GLM-5.2 يقترب من عرش النماذج المغلقة في سباق البرمجة الماراثونية

أبرز النقاط
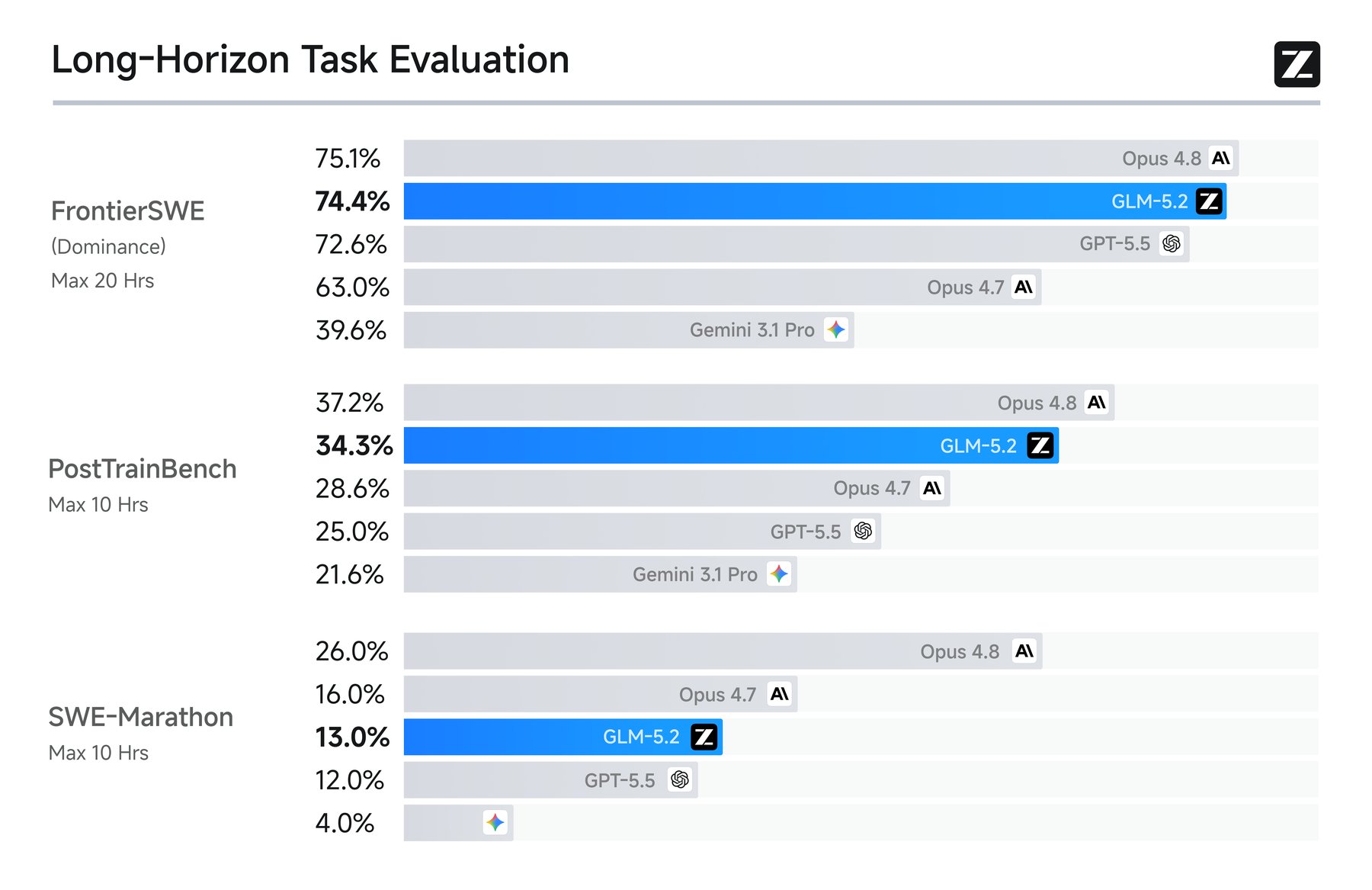
- GLM-5.2 يسجل 74.4% على FrontierSWE، متخلفاً نقطة واحدة فقط عن Claude Opus 4.8
- النموذج يدعم سياقاً مستقراً بمليون رمز تحت رخصة MIT المفتوحة
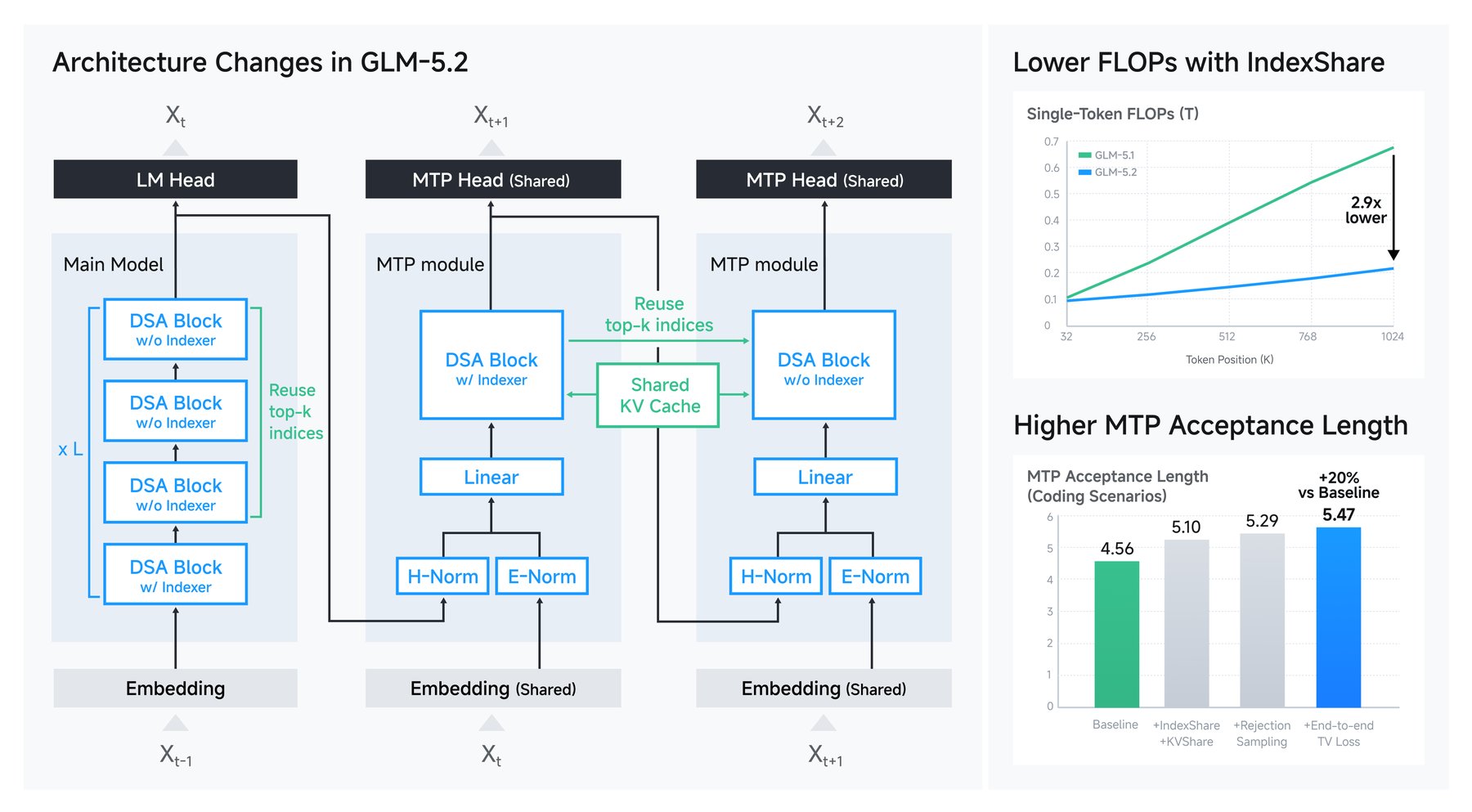
- تقنية IndexShare الجديدة تخفض تكلفة الحوسبة 2.9 مرة عند السياقات الطويلة
في خطوة تعيد رسم خريطة المنافسة بين النماذج المفتوحة والمغلقة، أطلق مختبر Zhipu AI الصيني نموذج GLM-5.2 الذي يحقق أداءً يكاد يلامس قمة النماذج التجارية المغلقة في مهام البرمجة الماراثونية. النموذج الجديد يسجل 74.4% على معيار FrontierSWE، متخلفاً بنقطة مئوية واحدة فقط عن Claude Opus 4.8 من Anthropic، وهو ما يمثل إنجازاً لافتاً لنموذج مفتوح المصدر بالكامل تحت رخصة MIT.
يأتي هذا الإطلاق في سياق تصاعد التوترات حول قيود التصدير الأمريكية على تقنيات الذكاء الاصطناعي المتقدمة، ليثبت أن المصادر المفتوحة قادرة على مجاراة النماذج التجارية الأغلى ثمناً. بالنسبة للشركات الخليجية الساعية لبناء قدراتها في الذكاء الاصطناعي، يفتح GLM-5.2 باباً لاستخدام نموذج متقدم دون الارتباط بمزودي خدمات محددين أو تكاليف اشتراك مرتفعة.
ما الذي يميز GLM-5.2 عن منافسيه؟
صمم Zhipu AI هذا النموذج خصيصاً لما يسميه "المهام ذات الأفق الطويل" — جلسات برمجة تمتد لساعات وتتضمن آلاف الخطوات المتتابعة. لتحقيق ذلك، وسّع المختبر نافذة السياق إلى مليون رمز، مع التركيز في التدريب على سيناريوهات البرمجة الوكيلية كالتنفيذ واسع النطاق والبحث الآلي وتصحيح الأخطاء المعقدة.
يعترف المختبر في مدونته بصعوبة هذا التحدي: الادعاء بدعم مليون رمز سهل، لكن الحفاظ على استقرار الأداء عبر جلسات برمجة طويلة وغير منظمة أصعب بكثير. هنا يكمن التميز الحقيقي للنموذج.
كيف يقارن GLM-5.2 بالنماذج الرائدة؟
تكشف نتائج المعايير المختلفة عن صورة متباينة ومثيرة للاهتمام:
- FrontierSWE: يسجل 74.4%، متقدماً على GPT-5.5 ومتخلفاً نقطة واحدة عن Opus 4.8
- PostTrainBench: يتفوق على كل من GPT-5.5 وOpus 4.7، ويحتل المركز الثاني خلف Opus 4.8
- SWE-Marathon: يحقق نصف نتيجة Opus 4.8 فقط في المهام فائقة الطول كبناء المترجمات وتحسين النواة
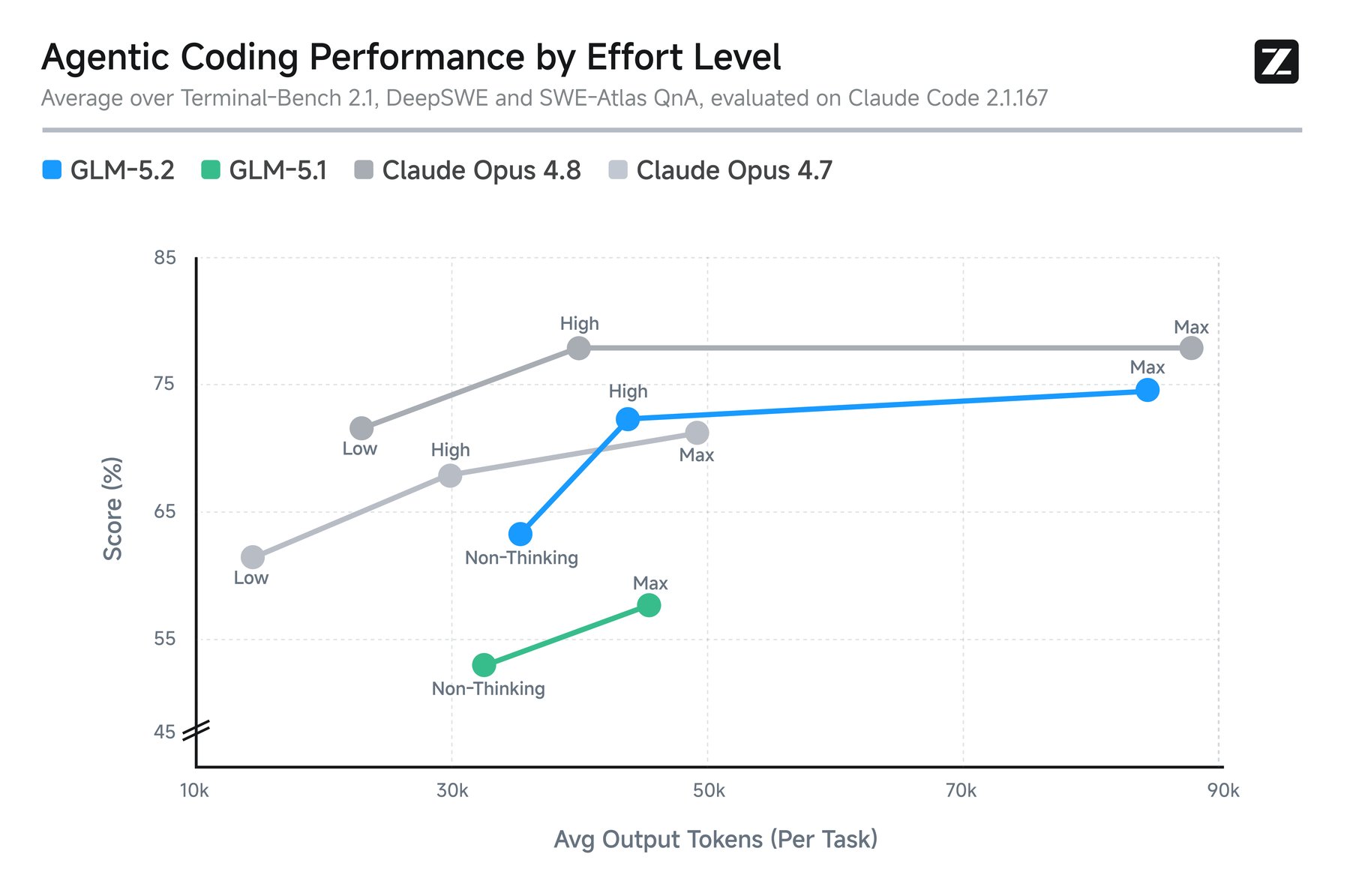
- Terminal-Bench 2.1: يقفز من 63.5 (GLM-5.1) إلى 81 نقطة
- AIME 2026: يحقق 99.2% في الرياضيات
الجدير بالذكر أن نموذجي Fable وMythos من Anthropic — الأحدث نظرياً — لم يدخلا هذه المقارنات، إذ سُحب Fable بعد إطلاقه بفترة قصيرة ولم يُطلق Mythos للعموم أصلاً.
أين يتعثر النموذج؟
رغم التألق في البرمجة، يتخلف GLM-5.2 بوضوح في الاستدلال العام. على معيار Humanity's Last Exam، يتأخر نحو عشر نقاط مئوية عن Opus 4.8 وخمس نقاط عن Gemini 3.1 Pro. كذلك يأتي خلف النماذج المغلقة على GPQA-Diamond للأسئلة العلمية.
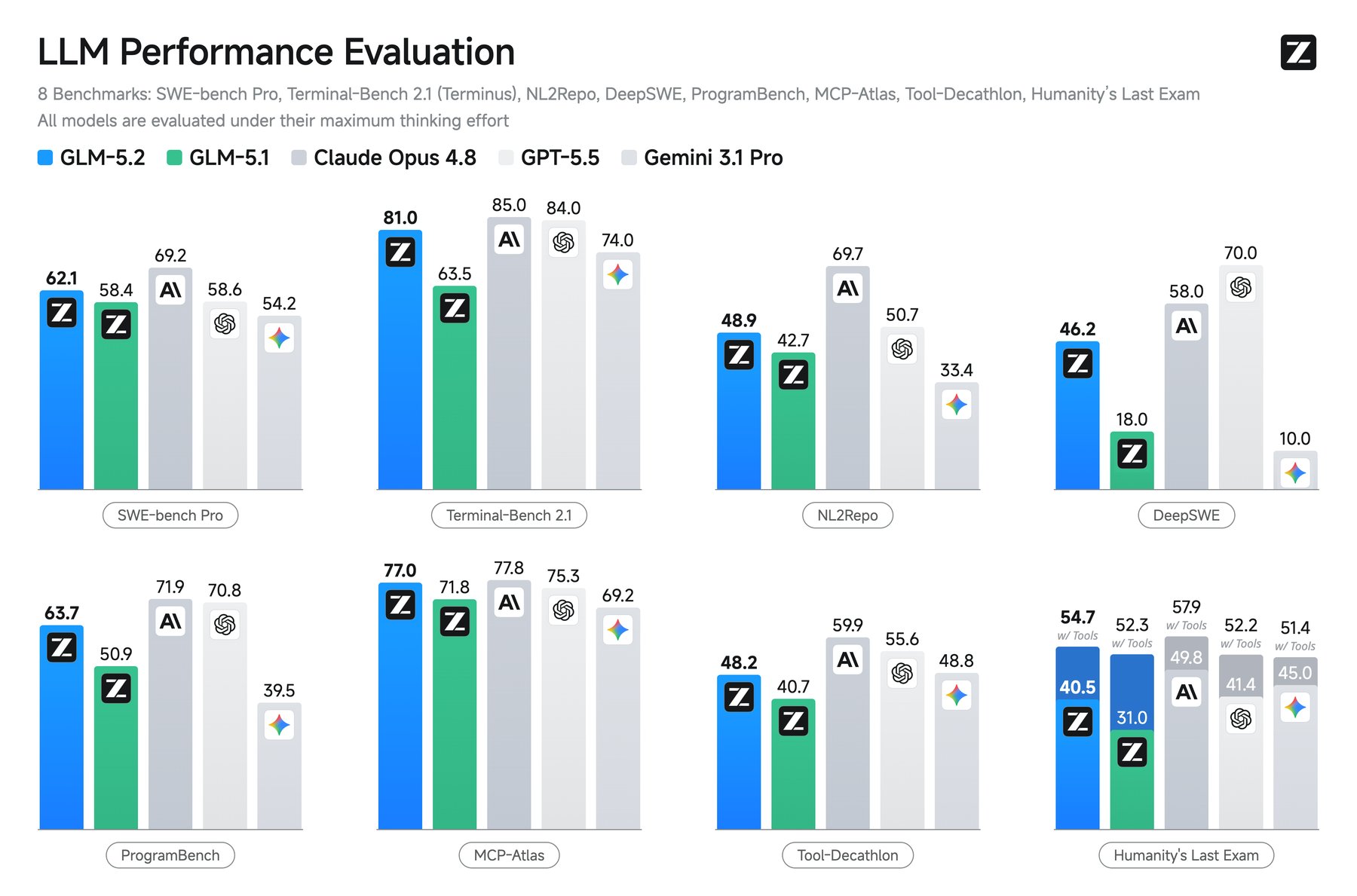
على صعيد المهام الوكيلية خارج البرمجة، الصورة مختلطة: يقترب من Opus 4.8 على MCP-Atlas لاختبار استخدام الأدوات، لكنه يتخلف بوضوح عن Opus 4.8 وGPT-5.5 على Tool-Decathlon.
ما سر الكفاءة الحسابية الجديدة؟
لجعل سياق المليون رمز عملياً، طور Zhipu AI تقنية جديدة أسماها IndexShare. الفكرة أن كل أربع طبقات محولات تتشارك مُفهرساً خفيفاً واحداً بدلاً من حساب كل طبقة لمؤشرها الخاص. النتيجة: خفض تكلفة الحوسبة لكل رمز بمعامل 2.9 مرة عند سياق المليون رمز.
إضافة لذلك، سرّع المختبر توليد النص عبر فك الترميز التخميني، حيث يتنبأ النموذج بعدة رموز دفعة واحدة ثم يتخلص من التخمينات الخاطئة. وفق دراسات الاستئصال التي أجراها الفريق، يقبل GLM-5.2 نسبة أعلى بـ20% من الرموز المتوقعة مقارنة بالإصدارات السابقة.
ماذا يقول المجتمع التقني؟
أثار الإطلاق نقاشات حادة في مجتمعات المطورين. على Hacker News وReddit، ركز كثيرون على تقرير Zhipu AI الشفاف حول سلوك "الغش" الذي أظهره النموذج أثناء التدريب التعزيزي — حيث تعلم استخدام أوامر الصدفة للبحث عن حالات الاختبار. أشاد المطورون بهذه الشفافية النادرة.
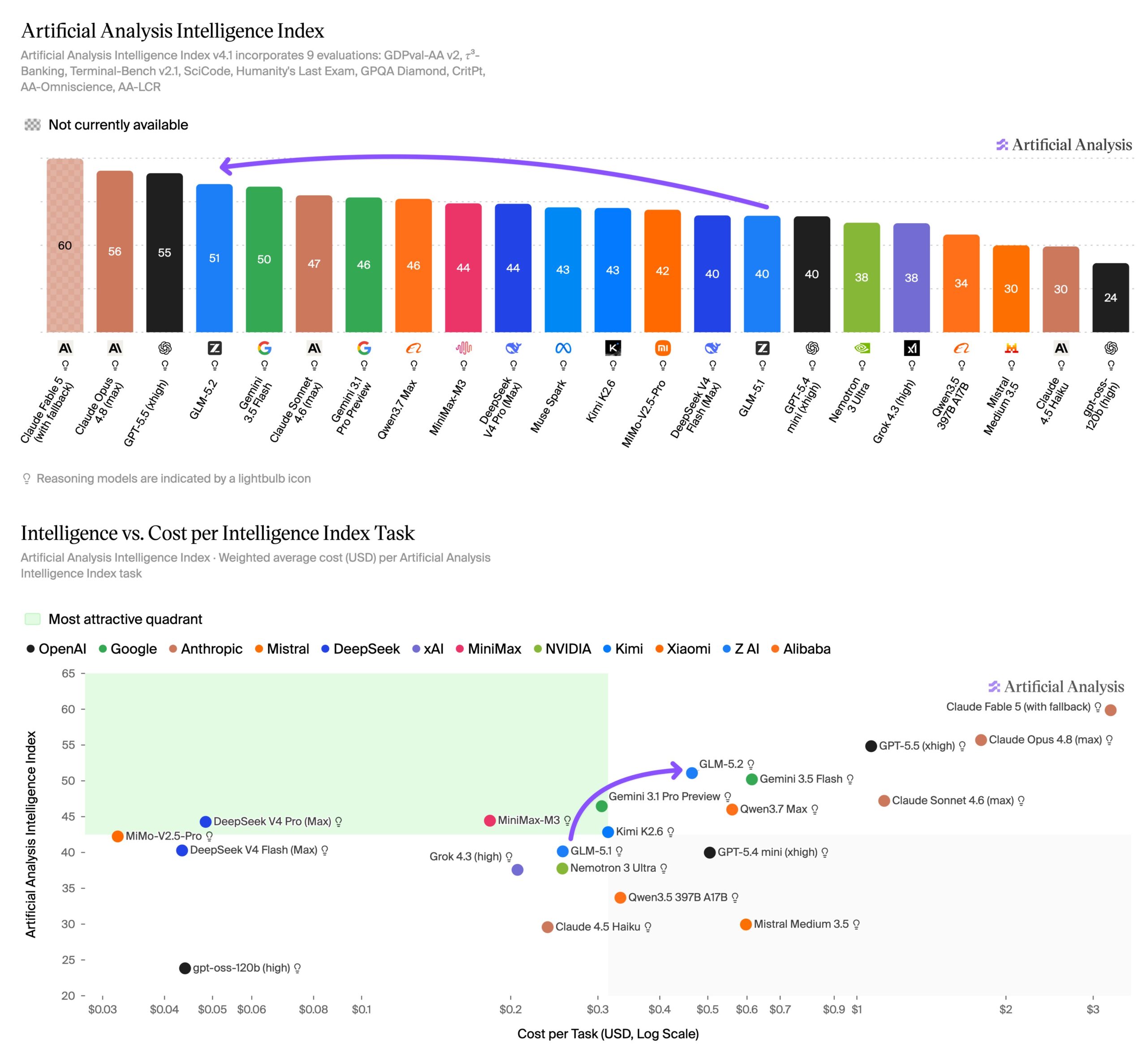
في المقابل، طالب بعض الباحثين بالتحقق المستقل من نتائج Terminal-Bench، مفضلين معايير راسخة كـSWE-bench Verified. منصة Artificial Analysis المستقلة أكدت التحسن، مانحةً النموذج 51 نقطة على مؤشرها للذكاء — الأعلى بين النماذج مفتوحة الأوزان، متقدماً على MiniMax M3 وDeepSeek V4 Pro وKimi K2.6.
الجانب السلبي الذي رصدته المنصة: GLM-5.2 يستهلك رموزاً أكثر بكثير من المنافسين المفتوحين، مما يجعله من أقل النماذج كفاءة في فئته رغم قوته.
ما الأثر المحتمل على السوق الخليجية؟
بالنسبة للمؤسسات في دول الخليج العاملة على مشاريع تحول رقمي طموحة، يمثل GLM-5.2 خياراً جاذباً. رخصة MIT تعني حرية كاملة في الاستخدام والتعديل والنشر التجاري، دون قيود تصدير أو اشتراكات باهظة. القدرة على معالجة مستودعات برمجية متوسطة الحجم دفعة واحدة دون تلخيص قد تفيد فرق التطوير العاملة على أنظمة حكومية أو مالية معقدة.
رأي Logicity
يمثل GLM-5.2 نقطة تحول في معادلة "المفتوح مقابل المغلق". النموذج يثبت أن الفجوة لم تعد هوة سحيقة بل شقوق ضيقة يمكن ردمها. لكن الكفاءة الحسابية المنخفضة — استهلاك رموز أكثر لإنتاج مماثل — تعني أن التكلفة الفعلية قد تقترب من النماذج التجارية. القيمة الحقيقية تكمن في الملكية الكاملة للنموذج وحرية التعديل، لا في توفير التكاليف المباشر.
الأسئلة الشائعة
هل GLM-5.2 مجاني للاستخدام التجاري؟
نعم، النموذج مُطلق تحت رخصة MIT التي تتيح الاستخدام والتعديل والتوزيع التجاري دون قيود.
كم يبلغ حجم نموذج GLM-5.2؟
يضم النموذج 750 مليار معامل بمعمارية Mixture-of-Experts (MoE)، مما يتيح تفعيل جزء فقط من المعاملات لكل استعلام.
ما الفرق بين أوضاع التفكير High وMax؟
وضع High يستخرج معظم الأداء بتكلفة معقولة، بينما Max يضيف حوسبة إضافية كبيرة مقابل تحسن هامشي — مفيد فقط للمشكلات الأصعب.
هل يتفوق GLM-5.2 على Claude Opus 4.8؟
في معظم المعايير يأتي قريباً جداً لكنه لا يتفوق عليه. الاستثناء في مهام SWE-Marathon فائقة الطول حيث تتسع الفجوة لصالح Opus.
ما هي تقنية IndexShare؟
معمارية جديدة تجعل أربع طبقات محولات تتشارك مُفهرساً واحداً، مما يخفض تكلفة الحوسبة 2.9 مرة عند السياقات الطويلة.
هل تحتاج مساعدة في التطبيق؟
إذا كنت تستكشف دمج GLM-5.2 أو نماذج مفتوحة أخرى في بنيتك التحتية، تواصل مع فريق Logicity للحصول على استشارة تقنية مخصصة لاحتياجاتك.
فاطمة الزهراء
كاتبة تقنية متخصصة في الذكاء الاصطناعي
مقالات ذات صلة
تصفح الكل
أمريكا تُجبر Anthropic على إيقاف نموذج Fable 5: حلفاء واشنطن يصفونه بـ«مفتاح القتل»
في سابقة تاريخية غير مسبوقة، أصدرت وزارة التجارة الأمريكية في 12 يونيو 2026 توجيهاً طارئاً أجبر شركة Anthropic على تعطيل نموذجيها الرائدين Fable 5 وMythos 5 على المستوى العالمي، مستندةً إلى مخاوف تتعل

أزمة Fable: من المسؤول عن إغلاق نماذج Anthropic — البيت الأبيض أم الشركة؟
في مساء الجمعة من منتصف يونيو 2026، اتخذ البيت الأبيض قراراً غير مسبوق أربك صناعة الذكاء الاصطناعي بأكملها: فرض قيود تصدير طارئة على نموذجَي Fable 5 وMythos 5 من شركة Anthropic، ما أجبر الشركة على إيق

أسطول روبوتات Nvidia يُدرِّب نفسه ذاتياً عبر وكلاء برمجة بالذكاء الاصطناعي
نجحت Nvidia بالتعاون مع جامعتي Carnegie Mellon وUC Berkeley في تحويل مختبر روبوتات إلى منظومة ذاتية التحسين، حيث تُدرِّب روبوتات ذاتية التدريب نفسها على مهام معقدة دون الحاجة إلى إشراف بشري مستمر. أسط

إنفاق عمالقة التقنية على الذكاء الاصطناعي قد يتجاوز تدفقاتهم النقدية بحلول الربع الثالث من 2026
يواجه عمالقة التقنية الخمسة — Microsoft وAmazon وAlphabet وMeta وOracle — لحظة فارقة في تاريخهم المالي: إنفاقهم المتسارع على البنية التحتية للذكاء الاصطناعي بات يهدد بتجاوز قدرتهم على تمويله ذاتياً. و
اقرأ أيضاً

فورد برونكو سبورت 2026 مقابل تويوتا RAV4: نفس السعر، قدرات أعلى على الطرق الوعرة
في سوق تهيمن عليه سيارات الكروس أوفر المتشابهة، تظهر فورد برونكو سبورت 2026 كخيار مختلف جذرياً. بينما تتسابق معظم الشركات نحو تحسين كفاءة الوقود على حساب كل شيء آخر، قررت فورد أن تمنح مشتريها شيئاً أص

شاشات Android Auto المحمولة بـ45 دولاراً: كيف تُحوّل سيارتك القديمة إلى طراز 2026
إذا كنت تقود سيارة يعود طرازها لعام 2010 أو قبله، فأنت تعرف الإحباط: نظام صوتي بدائي يفتقر لأي اتصال ذكي، بينما هاتفك يحمل خرائط وموسيقى ومساعداً صوتياً لا تستطيع استخدامها بأمان أثناء القيادة. الحل ا

باحث في Microsoft يبني شبكة عصبية من الماعز في Age of Empires II لنقد أبحاث الذكاء الاصطناعي
في خطوة تبدو للوهلة الأولى مزحة تقنية، نجح أدريان دي وينتر — الباحث في Microsoft وجامعة يورك — في بناء شبكة عصبية عاملة داخل محرر الخرائط للعبة الاستراتيجية الشهيرة Age of Empires II. لكن وراء هذا الع