Revolutionary AI Breakthrough: Qwen3.5-Omni Writes Code from Voice Commands and Videos

Alibaba's latest AI model, Qwen3.5-Omni, has made a groundbreaking achievement by learning to write code from spoken instructions and video inputs without any prior training. This omnimodal AI model outperforms Google's Gemini 3.1 Pro in audio tasks and supports an impressive 74 languages. With its advanced capabilities, Qwen3.5-Omni is poised to revolutionize the tech industry.
Key Takeaways
- Qwen3.5-Omni can write code from spoken instructions and video inputs
- The AI model outperforms Google's Gemini 3.1 Pro in audio tasks
- It supports 74 languages, a significant jump from its predecessor
In This Article
- Introduction to Qwen3.5-Omni
- Technical Capabilities of Qwen3.5-Omni
- Benchmark Performance of Qwen3.5-Omni
- Language Support and Speech Recognition
- Future Implications of Qwen3.5-Omni
Introduction to Qwen3.5-Omni
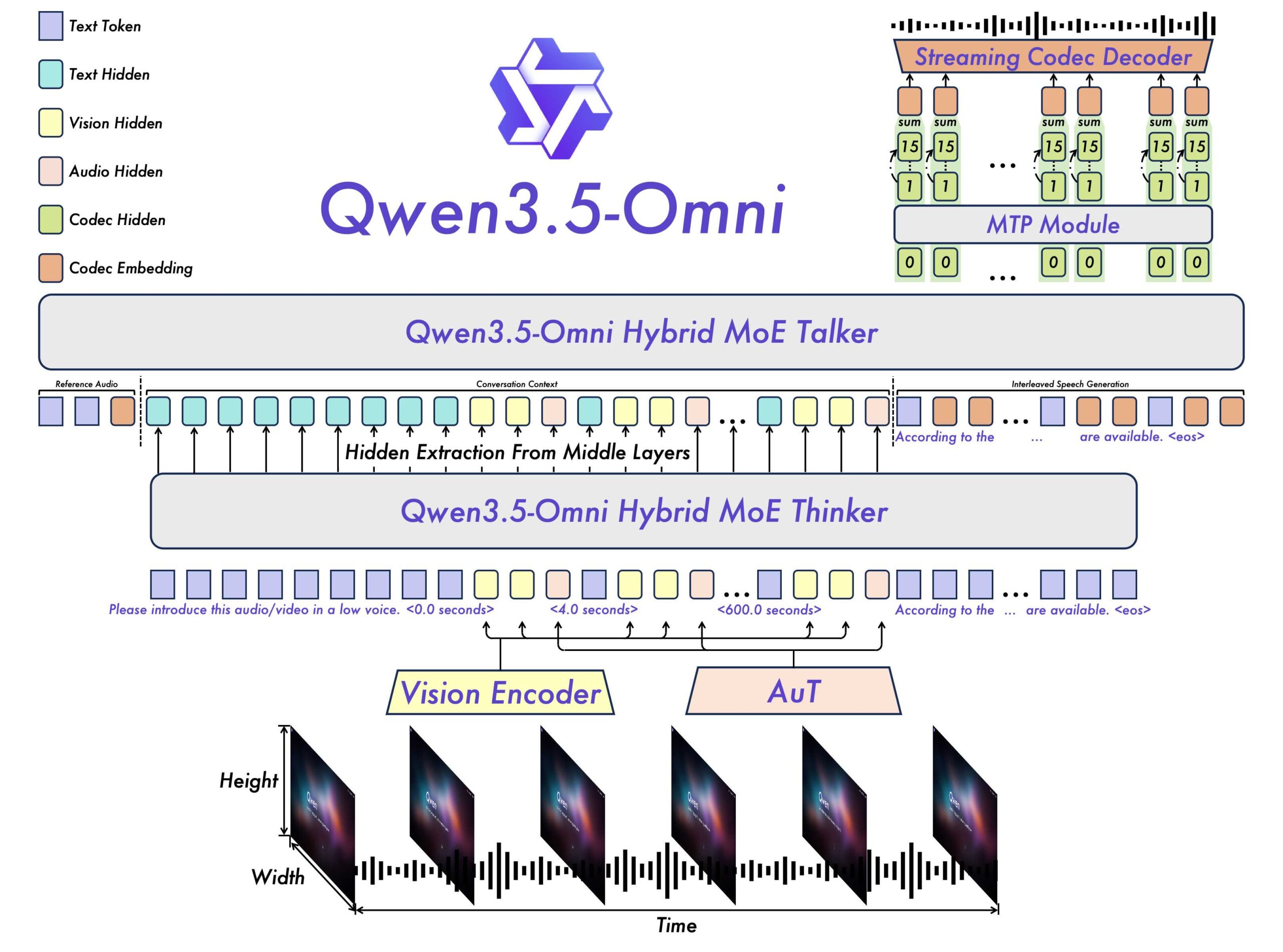
The world of artificial intelligence has witnessed a significant breakthrough with the release of Alibaba's Qwen3.5-Omni, an omnimodal AI model that can process text, images, audio, and video. This cutting-edge technology has the potential to transform the way we interact with machines and has already shown impressive capabilities, including writing code from spoken instructions and video inputs.
- Qwen3.5-Omni is available in three variants: Plus, Flash, and Light
- It can handle contexts up to 256,000 tokens

Technical Capabilities of Qwen3.5-Omni
So, what makes Qwen3.5-Omni so special? For starters, it has been natively pre-trained on over 100 million hours of audiovisual material, allowing it to generate speech output alongside text. This advanced training enables the model to process more than ten hours of audio and over 400 seconds of 720p video at one frame per second.
- Qwen3.5-Omni can process multiple forms of media, including text, images, audio, and video
- It has a context window of 256,000 tokens, a significant improvement from its predecessor

Benchmark Performance of Qwen3.5-Omni
But how does Qwen3.5-Omni stack up against other AI models? According to the Qwen team, the Plus version of the model sets a new state of the art on 215 audio and audiovisual subtasks, outperforming Google's Gemini 3.1 Pro in overall audio comprehension, reasoning, recognition, translation, and dialog.
- Qwen3.5-Omni-Plus scored 82.2 in audio comprehension, beating Gemini 3.1 Pro's score of 81.1
- It achieved a word error rate of 6.24 on the 'seed-hard' test set, outperforming other AI models like GPT-Audio and Minimax
Language Support and Speech Recognition
One of the most impressive features of Qwen3.5-Omni is its language support. The model can recognize speech in 74 languages and 39 Chinese dialects, a massive jump from its predecessor, which only supported 11 languages and 8 Chinese dialects.
- Qwen3.5-Omni's speech recognition capabilities have been significantly improved, with support for 113 languages and dialects
- It can generate voice output in 36 languages and dialects, with 55 voices available
Future Implications of Qwen3.5-Omni
So, what does the future hold for Qwen3.5-Omni? With its advanced capabilities and impressive performance, this AI model has the potential to revolutionize the tech industry, enabling new applications and use cases that were previously unimaginable.
- Qwen3.5-Omni could enable the development of more sophisticated voice assistants and chatbots
- It could also facilitate the creation of more realistic and engaging virtual reality experiences
“No specific quotes available in the source text”
— N/A
Final Thoughts
In conclusion, Qwen3.5-Omni is a groundbreaking AI model that has the potential to transform the tech industry. With its advanced capabilities, including writing code from spoken instructions and video inputs, and its impressive performance on benchmark tests, this model is poised to enable new applications and use cases that were previously unimaginable. As we look to the future, it will be exciting to see how Qwen3.5-Omni continues to evolve and improve, and what new innovations it will enable.
Sources & Credits
Originally reported by Unknown — Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer


