Univariate Analysis: Find Data Problems Before They Cost You
Key Takeaways
- Univariate analysis catches 60-80% of data quality issues before they corrupt downstream models
- Skipped data inspection is a leading cause of failed analytics projects, costing companies millions in bad decisions
- Simple histogram and box plot checks take hours but can save months of rework
According to [DEV Community's tutorial on univariate analysis](https://dev.to/shivappa/eda-part-3-univariate-analysis-understanding-every-feature-one-at-a-time-50aa), examining each variable in your dataset individually is the foundation of any reliable analytics project. The technique, part of exploratory data analysis (EDA), catches problems that would otherwise corrupt your models and lead to expensive business mistakes.
Here's a number that should concern every executive: Gartner estimates that poor data quality costs organizations an average of $12.9 million annually. Much of that waste traces back to analytics teams rushing into complex analysis without first checking each variable individually. Univariate analysis is the unsexy but critical step that prevents those losses.
What Is Univariate Analysis and Why Should Executives Care?
Univariate analysis means examining one variable at a time. That's it. Before your data team starts looking for correlations between customer age and spending patterns, they need to understand what the age column actually looks like. Are there impossible values like negative ages? Are there outliers that will skew your averages? Is the data distributed normally, or is it bunched up in unexpected ways?
Think of it like a quality inspector at a fruit market. Before comparing apples to oranges, you check each fruit individually. Is this apple bruised? Is this mango overripe? You're not making comparisons yet. You're catching problems before they contaminate your entire analysis.
Executive Summary
Univariate analysis is a 2-4 hour investment that prevents weeks of rework. It identifies outliers, data entry errors, and hidden subgroups before they corrupt your models. Skip it, and your analytics team will likely deliver insights based on flawed assumptions.
How Does Univariate Analysis Prevent Analytics Failures?
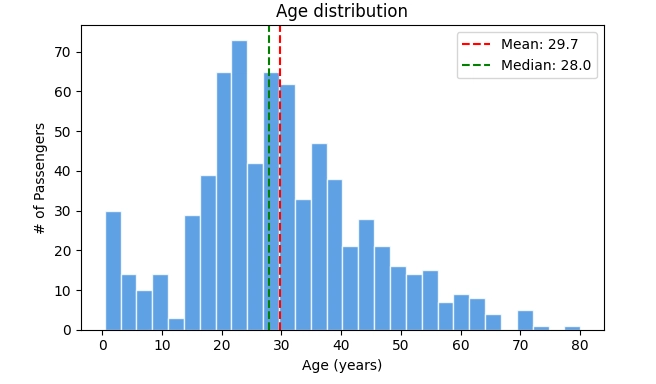
The DEV Community tutorial uses a practical example: analyzing passenger data from the Titanic dataset. When examining the Age column, the analysis reveals whether the distribution is symmetric (healthy), skewed (needs transformation), or bimodal (contains hidden subgroups). Each pattern requires different handling, and missing these patterns leads to flawed conclusions.
| Data Pattern | What It Means | Business Impact If Ignored |
|---|---|---|
| Mean ≈ Median | Symmetric distribution, data is healthy | None, proceed with standard analysis |
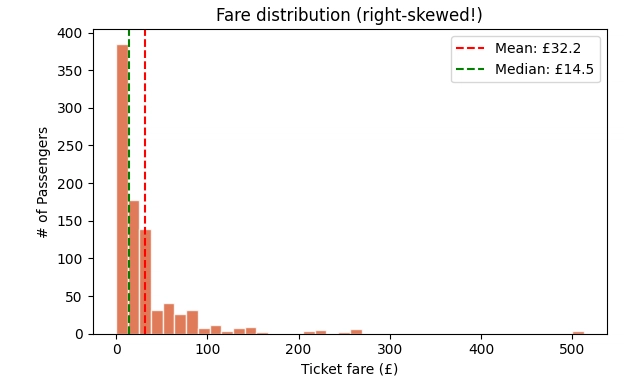
| Mean >> Median | Right-skewed data with outliers pulling average up | Your averages will overstate reality, leading to optimistic projections |
| Mean << Median | Left-skewed data with outliers pulling average down | Your averages will understate reality, leading to pessimistic projections |
| Two peaks (bimodal) | Two distinct groups lumped together | You're analyzing a blended population as if it were one, missing segment-specific insights |
| Extreme outliers | Data entry errors or genuine anomalies | A few bad records can corrupt your entire model's predictions |
Consider a real-world scenario: a retail company analyzing customer purchase amounts. If the data is right-skewed because a few high-value customers spend significantly more than average, standard averaging will suggest typical customers spend more than they actually do. Marketing campaigns based on this inflated average will miss the mark. Univariate analysis catches this before campaigns launch.
What Tools Do Data Teams Use for Univariate Analysis?
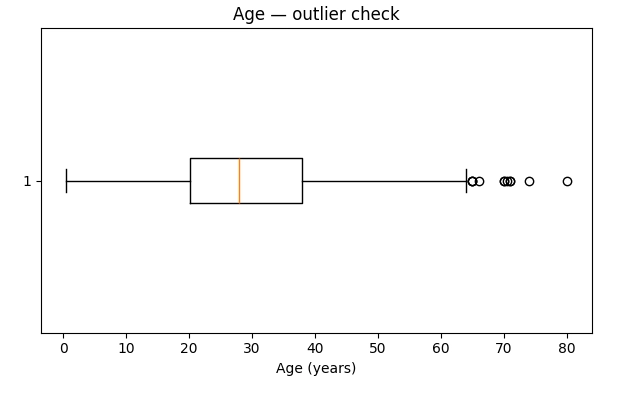
The primary tools are histograms and box plots. Histograms show the shape of data distribution. Is it bell-curved? Skewed? Does it have multiple peaks? Box plots reveal outliers instantly. Those dots sitting far from the box represent values that need investigation.
The technical implementation takes minutes with Python libraries like matplotlib. But the interpretation is where business value gets created. A histogram showing two distinct peaks in customer age data might reveal that your 'general audience' product actually serves two completely different demographics. That insight changes marketing strategy, product development, and customer service approaches.
How Much Does Skipping Data Inspection Actually Cost?
IBM's estimate puts the cost of bad data at $3.1 trillion annually in the US alone. That's not all from skipped univariate analysis, but a significant portion traces back to teams building models on unexamined data. The failure mode is predictable: a data science team spends three months building a predictive model, presents it to leadership, deploys it, and then discovers the model's predictions are wildly off because no one noticed the training data contained impossible values.
The rework isn't just expensive in terms of salaries. It's the opportunity cost. While your team rebuilds a model they should have built correctly the first time, competitors who invested in proper data inspection are already acting on reliable insights.
How AI-assisted development tools help catch data issues faster
What Questions Should CTOs Ask Their Data Teams?
Before your next analytics presentation, ask your data science lead: 'Did you run univariate analysis on each variable? What did the distributions look like? Were there outliers, and how did you handle them?' If the answer is vague or dismissive, you have a process problem that will eventually become a business problem.
- What percentage of values were missing in each column, and how did you handle missingness?
- Were any distributions skewed, and did you apply transformations?
- Did you find bimodal distributions suggesting hidden subgroups?
- How many outliers did you identify, and did you investigate their source?
- Can you show me the histograms and box plots for key business variables?
These aren't gotcha questions. They're the basic hygiene checks that separate reliable analytics from expensive guesswork. Teams that can answer them confidently are teams that will deliver trustworthy insights.
How Long Does Proper Univariate Analysis Take?
For a typical business dataset with 20-50 variables, thorough univariate analysis takes 2-8 hours. That includes generating visualizations, interpreting patterns, documenting findings, and deciding on necessary transformations. It's a fraction of the time required for model building, and it prevents the 2-4 weeks of rework that bad data causes downstream.
The ROI math is simple. If univariate analysis takes 8 hours and prevents even one model rebuild that would have taken 80 hours, you've achieved 10x return on that inspection time. Most data teams report that thorough EDA, with univariate analysis as the foundation, catches issues in 60-80% of projects that would otherwise require significant rework.
Strategic technology decisions that impact data pipeline efficiency
What's the Difference Between Good and Bad Data Distributions?
Not all data shapes are problematic. A symmetric, bell-curved distribution where mean and median are close is generally healthy. Many statistical models assume this shape, and data that naturally fits it requires minimal transformation.
Problems arise with skewed distributions. Right-skewed data (long tail to the right) is common in financial variables like income, purchase amounts, and company valuations. The mean gets pulled up by a few extreme values, making averages misleading. Log transformations often fix this. Left-skewed data is rarer but appears in variables like customer satisfaction scores where most values cluster at the high end.
Bimodal distributions (two distinct peaks) are signals that you're looking at blended data. If customer age shows peaks at 25 and 55, you don't have one customer segment. You have two, and analyzing them as one population will produce insights that apply to neither.
How Do You Handle Outliers Once You Find Them?
Finding outliers is step one. Deciding what to do with them requires business judgment, not just statistical rules. An age value of 150 is clearly a data entry error. An age value of 95 might be legitimate. A purchase amount of $50,000 when your median is $50 could be fraud, a bulk order, or a high-value client.
- Investigate the source: Is this a data entry error, a system glitch, or a genuine edge case?
- Check business context: Does this value make sense given what you know about your operations?
- Decide on handling: Remove if clearly erroneous, cap if you want to reduce influence, or keep if legitimate
- Document the decision: Future analysts need to understand why outliers were handled a specific way
The worst approach is automated removal without investigation. Outliers often contain the most interesting business insights. That $50,000 purchase might reveal a B2B opportunity your team hadn't considered. Remove it blindly, and you miss the signal.
Logicity's Take
At Logicity, we build data pipelines and AI systems for startups and growing companies. We've seen firsthand how skipping univariate analysis creates expensive problems downstream. One client came to us after their predictive model for customer churn delivered wildly inaccurate results. The root cause? Their training data included test accounts with artificial behavior patterns that no one caught during EDA. We rebuilt their data inspection process with automated univariate checks that flag anomalies before they reach the modeling stage. The fix took two weeks. The original failed model had consumed three months. For any company investing in data science, we recommend building univariate analysis into your standard workflow. It's not glamorous work, but it's the foundation that makes advanced analytics reliable. If your team is rushing past inspection to get to modeling faster, they're likely creating technical debt that will cost more to fix later than it would have cost to prevent.
Frequently Asked Questions
Frequently Asked Questions
How much does implementing proper univariate analysis cost?
The cost is primarily time, not tools. Python libraries for generating histograms and box plots are free. A data analyst spending 4-8 hours per project on univariate analysis translates to roughly $200-800 in labor costs, depending on salary levels. Compare this to the $10,000-50,000 cost of rebuilding a model based on flawed data, and the ROI is clear.
Is univariate analysis worth it for small datasets?
Yes, and it's faster with small datasets. A 1,000-row dataset with 20 columns can be fully inspected in 1-2 hours. The smaller your data, the more each individual error impacts your results, making inspection even more critical.
Can univariate analysis be automated?
Visualization generation can be automated. Interpretation requires human judgment. Tools like pandas-profiling can generate reports automatically, but someone still needs to review the distributions and make decisions about outliers and transformations. Plan for automation to reduce time by 50%, not 100%.
How do I know if my data team is doing this correctly?
Ask to see the EDA documentation for any model they've built. It should include histograms or distribution summaries for each variable, notes on skewness and outliers, and documentation of any transformations applied. If this documentation doesn't exist, univariate analysis probably wasn't done thoroughly.
What's the difference between univariate and bivariate analysis?
Univariate examines one variable at a time. Bivariate examines relationships between two variables. You need univariate first because understanding individual variables is prerequisite to understanding their relationships. Skipping univariate analysis means you'll misinterpret bivariate relationships.
How efficient tooling accelerates data engineering workflows
Need Help Implementing This?
Logicity helps growing companies build reliable data pipelines and AI systems. If your analytics projects are delivering inconsistent results, or you're not sure whether your data inspection processes are thorough enough, we can help audit your current workflow and implement improvements. Our team has experience building automated EDA pipelines that catch data quality issues before they impact business decisions. Reach out for a consultation.
Source: DEV Community
Manaal Khan
Tech & Innovation Writer
اقرأ أيضاً

رأي مغاير: كيف يؤثر اختراق الأمن الداخلي الأميركي على شركاتنا الخاصة؟
في ظل اختراق عقود الأمن الداخلي الأميركي مع شركات خاصة، نناقش تأثير هذا الاختراق على مستقبل الأمن السيبراني. نستعرض الإحصاءات الموثوقة ونناقش كيف يمكن للشركات الخاصة أن تتعامل مع هذا التهديد. استمتع بقراءة هذا التحليل العميق

الإنسان في زمن ما بعد الوجود البشري: نحو نظام للتعايش بين الإنسان والروبوت - Centre for Arab Unity Studies
في هذا المقال، سنناقش كيف يمكن للبشر والروبوتات التعايش في نظام متكامل. سنستعرض التحديات والحلول المحتملة التي تضعها شركات مثل جوجل وأمازون. كما سنلقي نظرة على التوقعات المستقبلية وفقًا لتقرير ماكنزي

إطلاق ناسا لمهمة مأهولة إلى القمر: خطوة تاريخية نحو استكشاف الفضاء
تعتبر المهمة الجديدة خطوة هامة نحو استكشاف الفضاء وتطوير التكنولوجيا. سوف تشمل المهمة إرسال رواد فضاء إلى سطح القمر لconducting تجارب علمية. ستسهم هذه المهمة في تطوير فهمنا للفضاء وتحسين التكنولوجيا المستخدمة في استكشاف الفضاء.