
Alibaba's latest AI model, Qwen3.5-Omni, has made a groundbreaking achievement by learning to write code from spoken instructions and videos without any prior training. This omnimodal AI model can process text, images, audio, and video, and has outperformed Google's Gemini 3.1 Pro in audio tasks. With its massive language support and advanced speech recognition capabilities, Qwen3.5-Omni is set to revolutionize the tech industry.
Key Takeaways
- Qwen3.5-Omni can write code from spoken instructions and videos
- The model outperforms Google's Gemini 3.1 Pro in audio tasks
- It supports 74 languages and 39 Chinese dialects for speech recognition
In This Article
- Introduction to Qwen3.5-Omni
- Groundbreaking Capabilities of Qwen3.5-Omni
- Massive Language Support
- Technical Achievements of Qwen3.5-Omni
- Future Implications of Qwen3.5-Omni
- Conclusion and Future Outlook
Introduction to Qwen3.5-Omni
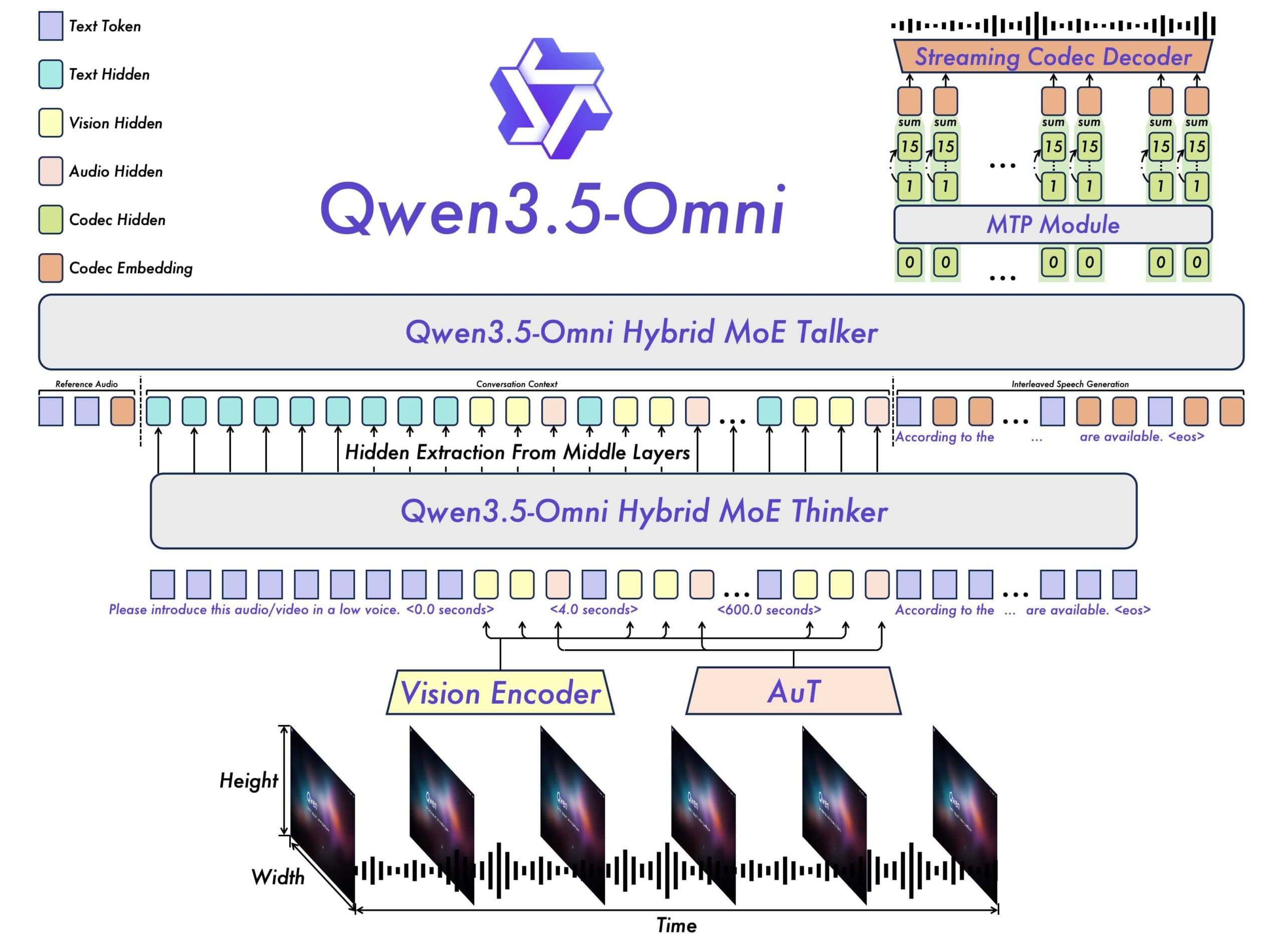
The latest AI model from Alibaba, Qwen3.5-Omni, has been making waves in the tech industry with its unprecedented capabilities. This omnimodal AI model can process text, images, audio, and video, and has been trained on over 100 million hours of audiovisual material.
- Qwen3.5-Omni can handle contexts up to 256,000 tokens
- It can process more than ten hours of audio and over 400 seconds of 720p video at one frame per second

Groundbreaking Capabilities of Qwen3.5-Omni
One of the most impressive features of Qwen3.5-Omni is its ability to write code from spoken instructions and videos. This capability has the potential to revolutionize the way we interact with computers and develop software.
- Qwen3.5-Omni can generate speech output alongside text
- It has outperformed Google's Gemini 3.1 Pro in overall audio comprehension, reasoning, recognition, translation, and dialog
Massive Language Support
Qwen3.5-Omni has expanded its language support significantly, with speech recognition now covering 74 languages and 39 Chinese dialects. This is a massive jump from its predecessor, which handled only 11 languages and 8 Chinese dialects.
- The model supports 36 languages and dialects for voice output
- It has 55 voices available, including user-defined, scenario-specific, dialectal, and multilingual options

Technical Achievements of Qwen3.5-Omni
Qwen3.5-Omni has achieved state-of-the-art results in several audio and audiovisual benchmarks. Its technical capabilities are a testament to the advancements in AI research and development.
- The model has scored 82.2 in audio comprehension (MMAU) versus 81.1 for Gemini 3.1 Pro
- It has achieved a word error rate of 6.24 on the tough 'seed-hard' test set
Future Implications of Qwen3.5-Omni
The release of Qwen3.5-Omni has significant implications for the future of AI research and development. Its capabilities have the potential to revolutionize various industries, from software development to customer service.
- Qwen3.5-Omni can enable more efficient and effective human-computer interaction
- Its language support and speech recognition capabilities can facilitate communication across languages and cultures
Conclusion and Future Outlook
In conclusion, Qwen3.5-Omni is a revolutionary AI model that has the potential to transform the tech industry. Its groundbreaking capabilities, massive language support, and technical achievements make it an exciting development in the field of AI research.
- Qwen3.5-Omni is set to revolutionize the way we interact with computers and develop software
- Its release has significant implications for the future of AI research and development
“Qwen3.5-Omni-Plus claims state of the art across 215 audio benchmarks”
— Qwen team
Final Thoughts
As we move forward, it will be exciting to see how Qwen3.5-Omni is used in various industries and applications. With its unprecedented capabilities and massive language support, this AI model has the potential to revolutionize the way we live and work. As AI research continues to advance, we can expect to see even more innovative and groundbreaking developments in the future.
Sources & Credits
Originally reported by Unknown — Jonathan Kemper

Huma Shazia
Senior AI & Tech Writer
Produced with AI assistance and reviewed by the Logicity editorial team. Learn more in our Editorial Policy.






