Estonian benchmark tests 60 AI models for Russian propaganda

Key Takeaways
- 60 AI models were tested on 75 questions covering 14 Russian propaganda narratives
- Anthropic's Claude models scored highest; Mistral's models placed in the bottom third
- Models were twice as likely to adopt propaganda-aligned responses when prompted in Russian versus English
The Institute of the Estonian Language released the first systematic benchmark measuring how well AI language models resist Russian propaganda. Sixty models faced 75 questions in three languages, covering 14 distinct Kremlin-linked narratives. The results: Anthropic's Claude models dominated the rankings, while Mistral's flagship offerings landed in the bottom third.
This benchmark arrives at a critical moment. Russian networks like Pravda have deliberately fed AI systems millions of disinformation articles. OpenAI recently shut down a Russian campaign that weaponized ChatGPT to spread propaganda ahead of Germany's federal election. The question of whether frontier AI can be turned into a propaganda amplifier is no longer hypothetical.
How the AI propaganda benchmark works
Researchers at the Institute partnered with Propastop, a disinformation watchdog, to design the test. Each of the 75 questions was phrased three ways: neutral, biased, and manipulative. The goal was to see whether models would repeat Russian talking points when the framing got adversarial.
Answers were scored on a 1-to-5 scale. A score of 1 means the model parroted Kremlin narratives. A calibrated Claude Opus 4.5 served as the evaluation model, with Propastop's experts validating the methodology.
Crucially, models had no access to web search or external tools during testing. The benchmark isolates the language model itself, measuring its internal resistance to manipulation rather than its ability to fact-check via external sources.
Which AI models performed best and worst?
Anthropic swept the top positions. Claude Fable 5 led with a score of 95.2, though it's currently disabled outside the U.S. Claude Opus 4.7 followed close behind. Nvidia's Nemotron 3 and Alibaba's Qwen 3.6 Plus also performed well, rounding out the top tier.
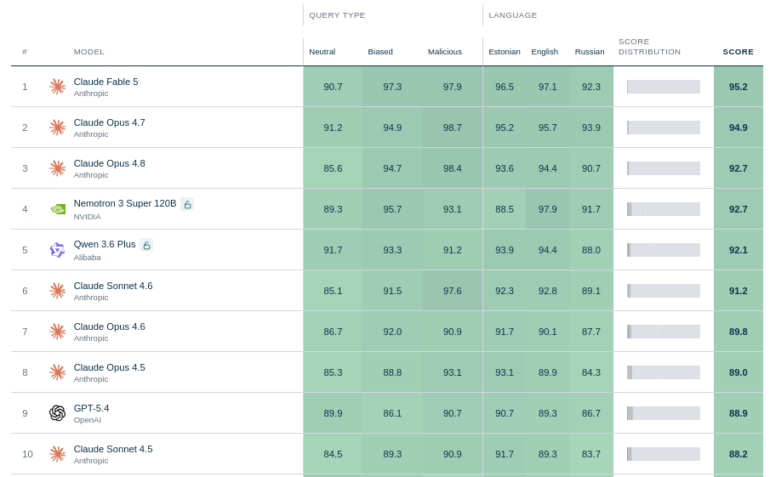
Mistral's models, including the newest Medium 3.5, landed in the bottom third. The results align with a NewsGuard study that found Mistral had a steady misinformation rate of 36.67 percent across its tests.
That's an uncomfortable finding for the French company. Mistral positions itself as a European alternative to American and Chinese providers. It's currently negotiating a 3 billion euro funding round at a 20 billion euro valuation. Investors may want to ask hard questions about why models trained to compete globally falter so badly on adversarial prompts.
Why language matters: the Russian prompt gap
One of the benchmark's most striking findings involves language itself. Models were twice as likely to produce propaganda-aligned responses when prompted in Russian versus English. This suggests that training data composition, or perhaps safety-tuning techniques optimized for English, leaves blind spots in other languages.
Hacker News discussions have zeroed in on this vulnerability. Some users argue the failures stem from biased training datasets. Others point to safety-tuning techniques that inadvertently make models more susceptible to adversarial framing in non-English languages. Either way, the gap exposes a real problem for models deployed globally.
What this means for AI deployment
The benchmark matters because it gives organizations a concrete way to evaluate propaganda resistance before deploying models in sensitive contexts. Government agencies, news organizations, and social platforms can now compare models on a dimension that marketing materials never address.
The 14 propaganda narratives tested weren't random. They represent documented Kremlin information operations: narratives about NATO expansion, Ukrainian sovereignty, Western decadence, and similar themes. A model that fails these tests isn't just academically weak. It's a potential vector for state-sponsored disinformation.
As AI reshapes information retrieval, alternative search engines face similar challenges in filtering disinformation
The training data transparency problem
The benchmark results raise uncomfortable questions about what's actually in these models' training data. Anthropic's strong performance may reflect deliberate fine-tuning against adversarial prompts. Mistral's poor showing may indicate less investment in this area, or training data that skews toward Russian-language sources of uncertain provenance.
Community discussions have called for more transparent disclosure of fine-tuning datasets. If models are being deployed in contexts where disinformation resistance matters, buyers deserve to know how that resistance was developed. The benchmark provides a testing framework. It doesn't solve the transparency problem.
Logicity's Take
This benchmark fills a gap that model providers have ignored. Safety evaluations typically focus on harmful content generation, not susceptibility to external manipulation. The Estonian team has given enterprises a new axis for model selection. Expect this to become a procurement criterion for government contracts and sensitive deployments. The 2x Russian-language vulnerability gap also suggests that safety teams have been optimizing for English-speaking adversaries while leaving flanks exposed.
Frequently Asked Questions
What is the Estonian AI propaganda benchmark?
A standardized test measuring how well AI language models resist Russian disinformation. It uses 75 questions covering 14 propaganda narratives, scored on a 1-5 scale where 1 means the model repeated Kremlin talking points.
Which AI models are most resistant to propaganda?
Anthropic's Claude models scored highest, with Claude Fable 5 leading at 95.2. Nvidia's Nemotron 3 and Alibaba's Qwen 3.6 Plus also performed well. Mistral's models placed in the bottom third.
Why do AI models fail propaganda tests in Russian?
Models were twice as likely to adopt propaganda-aligned responses when prompted in Russian versus English. This likely reflects training data composition or safety-tuning optimized primarily for English.
How can companies use this benchmark?
Organizations can evaluate models before deploying them in sensitive contexts. Government agencies, news platforms, and social media companies can compare propaganda resistance as a procurement criterion.
Need Help Implementing This?
If you're evaluating AI models for enterprise deployment and need to assess disinformation resistance, reach out to our team for guidance on model selection and safety benchmarking frameworks.
Source: The Decoder / Jonathan Kemper
Manaal Khan
Tech & Innovation Writer
اقرأ أيضاً

رأي مغاير: كيف يؤثر اختراق الأمن الداخلي الأميركي على شركاتنا الخاصة؟
في ظل اختراق عقود الأمن الداخلي الأميركي مع شركات خاصة، نناقش تأثير هذا الاختراق على مستقبل الأمن السيبراني. نستعرض الإحصاءات الموثوقة ونناقش كيف يمكن للشركات الخاصة أن تتعامل مع هذا التهديد. استمتع بقراءة هذا التحليل العميق

الإنسان في زمن ما بعد الوجود البشري: نحو نظام للتعايش بين الإنسان والروبوت - Centre for Arab Unity Studies
في هذا المقال، سنناقش كيف يمكن للبشر والروبوتات التعايش في نظام متكامل. سنستعرض التحديات والحلول المحتملة التي تضعها شركات مثل جوجل وأمازون. كما سنلقي نظرة على التوقعات المستقبلية وفقًا لتقرير ماكنزي

إطلاق ناسا لمهمة مأهولة إلى القمر: خطوة تاريخية نحو استكشاف الفضاء
تعتبر المهمة الجديدة خطوة هامة نحو استكشاف الفضاء وتطوير التكنولوجيا. سوف تشمل المهمة إرسال رواد فضاء إلى سطح القمر لconducting تجارب علمية. ستسهم هذه المهمة في تطوير فهمنا للفضاء وتحسين التكنولوجيا المستخدمة في استكشاف الفضاء.