OpenAI's ChatGPT for Clinicians Beats Doctors on Medical Benchmark
Key Takeaways
- GPT-5.4 scored 59.0 on HealthBench Professional versus 43.7 for human doctors with unlimited time and internet access
- The free tool is available to verified physicians, advanced-practice nurses, physician assistants, and pharmacists in the US
- OpenAI built both the benchmark and the product being tested, which raises methodological concerns
OpenAI released ChatGPT for Clinicians this week, a free AI assistant built for everyday medical work. The company claims its GPT-5.4 model outperforms human doctors on clinical tasks by a wide margin, even when those doctors have unlimited time and full internet access.
The tool is now available to verified healthcare professionals in the United States. Physicians, nurses with advanced clinical qualifications, physician assistants, and pharmacists can access it at no cost.
What the Benchmark Shows
OpenAI published HealthBench Professional alongside the launch. The benchmark measures AI performance across three clinical areas: consultations, writing and documentation, and medical research. It uses doctor-written conversations, multi-level physician scoring, and targeted data filtering.
GPT-5.4 running in the ChatGPT for Clinicians workspace scored 59.0 overall. Doctor-written responses came in at 43.7. Every other AI model tested scored below the Clinicians version: the base GPT-5.4 hit 48.1, Anthropic's Claude Opus 4.7 reached 47.0, Google's Gemini 3.1 Pro scored 43.8, and xAI's Grok 4.2 landed at 36.1.
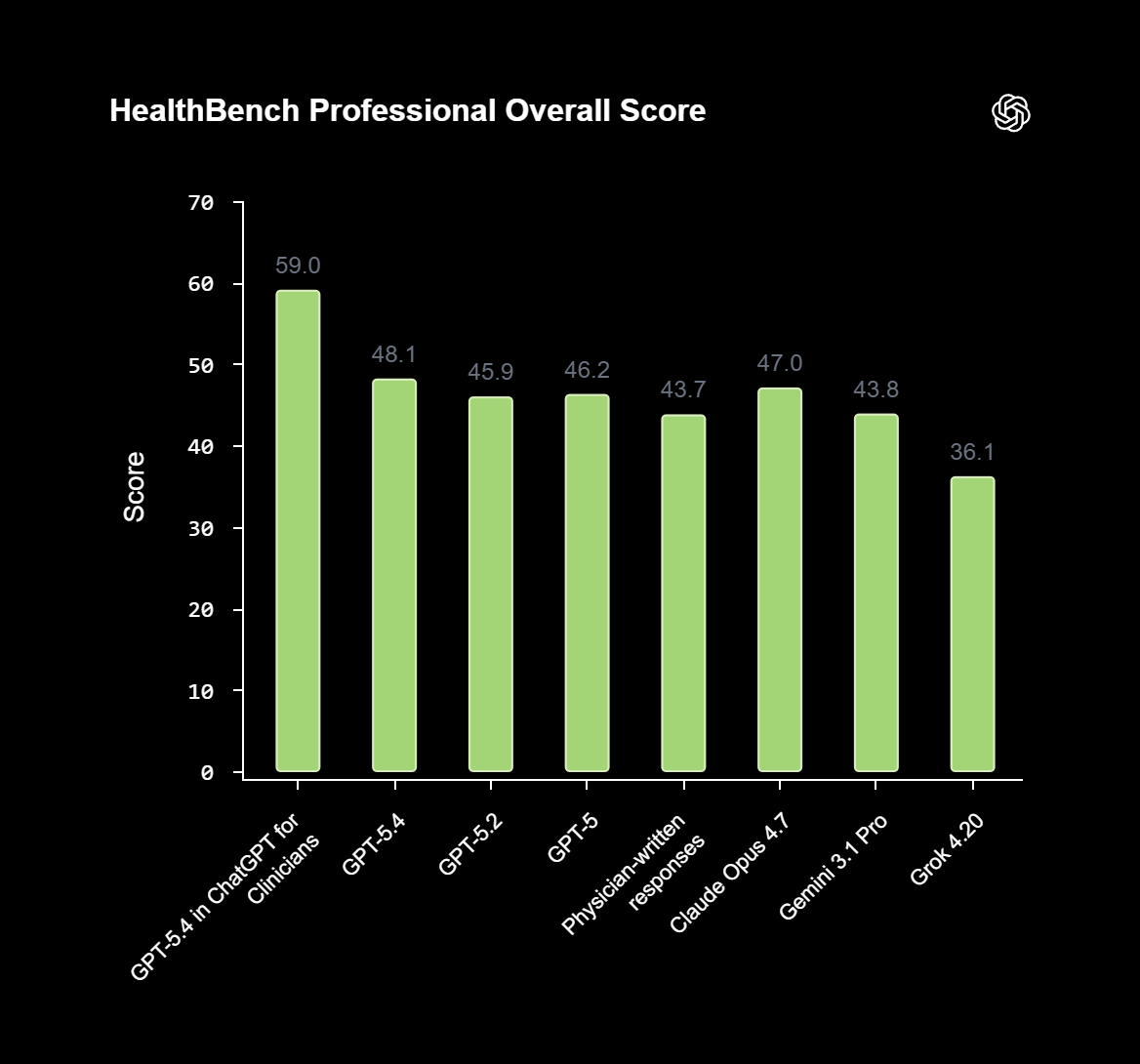
The clinical workspace version scored about 11 points higher than base GPT-5.4. OpenAI did not clarify how much of that gap comes from the clinical setup versus how the benchmark was built.
A Tough Test by Design
OpenAI says the benchmark was designed to be difficult. About a third of the examples come from targeted "red teaming," where doctors actively tried to find weaknesses in the models. The hardest conversations were overrepresented by a factor of 3.5.
The benchmark builds on the earlier HealthBench and includes multi-level physician scoring. OpenAI reports that 99.6 percent of answers were rated reliable by evaluators.
The Methodology Problem
There's an obvious issue with these results. OpenAI built the benchmark and tested its own product. That's not unusual in AI research, but it means the numbers deserve scrutiny.
Benchmark scores also don't translate directly to real clinical practice. A model that excels at structured evaluation tasks might perform differently in the chaos of an emergency room or the nuance of a long-term patient relationship.
What the Tool Actually Does
ChatGPT for Clinicians includes features aimed at daily medical work. The system offers real-time clinical searches across specialist literature, templates for recurring workflows, and automatic recognition of continuing medical education credits.
The tool is currently limited to US healthcare professionals who can verify their credentials. OpenAI hasn't announced plans for international expansion.
| Model | HealthBench Professional Score |
|---|---|
| GPT-5.4 (Clinicians workspace) | 59.0 |
| GPT-5.4 (base) | 48.1 |
| Claude Opus 4.7 | 47.0 |
| Human doctors (unlimited time/internet) | 43.7 |
| Gemini 3.1 Pro | 43.8 |
| Grok 4.2 | 36.1 |
What This Means in Practice
The 15-point gap between AI and human doctors looks striking. But context matters. Doctors don't typically have unlimited time to answer questions. They juggle patients, paperwork, and interruptions. An AI that scores higher under test conditions might still serve best as a second opinion rather than a replacement.
The more interesting number might be the 11-point gap between the Clinicians workspace and base GPT-5.4. That suggests specialized tuning and medical-specific features add real value, which could shape how healthcare organizations think about deploying AI tools.
Logicity's Take
Frequently Asked Questions
Is ChatGPT for Clinicians free?
Yes. OpenAI offers it at no cost to verified physicians, advanced-practice nurses, physician assistants, and pharmacists in the United States.
How did GPT-5.4 compare to human doctors?
GPT-5.4 in the Clinicians workspace scored 59.0 on HealthBench Professional. Human doctors scored 43.7, despite having unlimited time and internet access during the test.
Which AI models were tested on HealthBench Professional?
OpenAI tested GPT-5.4 (base and Clinicians versions), Anthropic's Claude Opus 4.7, Google's Gemini 3.1 Pro, and xAI's Grok 4.2. The Clinicians version of GPT-5.4 scored highest.
Is ChatGPT for Clinicians available outside the US?
Not currently. OpenAI has only announced availability for verified US healthcare professionals and has not shared international expansion plans.
Need Help Implementing This?
Source: The Decoder / Matthias Bastian
Manaal Khan
Tech & Innovation Writer
اقرأ أيضاً

رأي مغاير: كيف يؤثر اختراق الأمن الداخلي الأميركي على شركاتنا الخاصة؟
في ظل اختراق عقود الأمن الداخلي الأميركي مع شركات خاصة، نناقش تأثير هذا الاختراق على مستقبل الأمن السيبراني. نستعرض الإحصاءات الموثوقة ونناقش كيف يمكن للشركات الخاصة أن تتعامل مع هذا التهديد. استمتع بقراءة هذا التحليل العميق

الإنسان في زمن ما بعد الوجود البشري: نحو نظام للتعايش بين الإنسان والروبوت - Centre for Arab Unity Studies
في هذا المقال، سنناقش كيف يمكن للبشر والروبوتات التعايش في نظام متكامل. سنستعرض التحديات والحلول المحتملة التي تضعها شركات مثل جوجل وأمازون. كما سنلقي نظرة على التوقعات المستقبلية وفقًا لتقرير ماكنزي

إطلاق ناسا لمهمة مأهولة إلى القمر: خطوة تاريخية نحو استكشاف الفضاء
تعتبر المهمة الجديدة خطوة هامة نحو استكشاف الفضاء وتطوير التكنولوجيا. سوف تشمل المهمة إرسال رواد فضاء إلى سطح القمر لconducting تجارب علمية. ستسهم هذه المهمة في تطوير فهمنا للفضاء وتحسين التكنولوجيا المستخدمة في استكشاف الفضاء.