
Alibaba's latest AI model, Qwen3.5-Omni, is a game-changer in the tech world. This omnimodal AI can process text, images, audio, and video, and has even learned to write code from spoken instructions and video input without any training. With its impressive capabilities, Qwen3.5-Omni is set to revolutionize the way we interact with technology.
Key Takeaways
- Qwen3.5-Omni is an omnimodal AI model that can process multiple types of data
- It can write code from spoken instructions and video input without training
- The model outperforms Google's Gemini 3.1 Pro in audio tasks
In This Article
- Introduction to Qwen3.5-Omni
- The Impressive Capabilities of Qwen3.5-Omni
- Qwen3.5-Omni vs Google's Gemini 3.1 Pro
- Qwen3.5-Omni's Code Writing Capabilities
- Qwen3.5-Omni's Language Support
- The Future Implications of Qwen3.5-Omni
Introduction to Qwen3.5-Omni
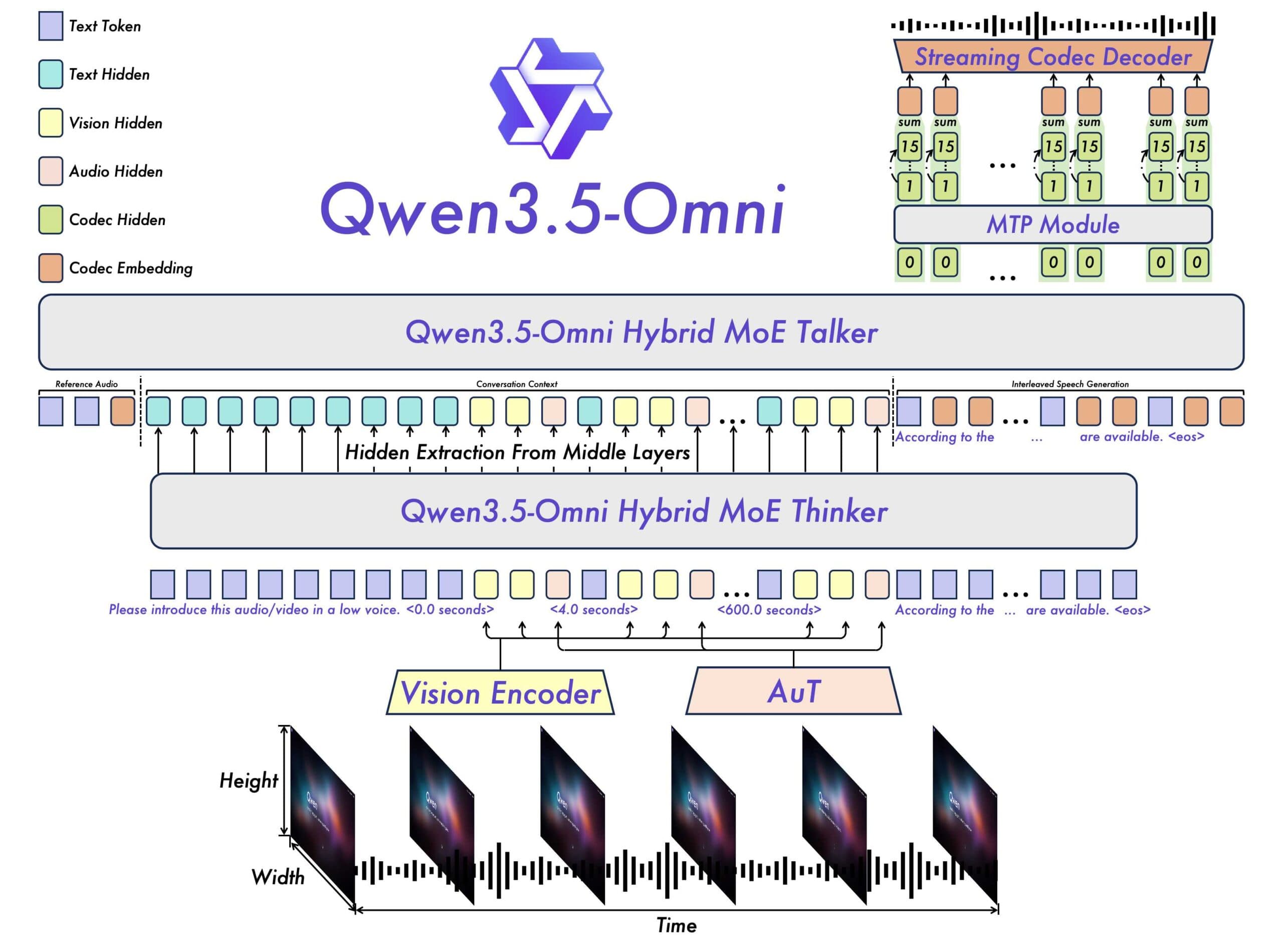
The tech world is abuzz with the latest release from Alibaba - Qwen3.5-Omni, an AI model that's being touted as a game-changer. But what makes this model so special? Let's dive in and find out.
- Qwen3.5-Omni is an omnimodal AI model, meaning it can process multiple types of data, including text, images, audio, and video.
- It's available in three different variants: Plus, Flash, and Light.

The Impressive Capabilities of Qwen3.5-Omni
So, what can Qwen3.5-Omni actually do? The answer is - a lot. From speech recognition to code writing, this model is packed with features that are set to revolutionize the way we interact with technology.
- Qwen3.5-Omni can process over 10 hours of audio and 400 seconds of 720p video at one frame per second.
- It can generate speech output alongside text, making it a versatile tool for a range of applications.
Qwen3.5-Omni vs Google's Gemini 3.1 Pro
But how does Qwen3.5-Omni stack up against the competition? Let's take a look at how it compares to Google's Gemini 3.1 Pro.
- Qwen3.5-Omni outperforms Gemini 3.1 Pro in audio tasks, with a score of 82.2 in audio comprehension compared to Gemini's 81.1.
- It also beats Gemini in music comprehension, with a score of 72.4 versus 59.6.

Qwen3.5-Omni's Code Writing Capabilities
One of the most impressive features of Qwen3.5-Omni is its ability to write code from spoken instructions and video input. But how does it do it?
- Qwen3.5-Omni uses a combination of natural language processing and machine learning algorithms to understand spoken instructions and generate code.
- It can write code in a range of programming languages, making it a valuable tool for developers.
Qwen3.5-Omni's Language Support
Another area where Qwen3.5-Omni shines is in its language support. With the ability to recognize and generate speech in multiple languages, it's a truly global AI model.
- Qwen3.5-Omni supports speech recognition in 74 languages and 39 Chinese dialects.
- It can also generate speech output in 36 languages and dialects, with 55 voices available.
The Future Implications of Qwen3.5-Omni
So, what does the future hold for Qwen3.5-Omni? With its impressive capabilities and range of applications, it's set to have a significant impact on the tech world.
- Qwen3.5-Omni has the potential to revolutionize the way we interact with technology, from voice assistants to code development.
- It could also enable new applications and services that we haven't yet imagined.
“The model was natively pre-trained as omnimodal on over 100 million hours of audiovisual material.”
— Qwen team
Final Thoughts
In conclusion, Qwen3.5-Omni is a revolutionary AI model that's set to change the way we interact with technology. With its impressive capabilities, range of applications, and potential for future development, it's an exciting time for the tech world. As we look to the future, it will be interesting to see how Qwen3.5-Omni continues to evolve and improve, and what new applications and services it will enable.
Sources & Credits
Originally reported by Unknown — Jonathan Kemper

Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






