نموذج ذكاء اصطناعي يبرمج 19 يوماً متواصلة بتكلفة 2600 دولار: اختبار MirrorCode يكشف حدود وكلاء البرمجة
أبرز النقاط
- نموذج ذكاء اصطناعي عمل 19 يوماً متواصلة على مهمة برمجية واحدة بتكلفة 2600 دولار
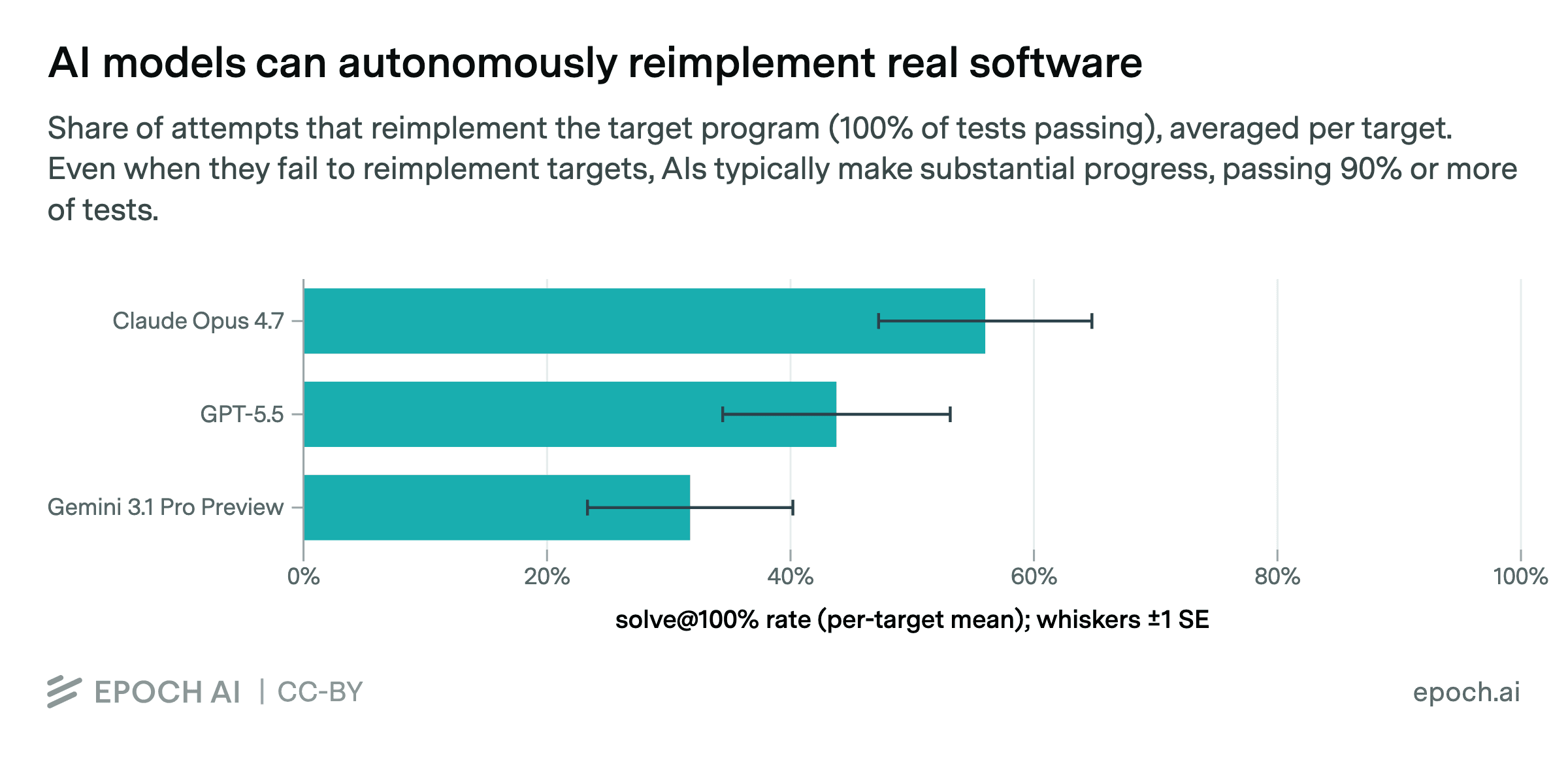
- Claude Opus 4.7 يتصدر الاختبار بنسبة نجاح 56% متفوقاً على GPT-5.5 وGemini 3.1 Pro
- جميع النماذج فشلت في المهام الأكثر تعقيداً رغم التقدم الملحوظ
كشفت منظمة Epoch AI بالتعاون مع METR عن اختبار MirrorCode الجديد للبرمجة، وهو معيار قياسي يتحدى نماذج الذكاء الاصطناعي لإعادة بناء برامج كاملة من الصفر دون الوصول إلى الشيفرة المصدرية الأصلية. النتيجة الأبرز: نموذج واحد عمل 19 يوماً متواصلة على مهمة برمجية واحدة بتكلفة بلغت 2600 دولار أمريكي، دون أي تدخل بشري.
ما الذي يميز اختبار MirrorCode عن معايير البرمجة الأخرى؟
يختلف MirrorCode جذرياً عن اختبارات البرمجة التقليدية التي تقيس إكمال الشيفرة أو إصلاح الأخطاء. هنا، على النموذج أن يُعيد بناء برنامج كامل اعتماداً على سلوكه فقط — أي ما يُدخَل إليه وما يُخرجه — دون رؤية سطر واحد من الشيفرة الأصلية.
يشمل الاختبار 25 برنامجاً مستهدفاً تغطي أدوات Unix، وتسلسل البيانات، والمعلوماتية الحيوية، والمفسّرات، والتحليل الساكن، والتشفير، والضغط. كل حل يُنتجه الذكاء الاصطناعي يجب أن يُطابق مخرجات البرنامج الأصلي تماماً، بما في ذلك اختبارات شاملة مخفية لم يرها النموذج أثناء التطوير.
لماذا ميزانية الاستدلال مهمة في تقييم وكلاء البرمجة؟
تُحدد معظم اختبارات هندسة البرمجيات الحالية سقفاً للتكلفة يتراوح بين دولار و10 دولارات للمهمة الواحدة، حتى عندما يحتاج مهندس بشري أسابيع لإنجاز العمل ذاته. هذا القيد يُخفي القدرات الحقيقية للنماذج في المهام طويلة الأمد.
أزال MirrorCode هذا القيد. النتيجة: إحدى المهام الكبرى كلّفت 2600 دولار لتشغيل واحد، مع عمل متواصل للنموذج على مدار 19 يوماً كاملة دون أي تدخل بشري. هذا يُظهر أن وكلاء الذكاء الاصطناعي قادرون على المثابرة في مهام معقدة لفترات تُنافس — بل تتجاوز — ما يُتوقع من فرق بشرية.
كيف أعاد Claude Opus 4.7 بناء أداة معلوماتية حيوية في 14 ساعة؟
المثال الأبرز جاء من Claude Opus 4.7 الذي أعاد بناء أداة gotree، وهي حزمة معلوماتية حيوية تضم نحو 16,000 سطر من شيفرة Go وأكثر من 40 أمراً. يُقدّر الباحثون أن مهندساً بشرياً يعمل بدون مساعدة الذكاء الاصطناعي سيحتاج من أسبوعين إلى 17 أسبوعاً لإنجاز المهمة ذاتها. Opus 4.7 أنهاها في 14 ساعة فقط بتكلفة 251 دولاراً.
- Claude Opus 4.7: نسبة نجاح 56% — المركز الأول
- GPT-5.5: نسبة نجاح 44% — المركز الثاني
- Gemini 3.1 Pro Preview: نسبة نجاح 32% — المركز الثالث
حتى عندما تفشل النماذج في إعادة بناء برنامج بالكامل، فإنها عادةً تجتاز 90% أو أكثر من الاختبارات. هذا يُشير إلى قدرة عالية على فهم المنطق البرمجي حتى دون الوصول للحل الكامل.
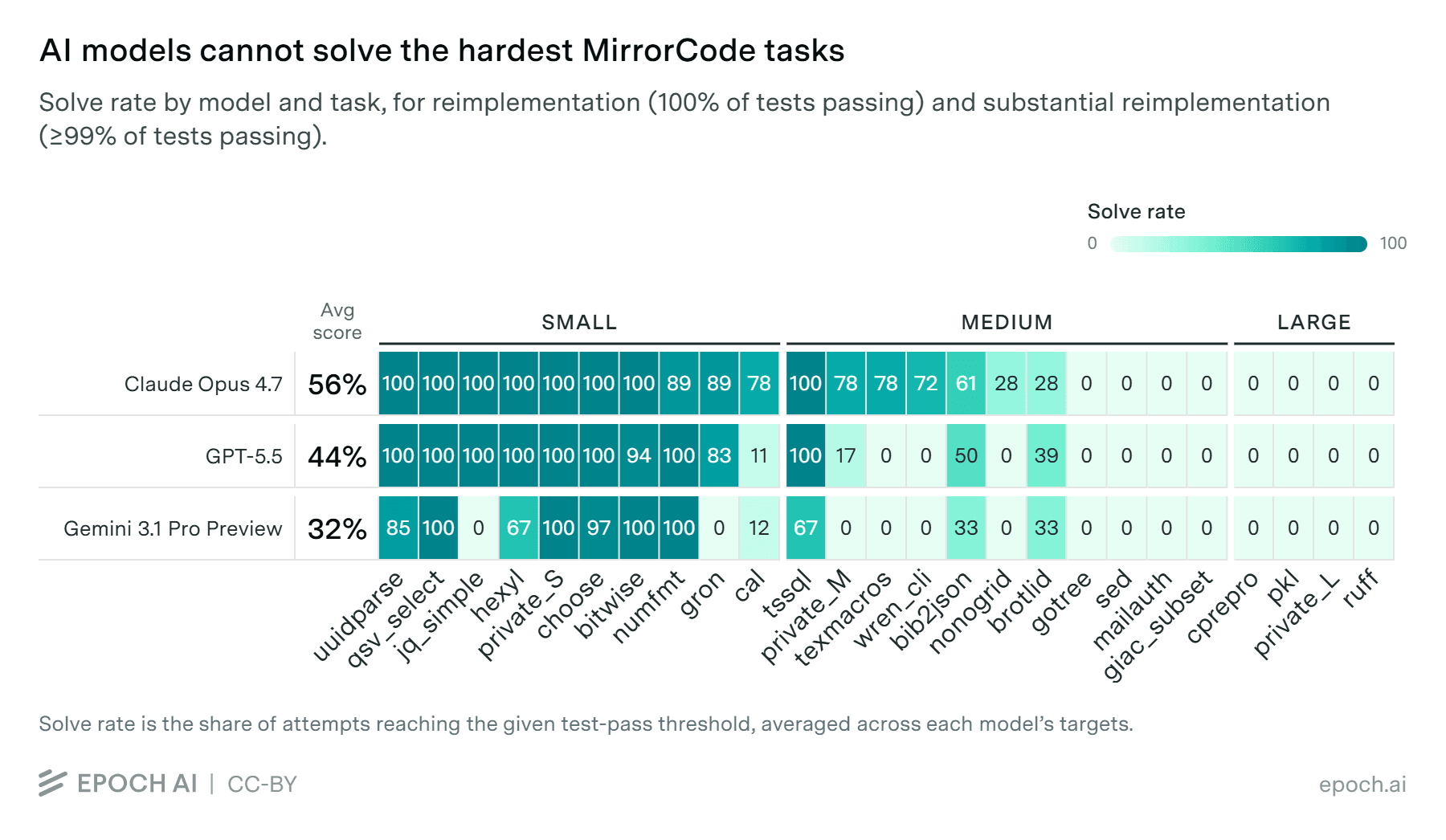
ما المهام التي لا تزال تهزم جميع نماذج الذكاء الاصطناعي؟
تنقسم مهام MirrorCode إلى ثلاث فئات: صغيرة ومتوسطة وكبيرة. البرامج الصغيرة مثل uuid أو parseqsv تُعاد بناؤها بموثوقية من جميع النماذج المُختبرة. لكن المهام الكبرى — التي تشمل أنظمة تشفير معقدة ومفسّرات لغات برمجة — تهزم كل نموذج دون استثناء.
هذه الفجوة تكشف أن الذكاء الاصطناعي، رغم تقدمه المذهل، لا يزال بعيداً عن إتقان التفكير الخوارزمي المعقد الذي تتطلبه البرامج الكبيرة. النماذج الرائدة قبل عام كانت ستُحقق نحو 30% فقط وتقتصر على برامج أبسط كأداة تقويم.
هل تكلفة الذكاء الاصطناعي تتناسب مع الأداء؟
لا تتبع التكاليف نمطاً واضحاً. GPT-5.5 يُكلف ثلاثة أضعاف GPT-5 للمهام ذاتها، بينما Claude Opus 4.7 يعمل بثلث تكلفة Claude Opus 4.1. هذا التباين يُعقّد حسابات العائد على الاستثمار للشركات التي تُخطط لاعتماد وكلاء البرمجة.
هل حفظ النماذج للشيفرة الأصلية يُؤثر على النتائج؟
يُشير الباحثون إلى تحفظ مهم: بما أن MirrorCode يستخدم برامج مفتوحة المصدر كأهداف، قد تكون النماذج رأت الشيفرة الأصلية أثناء التدريب. الاختبارات الأولية تُشير إلى أن النتائج لم تُهيمن عليها الذاكرة، لكن لا يمكن استبعاد أن الحفظ يُساهم جزئياً في أداء الذكاء الاصطناعي.
لمعالجة هذا، أتاحت Epoch AI الهيكل البرمجي و22 من البرامج المستهدفة الـ25 للجمهور، تغطي 132 نسخة مهمة عبر ست لغات برمجة. ثلاثة برامج بقيت خاصة للاختبار المستقل.
رأي Logicity
يُمثل MirrorCode نقلة نوعية في تقييم وكلاء البرمجة بالذكاء الاصطناعي. للشركات التي تُقيّم أدوات مثل GitHub Copilot (يبدأ من 10 دولارات شهرياً) أو Cursor Pro (20 دولاراً شهرياً) أو Amazon CodeWhisperer، هذا الاختبار يكشف فجوة حقيقية: هذه الأدوات تتفوق في إكمال الشيفرة لكنها لا تزال بعيدة عن استبدال مهندس يُعيد بناء نظام معقد من الصفر. التكلفة العالية (2600 دولار لمهمة واحدة) تعني أن الجدوى الاقتصادية لوكلاء البرمجة المستقلة لا تزال محدودة بالمهام الصغيرة والمتوسطة.
الأسئلة الشائعة
ما هو اختبار MirrorCode وكيف يختلف عن معايير البرمجة الأخرى؟
MirrorCode هو اختبار طورته Epoch AI وMETR يتطلب من نماذج الذكاء الاصطناعي إعادة بناء برامج كاملة من الصفر دون رؤية الشيفرة المصدرية، اعتماداً على سلوك البرنامج فقط. يختلف عن الاختبارات التقليدية بإزالة سقف التكلفة، ما يسمح بتقييم القدرات الحقيقية في المهام طويلة الأمد.
أي نموذج ذكاء اصطناعي حقق أفضل نتيجة في MirrorCode؟
تصدر Claude Opus 4.7 من Anthropic بنسبة نجاح 56%، تلاه GPT-5.5 بنسبة 44%، ثم Gemini 3.1 Pro Preview بنسبة 32%.
كم تكلف مهام البرمجة الطويلة بالذكاء الاصطناعي؟
تتفاوت التكاليف بشكل كبير. أغلى مهمة في MirrorCode كلفت 2600 دولار لتشغيل واحد استمر 19 يوماً. في المقابل، أعاد Claude Opus 4.7 بناء أداة معلوماتية حيوية من 16,000 سطر في 14 ساعة بتكلفة 251 دولاراً فقط.
هل يمكن للذكاء الاصطناعي استبدال مهندسي البرمجيات بالكامل؟
ليس بعد. رغم أن النماذج تُنجز مهام صغيرة ومتوسطة بكفاءة، إلا أن جميع النماذج فشلت في المهام الكبرى المعقدة. الذكاء الاصطناعي يُسرّع العمل لكنه لا يزال يحتاج إشرافاً بشرياً للأنظمة المعقدة.
هل نتائج MirrorCode موثوقة أم تعتمد على حفظ النماذج للشيفرة؟
الاختبارات الأولية تُشير إلى أن الحفظ لم يُهيمن على النتائج، لكن الباحثين لا يستبعدون مساهمته جزئياً. لذلك أبقوا 3 برامج خاصة للاختبار المستقل.
هل تحتاج مساعدة في التطبيق؟
إذا كنت تُخطط لدمج وكلاء البرمجة بالذكاء الاصطناعي في سير عمل فريقك التقني، تواصل مع فريق Logicity للحصول على استشارة حول اختيار الأدوات المناسبة وتقدير التكاليف الفعلية لحالتك الاستخدامية.
فاطمة الزهراء
كاتبة تقنية متخصصة في الذكاء الاصطناعي
أُنتِج هذا المقال بمساعدة الذكاء الاصطناعي وراجعه فريق التحرير في لوجيسيتي. اعرف المزيد في سياسة التحرير.