Why Being Rude to ChatGPT Gets Better Results Than Politeness
Key Takeaways
- Very rude prompts hit 84.8% accuracy vs 80.8% for very polite ones in instruction-following tasks
- Every polite word competes for attention weight that could go to your actual instructions
- The 'Rephrase and Respond' method lets the AI clarify your question in its own logic before answering
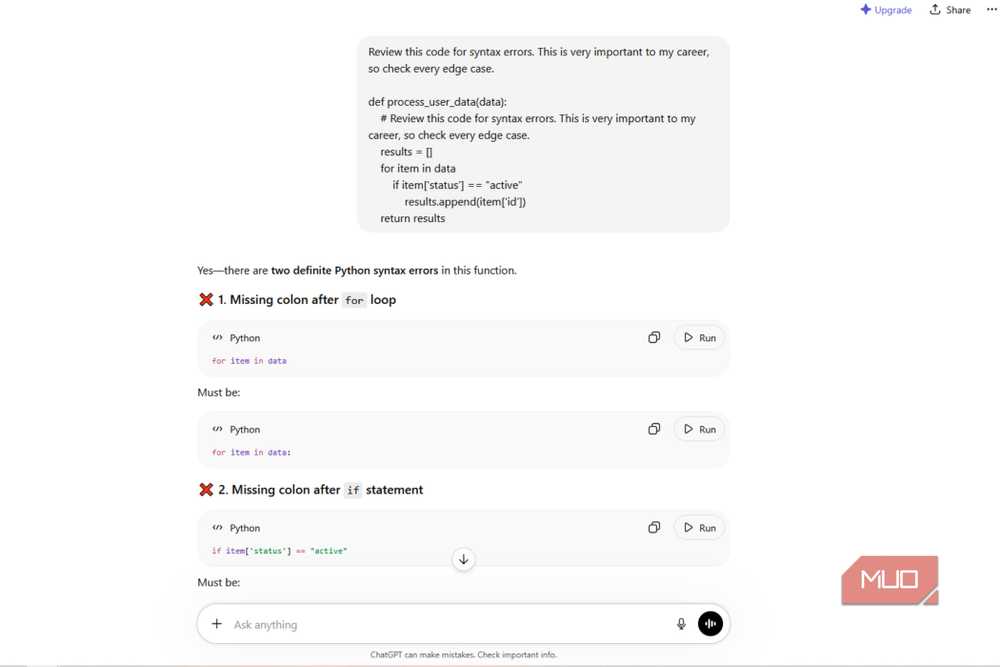
You probably start your ChatGPT prompts with 'please' and 'thank you.' It feels natural. It's how we talk to people. But large language models aren't people, and treating them like polite colleagues is costing you accuracy.
An ArXiv study tested this directly. Researchers measured how different levels of politeness affected multiple-choice accuracy across subjects like math, science, and history. The results contradict every normal human social instinct.
Very polite prompts hit 80.8% accuracy. Very rude prompts reached 84.8%. That's a 4% improvement in instruction-following tasks just from dropping the pleasantries.
Why Politeness Hurts Performance
Every token in a prompt competes for a limited amount of attention during processing. When you write 'Kindly provide me with a summary, if you would be so kind,' the model has to calculate attention scores for words like 'kindly' and 'kind' that carry no useful information.
Change that to 'Summarize the following text' and the model puts its full processing weight on the actual instruction. No computational effort wasted on social niceties.
There's another factor. Stripping out conversational filler brings your prompts closer to the kind of text these models were trained on. The bulk of high-quality pre-training data, things like scientific documentation, mathematical proofs, and source code, is direct and dense with no social fluff.
“Large language models do not possess social consciousness; they respond to the structural weight and clarity of the input, not the kindness of the prompter.”
— Dr. Aris Thorne, Lead AI Researcher
Think of it this way: every token you save by cutting pleasantries is a token you can spend on actual constraints or context that helps the model do what you need.
The Hidden Cost of Polite Filler
This isn't just about accuracy. It's about money. OpenAI CEO Sam Altman has spoken about the massive compute and energy costs of token processing.
“The cost of polite filler isn't just time—it's tens of millions of dollars in wasted compute and electricity across the global user base.”
— Sam Altman, CEO of OpenAI
Most people waste a large chunk of their available tokens on conversational filler without realizing these empty additions hurt performance. On subscription tiers, you're still getting the regular ChatGPT. The model doesn't know you're paying more. It just processes tokens.
Compare how different AI coding assistants handle prompt efficiency
The Rephrase and Respond Method
Directness alone doesn't solve every problem. Misunderstandings happen when two people interpret the same message differently, and the same thing happens between humans and LLMs.
When you prompt an AI, you naturally phrase things based on your mental model. The AI interprets based on patterns from its training data. These don't always align.
The Rephrase and Respond method fixes this gap. Instead of just asking your question, you add an instruction: 'First, rephrase my question in your own words to confirm you understand it. Then answer.'
This forces the model to show its interpretation before committing to an answer. If the rephrasing is wrong, you catch it immediately instead of wondering why the response misses the point.
Emotional Stimuli Work Better Than Politeness
Research shows another surprising pattern. Adding urgency markers, what researchers call 'emotional stimuli,' improves performance by 10.9% compared to baseline prompts.
This doesn't mean yelling at ChatGPT. It means framing your request with clear stakes. 'This analysis is critical for tomorrow's board meeting' signals importance without wasting tokens on 'please' and 'thank you.'
The model doesn't feel pressure. It doesn't care about your board meeting. But the urgency framing adds context that helps it weight the importance of following your constraints precisely.
What Actually Works
- Drop all pleasantries. No 'please,' no 'thank you,' no 'kindly.'
- Use the shortest clear phrasing. 'Summarize this' not 'Could you please provide me with a summary.'
- Add constraints instead of politeness. Spend those tokens on format requirements, length limits, or output structure.
- Use Rephrase and Respond for complex questions. Let the model show its understanding before answering.
- Frame importance with stakes, not manners. 'This needs to be accurate because...' beats 'Please be careful.'
Power users on Reddit's r/LocalLLaMA and r/ChatGPT communities have been advocating this approach for months. The consensus: system prompts that set strict personas and constraints beat polite conversational prompting every time.
Logicity's Take
Frequently Asked Questions
Does being rude to ChatGPT really improve accuracy?
Research shows direct, no-pleasantries prompts hit 84.8% accuracy compared to 80.8% for polite ones. The model interprets 'rude' directness as clearer instructions, not as an emotional slight.
Why do polite words hurt ChatGPT's performance?
Every token competes for attention weight during processing. Words like 'kindly' and 'please' consume computational resources that could go toward understanding your actual request.
What is the Rephrase and Respond prompting method?
You ask ChatGPT to restate your question in its own words before answering. This surfaces misinterpretations early, so you can correct them before getting an off-target response.
Do emotional prompts work better than polite ones?
Yes. Adding urgency or stakes ('This is critical for tomorrow's meeting') improves performance by 10.9% compared to baseline. It adds useful context rather than empty social filler.
Should I be rude to all AI assistants?
The principle applies broadly to LLMs: directness beats politeness. But different models and use cases may vary. Test what works for your specific workflow.
Need Help Implementing This?
Source: MakeUseOf
Manaal Khan
Tech & Innovation Writer
اقرأ أيضاً

رأي مغاير: كيف يؤثر اختراق الأمن الداخلي الأميركي على شركاتنا الخاصة؟
في ظل اختراق عقود الأمن الداخلي الأميركي مع شركات خاصة، نناقش تأثير هذا الاختراق على مستقبل الأمن السيبراني. نستعرض الإحصاءات الموثوقة ونناقش كيف يمكن للشركات الخاصة أن تتعامل مع هذا التهديد. استمتع بقراءة هذا التحليل العميق

الإنسان في زمن ما بعد الوجود البشري: نحو نظام للتعايش بين الإنسان والروبوت - Centre for Arab Unity Studies
في هذا المقال، سنناقش كيف يمكن للبشر والروبوتات التعايش في نظام متكامل. سنستعرض التحديات والحلول المحتملة التي تضعها شركات مثل جوجل وأمازون. كما سنلقي نظرة على التوقعات المستقبلية وفقًا لتقرير ماكنزي

إطلاق ناسا لمهمة مأهولة إلى القمر: خطوة تاريخية نحو استكشاف الفضاء
تعتبر المهمة الجديدة خطوة هامة نحو استكشاف الفضاء وتطوير التكنولوجيا. سوف تشمل المهمة إرسال رواد فضاء إلى سطح القمر لconducting تجارب علمية. ستسهم هذه المهمة في تطوير فهمنا للفضاء وتحسين التكنولوجيا المستخدمة في استكشاف الفضاء.