Moonshot's Kimi K2.7 Code Costs 12x Less Than GPT-5.5

Key Takeaways
- Kimi K2.7 Code costs $0.95 per million input tokens and $4.00 per million output tokens, up to 12x cheaper than frontier competitors
- The model scores 81.1 on MCPMark Verified, beating Claude Opus 4.8's 76.4 on this agent-focused benchmark
- A Mixture-of-Experts architecture uses only 32 billion of its 1 trillion parameters per token, enabling efficiency gains
Moonshot AI has released Kimi K2.7 Code, an open-weights model built for programming tasks and agent-based coding workflows. The model is available on Hugging Face and positions itself as a budget-friendly alternative to GPT-5.5 and Claude Opus 4.8.
The pricing difference is dramatic. Kimi K2.7 Code charges $0.95 per million input tokens and $4.00 per million output tokens. For teams running heavy coding workflows, that translates to cost savings of up to 12x compared to frontier Western models.
Benchmark Performance: Strong on Agents, Weaker on Pure Coding
Moonshot's new model improves on its predecessor K2.6 across the board. On the company's in-house Kimi Code Bench v2, performance jumped from 50.9 to 62.0. Program Bench scores rose from 48.3 to 53.6, and MLS Bench Lite climbed from 26.7 to 35.1.
But the model still trails GPT-5.5 and Claude Opus 4.8 on most standard coding benchmarks. GPT-5.5 scores 69.1 on Program Bench compared to K2.7 Code's 53.6. On Kimi Code Bench v2, GPT-5.5 hits 69.0 versus 62.0 for the Moonshot model.
Program Bench is a particularly demanding test. Agents must reproduce a program's behavior using only a compiled binary and its documentation. No source code access, no decompilation, no internet. It's a stress test for reasoning under constraints.
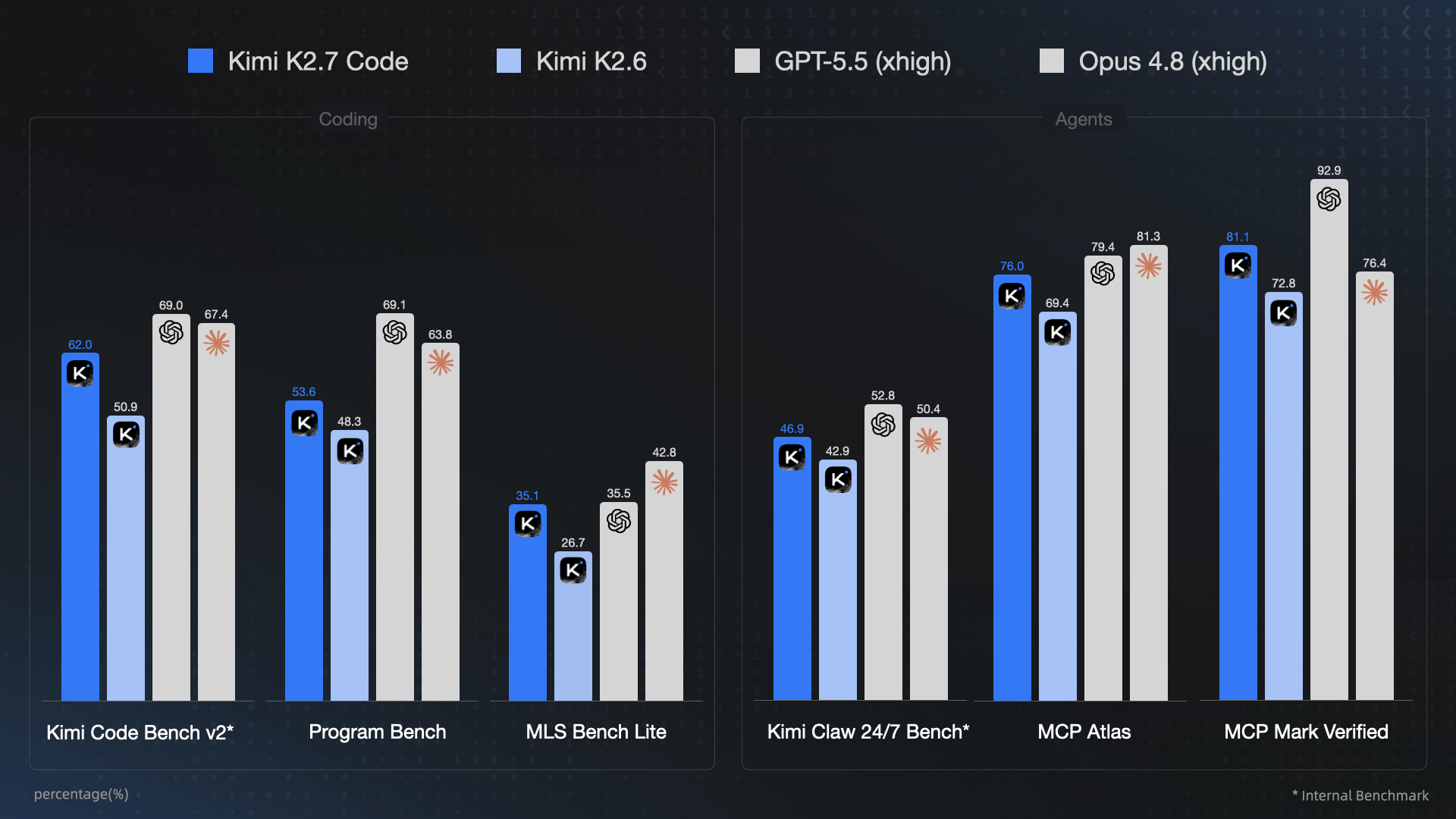
The picture changes on agent-focused benchmarks. K2.7 Code scores 76.0 on MCP Atlas (up from 69.4 on K2.6) and 81.1 on MCPMark Verified (up from 72.8). That MCPMark score is notable. It beats Claude Opus 4.8's 76.4 on a benchmark that tests AI agents across five real-world software environments: Notion, GitHub, file systems, Postgres databases, and browser automation via Playwright.
GPT-5.5 still leads on MCPMark Verified with 92.9. But for teams that can tolerate some performance gap in exchange for 12x cost savings, K2.7 Code's agent performance makes it a credible option.
Architecture: One Trillion Parameters, 32 Billion Active
Kimi K2.7 Code uses a Mixture-of-Experts (MoE) architecture. The model has one trillion total parameters, but only 32 billion are active per token. It draws from a pool of 384 experts, selecting eight per token. This design enables the model to maintain quality while reducing inference costs.
Context length is 256,000 tokens, enough for deep repository analysis. The model is multimodal and can process images and video alongside text.
“By optimizing the reasoning phase, we've reduced token overhead by 30%, making agent-based coding workflows viable at scale without the traditional cost barriers.”
— Moonshot AI Lead Engineer
That 30% reduction in reasoning tokens directly affects the bill for agentic tasks, where models often burn through tokens on internal chain-of-thought steps. For workflows that involve multi-file debugging or repository-scale refactoring, the savings compound quickly.
Developer Reception
Early community reaction has been positive. Discussions on HackerNews and Reddit's r/LocalLLaMA show enthusiasm for the model's 60.4% score on SWE-bench Verified. Developers are testing its ability to handle repository-scale refactoring via the Kimi Code CLI.
There's also existing commercial traction. Cursor, the coding tool provider, resells a modified version of the Kimi model. That suggests real-world validation beyond benchmark performance.
When to Use K2.7 Code (and When Not To)
Moonshot is clear about the model's scope. K2.7 Code is optimized for long-running, complex software engineering tasks. For general tasks outside coding, the company still recommends the earlier K2.6 model.
The tradeoff is straightforward. If your workload involves heavy agent-based coding, repository-scale changes, or MCP integrations, K2.7 Code offers strong performance at a fraction of frontier pricing. If you need the absolute best scores on pure coding benchmarks, GPT-5.5 remains the leader.
| Model | Program Bench | MCPMark Verified | Input Cost (per 1M tokens) |
|---|---|---|---|
| Kimi K2.7 Code | 53.6 | 81.1 | $0.95 |
| Claude Opus 4.8 | — | 76.4 | ~$11+ |
| GPT-5.5 | 69.1 | 92.9 | ~$11+ |
Logicity's Take
Context on the strategic implications of open-weights AI models from Chinese labs
Related coverage of non-Western AI model development
Frequently Asked Questions
How much does Kimi K2.7 Code cost compared to GPT-5.5?
Kimi K2.7 Code charges $0.95 per million input tokens and $4.00 per million output tokens. This is up to 12x cheaper than GPT-5.5 and Claude Opus 4.8.
Is Kimi K2.7 Code open source?
Yes, the model is available as open-weights on Hugging Face, allowing developers to download and run it locally or on their own infrastructure.
How does Kimi K2.7 Code perform on coding benchmarks?
It scores 53.6 on Program Bench and 62.0 on Kimi Code Bench v2, trailing GPT-5.5's 69.1 and 69.0 respectively. However, it beats Claude Opus 4.8 on MCPMark Verified with 81.1 vs 76.4.
What is the context window for Kimi K2.7 Code?
The model supports a 256,000 token context window, enabling deep repository analysis and long-running coding tasks.
Should I use Kimi K2.7 Code for non-coding tasks?
Moonshot AI recommends using the earlier K2.6 model for general tasks outside coding. K2.7 Code is optimized specifically for software engineering and agent workflows.
Need Help Implementing This?
Source: The Decoder / Matthias Bastian
Manaal Khan
Tech & Innovation Writer
اقرأ أيضاً

رأي مغاير: كيف يؤثر اختراق الأمن الداخلي الأميركي على شركاتنا الخاصة؟
في ظل اختراق عقود الأمن الداخلي الأميركي مع شركات خاصة، نناقش تأثير هذا الاختراق على مستقبل الأمن السيبراني. نستعرض الإحصاءات الموثوقة ونناقش كيف يمكن للشركات الخاصة أن تتعامل مع هذا التهديد. استمتع بقراءة هذا التحليل العميق

الإنسان في زمن ما بعد الوجود البشري: نحو نظام للتعايش بين الإنسان والروبوت - Centre for Arab Unity Studies
في هذا المقال، سنناقش كيف يمكن للبشر والروبوتات التعايش في نظام متكامل. سنستعرض التحديات والحلول المحتملة التي تضعها شركات مثل جوجل وأمازون. كما سنلقي نظرة على التوقعات المستقبلية وفقًا لتقرير ماكنزي

إطلاق ناسا لمهمة مأهولة إلى القمر: خطوة تاريخية نحو استكشاف الفضاء
تعتبر المهمة الجديدة خطوة هامة نحو استكشاف الفضاء وتطوير التكنولوجيا. سوف تشمل المهمة إرسال رواد فضاء إلى سطح القمر لconducting تجارب علمية. ستسهم هذه المهمة في تطوير فهمنا للفضاء وتحسين التكنولوجيا المستخدمة في استكشاف الفضاء.