
A recent study by Google Research and the Rochester Institute of Technology has shaken the foundations of AI benchmarking, revealing that current methods are systematically ignoring human disagreements. The study highlights the need for a more robust approach to evaluating AI models. With thousands of budget combinations tested, the researchers provide a roadmap for more reliable AI benchmarks.
Key Takeaways
- Current AI benchmarking methods are flawed and ignore human disagreements
- At least 10 human evaluators are needed per test example for reliable results
- The ideal distribution of annotation budget depends on the evaluation goal
In This Article
- The Problem with Current AI Benchmarking Methods
- The Google Study: A New Approach to AI Benchmarking
- Why Human Evaluators Matter in AI Benchmarking
- The Future of AI Benchmarking: Implications and Directions
- Real-World Applications: How Better AI Benchmarking Can Impact Society
- Conclusion: The Road Ahead for AI Benchmarking
The Problem with Current AI Benchmarking Methods
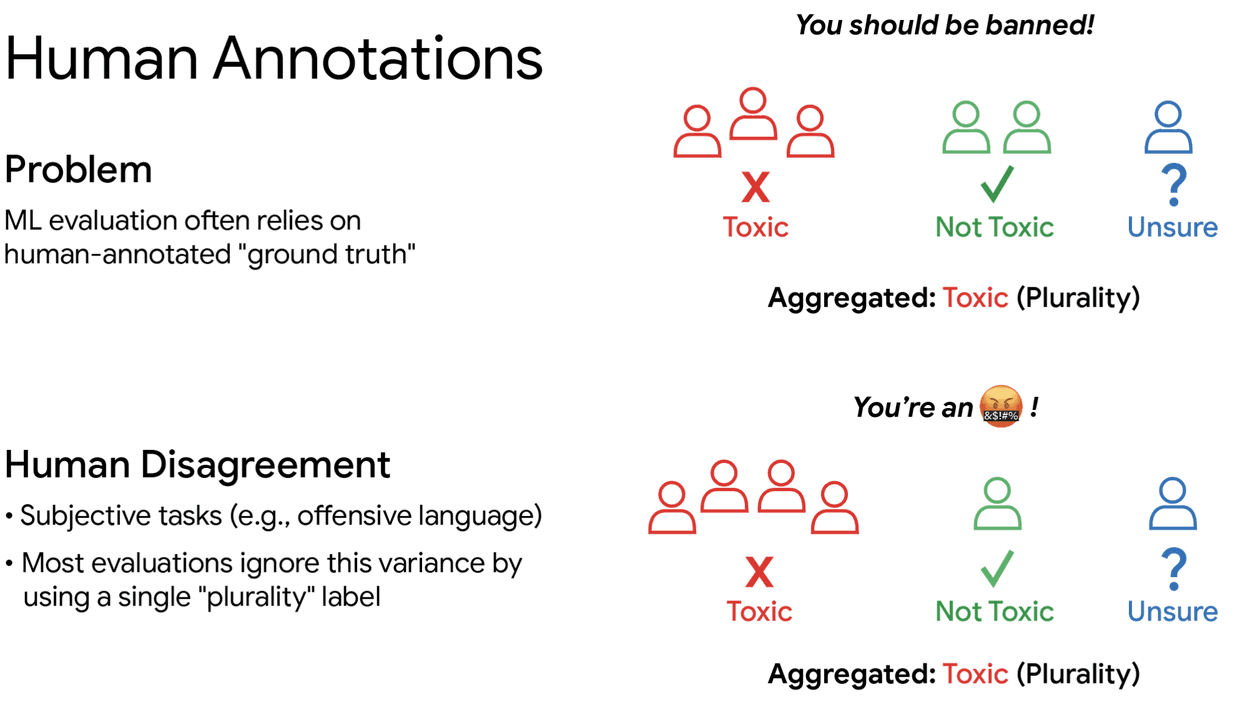
When it comes to evaluating AI models, human judgment plays a crucial role. However, the standard practice of using a small number of human evaluators per test example has been found to be insufficient. This approach throws out the diversity of human opinion, leading to unreliable outcomes.
- Human evaluators often disagree on the correctness of AI-generated responses
- Current methods use a majority vote to determine the correct answer, ignoring the diversity of human opinion

The Google Study: A New Approach to AI Benchmarking
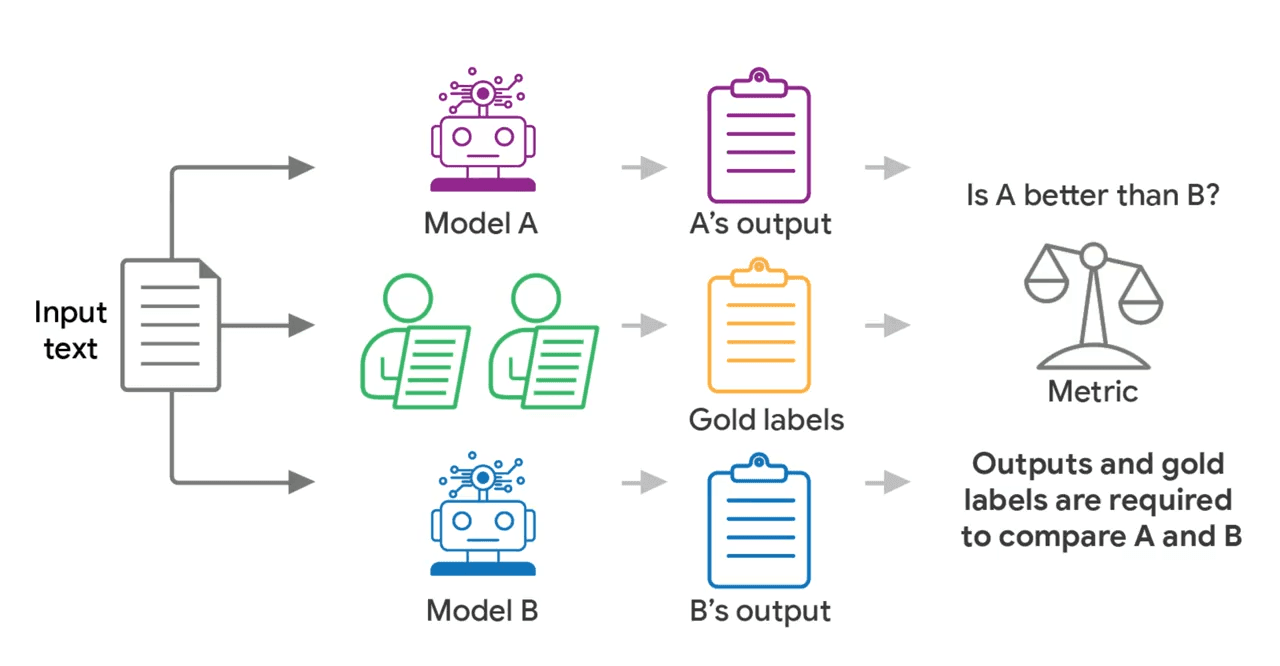
Researchers from Google and the Rochester Institute of Technology set out to find a more reliable way to evaluate AI models. They built a simulator that replicates human rating patterns and tested thousands of budget combinations to find the sweet spot.
- The study used real datasets to calibrate the simulator and test different evaluation methods
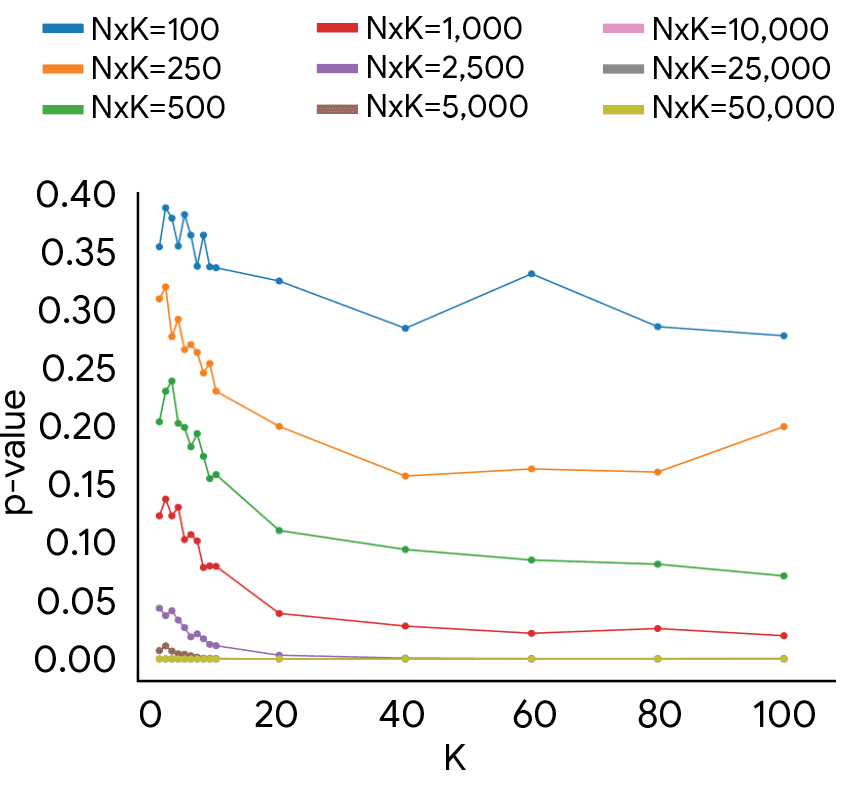
- The results show that using fewer than 10 human evaluators per test example is not sufficient for reliable results
Why Human Evaluators Matter in AI Benchmarking
Human evaluators bring a level of nuance and understanding to AI evaluations that machines currently cannot match. However, the number of human evaluators needed to achieve reliable results is a critical factor in AI benchmarking.
- More human evaluators per test example leads to more reliable detection of differences between models
- The ideal distribution of annotation budget depends on the evaluation goal, such as majority-vote evaluations or capturing the full diversity of human opinion
The Future of AI Benchmarking: Implications and Directions
The study's findings have significant implications for the field of AI research and development. As AI models become increasingly complex and ubiquitous, the need for reliable benchmarking methods has never been more pressing.
- The study's results highlight the need for a more nuanced approach to AI evaluation, taking into account the diversity of human opinion
- Future research should focus on developing more robust and reliable methods for AI benchmarking, incorporating the insights from this study
Real-World Applications: How Better AI Benchmarking Can Impact Society
The impact of better AI benchmarking methods will be felt across various industries and aspects of society, from healthcare and education to transportation and entertainment.
- More reliable AI models can lead to improved decision-making and outcomes in critical areas such as healthcare and finance
- Better AI benchmarking can also facilitate the development of more transparent and explainable AI systems, addressing concerns around accountability and trust
Conclusion: The Road Ahead for AI Benchmarking
The Google study has shed light on the limitations of current AI benchmarking methods and provided a roadmap for improvement. As the field of AI continues to evolve, it is essential to prioritize the development of more reliable and robust evaluation methods.
- The study's findings emphasize the need for a more comprehensive approach to AI evaluation, incorporating the diversity of human opinion
- By adopting more robust benchmarking methods, we can unlock the full potential of AI and drive innovation in various fields
“Ask about this article”
— THE DECODER
Final Thoughts
As we move forward in the development and deployment of AI systems, it is crucial to recognize the importance of reliable benchmarking methods. By acknowledging the limitations of current approaches and embracing more robust evaluation techniques, we can ensure that AI technologies are developed and used responsibly, for the benefit of society as a whole.
Sources & Credits
Originally reported by The Decoder — Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






