
Alibaba's Qwen3.5-Omni AI model has made a groundbreaking achievement by learning to write code from spoken instructions and video input without any prior training. This omnimodal AI model can process text, images, audio, and video, and outperforms Google's Gemini 3.1 Pro in audio tasks. With its ability to generate speech output alongside text, Qwen3.5-Omni is set to revolutionize the way we interact with technology.
Key Takeaways
- Qwen3.5-Omni can write code from spoken instructions and video input
- The model outperforms Google's Gemini 3.1 Pro in audio tasks
- Qwen3.5-Omni supports speech recognition in 74 languages
In This Article
- Introduction to Qwen3.5-Omni
- Technical Capabilities of Qwen3.5-Omni
- Speech Recognition Capabilities
- Comparison to Google's Gemini 3.1 Pro
- Future Applications of Qwen3.5-Omni
- Conclusion
Introduction to Qwen3.5-Omni
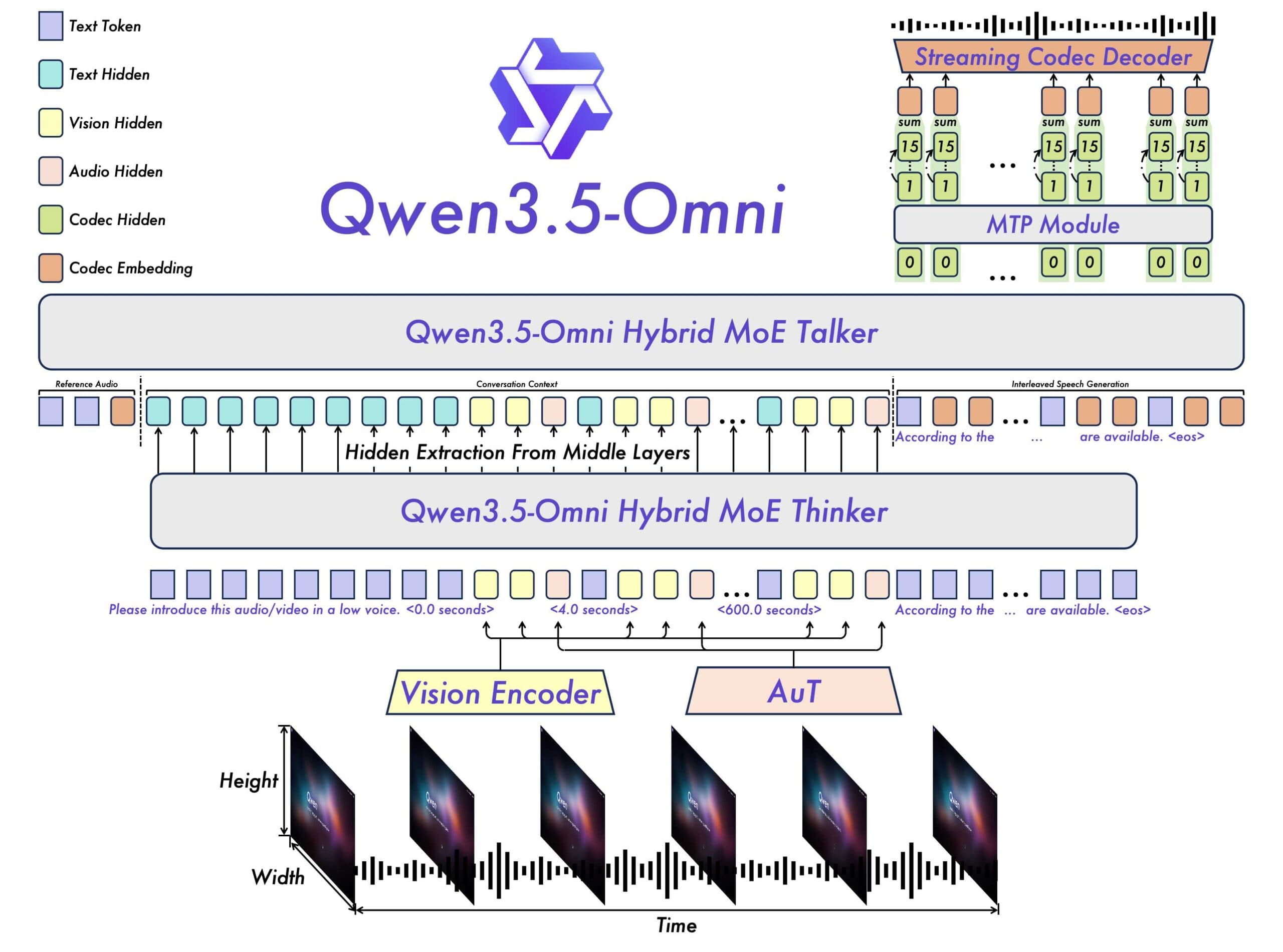
The field of artificial intelligence has seen significant advancements in recent years, and one of the most exciting developments is the creation of omnimodal AI models. These models can process multiple forms of data, including text, images, audio, and video, and can perform a wide range of tasks. Alibaba's Qwen3.5-Omni is one such model, and it has made a remarkable achievement by learning to write code from spoken instructions and video input.
- Qwen3.5-Omni is an omnimodal AI model that can process text, images, audio, and video
- The model has been trained on over 100 million hours of audiovisual material

Technical Capabilities of Qwen3.5-Omni
So, what makes Qwen3.5-Omni so special? For starters, the model has been trained on an enormous amount of data, including over 100 million hours of audiovisual material. This training data has enabled the model to develop a deep understanding of the relationships between different forms of data, and to generate high-quality outputs.
- Qwen3.5-Omni can handle contexts up to 256,000 tokens
- The model can process more than ten hours of audio and over 400 seconds of 720p video at one frame per second

Speech Recognition Capabilities
One of the most impressive aspects of Qwen3.5-Omni is its speech recognition capabilities. The model supports speech recognition in 74 languages, which is a significant improvement over its predecessor, which only supported 11 languages. This expanded language support makes Qwen3.5-Omni a much more versatile and useful tool.
- Qwen3.5-Omni supports speech recognition in 74 languages
- The model also supports 39 Chinese dialects, for a total of 113 languages and dialects
Comparison to Google's Gemini 3.1 Pro
So, how does Qwen3.5-Omni stack up against other AI models? In particular, how does it compare to Google's Gemini 3.1 Pro? The answer is that Qwen3.5-Omni outperforms Gemini 3.1 Pro in audio tasks, including speech recognition and music comprehension.
- Qwen3.5-Omni outperforms Gemini 3.1 Pro in audio comprehension, with a score of 82.2 versus 81.1
- The model also outperforms Gemini 3.1 Pro in music comprehension, with a score of 72.4 versus 59.6

Future Applications of Qwen3.5-Omni
So, what are the potential applications of Qwen3.5-Omni? One of the most exciting possibilities is the use of the model in voice-activated coding tools. Imagine being able to dictate code to a computer, and having it written out for you in real-time. This could revolutionize the way we develop software, and make it much easier for people to learn how to code.
- Qwen3.5-Omni could be used in voice-activated coding tools
- The model could also be used in a wide range of other applications, including virtual assistants and language translation tools
Conclusion
In conclusion, Qwen3.5-Omni is a groundbreaking AI model that has the potential to revolutionize the way we interact with technology. With its ability to write code from spoken instructions and video input, and its impressive speech recognition capabilities, Qwen3.5-Omni is an exciting development in the field of artificial intelligence.
- Qwen3.5-Omni is a major breakthrough in the field of artificial intelligence
- The model has the potential to revolutionize the way we interact with technology
“The model was natively pre-trained as omnimodal on over 100 million hours of audiovisual material.”
— Qwen team
Final Thoughts
As we look to the future, it's exciting to think about the potential applications of Qwen3.5-Omni. With its impressive capabilities and versatility, this model is sure to make a significant impact in the world of artificial intelligence.
Sources & Credits
Originally reported by Unknown — Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






