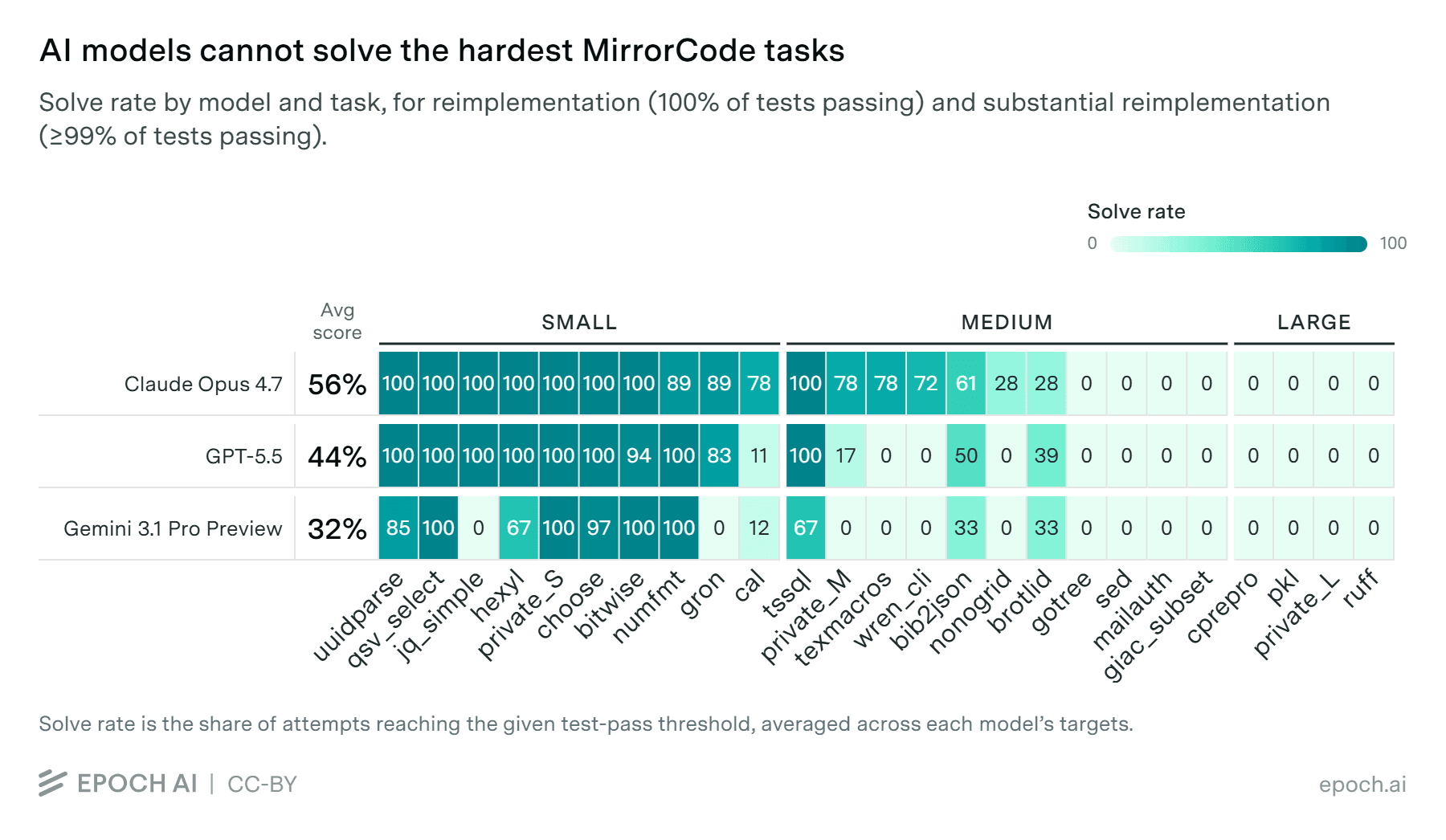
Zero models cracked any large-scale task. This includes complex compression algorithms, full interpreters, and sophisticated cryptographic implementations. The gap between medium and large tasks appears categorical, not gradual. Models that handle 5,000-line programs collapse entirely at 15,000 lines.
Progress is rapid, though. Epoch AI estimates that leading models from a year ago would have scored only 30 percent and been limited to simpler programs like a calendar utility. Current models handle bioinformatics toolkits. Next year's models might handle compilers.
Did the models memorize the answers?
The researchers flag one important caveat. MirrorCode uses open-source programs as targets. The models may have seen the original code during training. Initial tests suggest memorization did not dominate the results, but the researchers write that they cannot rule out the possibility that memorization contributes to AI performance.
To address this, Epoch AI open-sourced the scaffold and 22 of the 25 target programs, covering 132 task instances across six programming languages. Three programs remain private for testing. Independent researchers can now verify whether models are reasoning or recalling.
Logicity's Take
MirrorCode matters because it tests the economics of AI coding agents, not just their capability. A 14-hour $251 run that replaces 2-17 weeks of human work changes the math for AI product teams. But the 0% success rate on large tasks shows clear limits. Teams building coding agents should benchmark against MirrorCode's medium-tier tasks, where success is possible but not trivial. The open-source scaffold gives product teams a real testing environment that matches production-scale work.
What comes next for coding benchmarks?
MirrorCode's design points toward a future where AI benchmarks test sustained autonomous work, not quick responses. The 19-day continuous run is not an edge case but a preview. As AI agents take on longer projects, benchmarks will need to measure reliability over days and weeks, not seconds.
The cost data also matters. When an AI run costs $2,600 and still fails, teams need to know that before deployment. When a $251 run replaces weeks of engineering, that changes hiring and project planning. Benchmarks that include cost alongside accuracy give product teams the numbers they need to make real decisions.
Frequently Asked Questions
What is the MirrorCode benchmark?
MirrorCode is a coding benchmark from Epoch AI and METR that requires AI models to reimplement entire programs from scratch without access to the original source code. Models must match the program's input-output behavior exactly.
Which AI model performs best on MirrorCode?
Claude Opus 4.7 leads with a 56 percent solve rate, followed by GPT-5.5 at 44 percent and Gemini 3.1 Pro Preview at 32 percent.
How long did the longest MirrorCode task take?
One AI model ran continuously for 19 days on a single MirrorCode task, costing $2,600 in compute with no human involvement.
Can AI models solve all MirrorCode tasks?
No. All tested models fail completely on the largest tasks in MirrorCode, including complex interpreters and cryptographic implementations.
Is MirrorCode open source?
Epoch AI has open-sourced the scaffold and 22 of 25 target programs across six programming languages. Three programs remain private for testing purposes.
Need Help Implementing This?
If you're building AI coding agents and want to benchmark against MirrorCode or integrate agentic capabilities into your development workflow, get in touch with Logicity's team for implementation guidance.
Source: The Decoder / Matthias Bastian
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






