Claude Code Discovers AI Scaling Algorithms Humans Missed

Key Takeaways
- Claude Code discovered test-time scaling algorithms that reduce compute costs by 70% compared to standard self-consistency methods
- The entire discovery process cost $39.90 and took 160 minutes, demonstrating cost-effective AI-driven research
- Researchers shifted from designing algorithms themselves to designing environments where AI agents discover algorithms autonomously
What if AI could design its own reasoning strategies better than human engineers? A research team from the University of Maryland, Google, and Meta tested this idea by letting Claude Code loose in a simulated environment. The agent discovered test-time scaling algorithms that outperform established human-designed methods while using 70% less compute.
The project, called AutoTTS, flips the traditional approach to improving large language model performance. Instead of researchers writing rules for when a model should branch into new solution paths or abandon dead ends, they built an environment where an AI agent figures out those rules on its own.
How Test-Time Scaling Works
Test-time scaling lets large language models perform better by spending more compute on each response. A model might run several solution paths in parallel or extend chains of thought before settling on an answer. Think of it as giving the model more time to think through a problem.
Until now, humans wrote the rules that control this process. Engineers decided when a model should start a new solution path, double down on a promising one, or kill a dead end. The AutoTTS paper argues that many known methods are really just special cases within a shared control space defined by two variables: width (how many solution paths run at once) and depth (how far each one goes).
The researchers' core question: why do humans keep plotting paths through this space by hand instead of letting a machine search it?
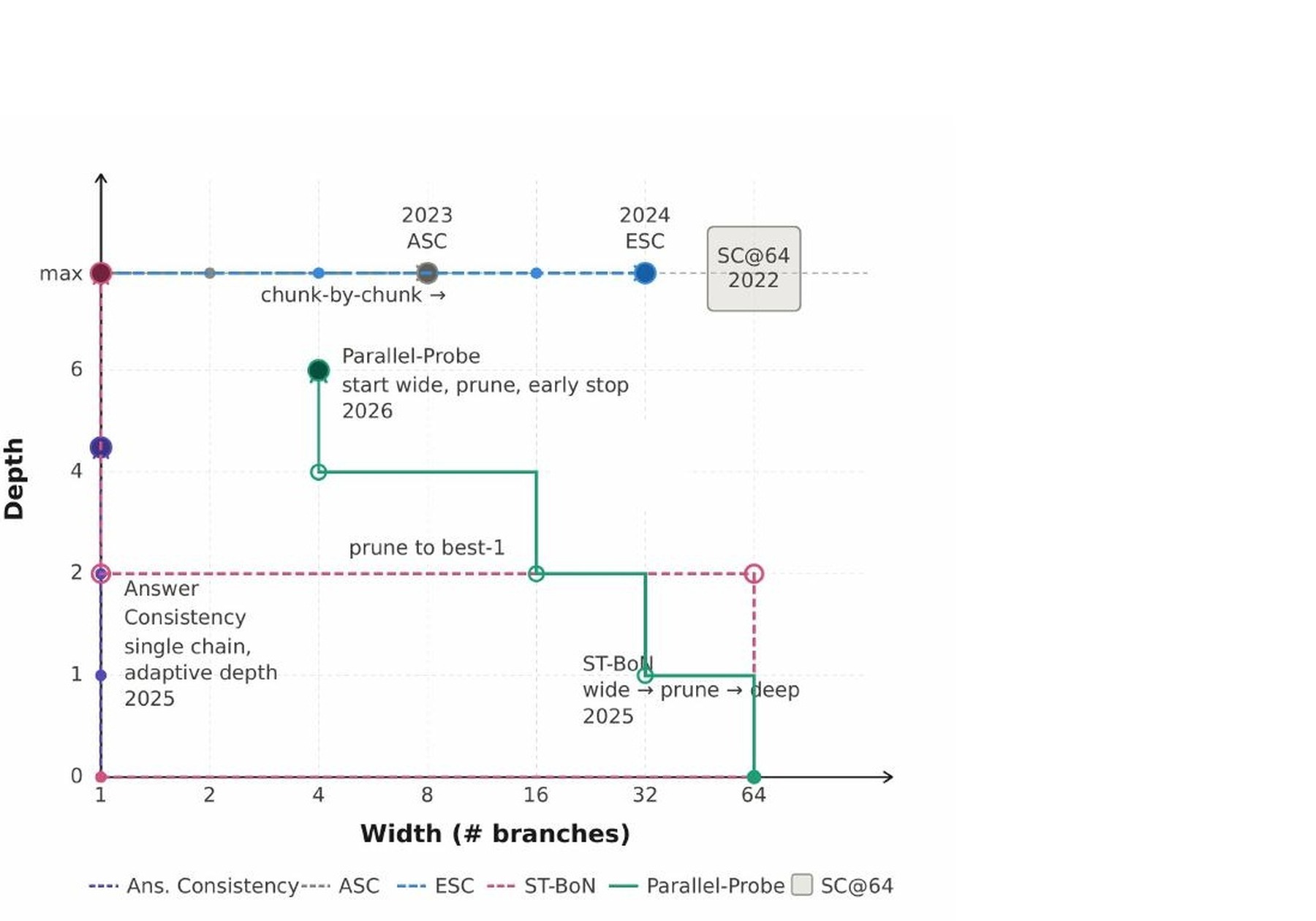
Simulating the Search to Cut Costs
The clever part of AutoTTS is how it keeps costs down. At the core sits an offline environment. For each task, the team pre-generated several solution paths from the language model and stored them. A new control algorithm decides how to spend compute based on data that's already there. This means thousands of variants can run without firing up the actual language model each time.
Claude Code handles the searching. Over several rounds, the agent reviews what came before, spots weaknesses in earlier proposals, and writes a new control algorithm directly in code. To stop the search from getting lost in thousands of tiny knobs, each proposal can only expose one high-level controller to the outside. That controller sets all the other thresholds on its own.
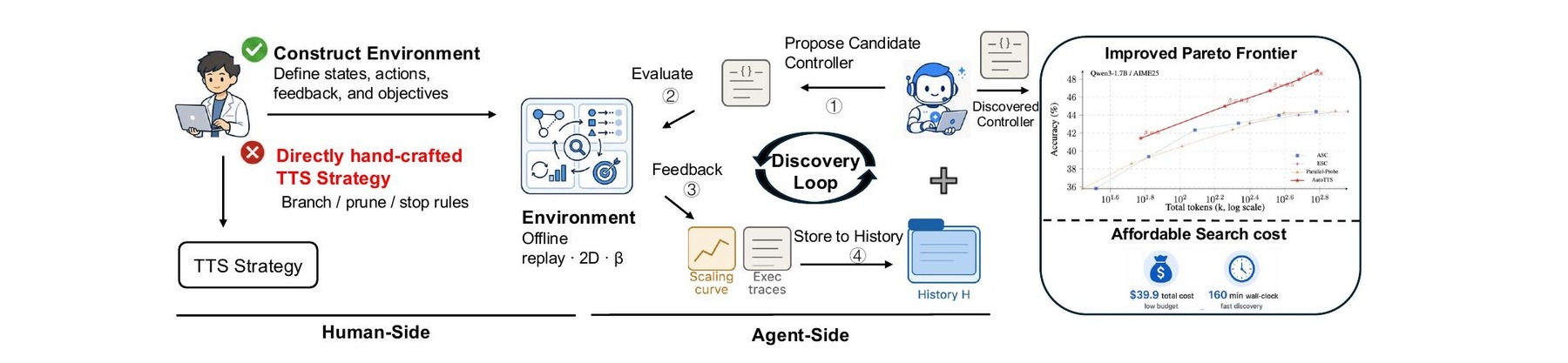
Full logs from each run show the agent where earlier attempts wasted compute. The entire discovery process cost $39.90 in compute resources and took 160 minutes to complete.
“We are moving from a paradigm where humans design the strategies to one where humans design the environment that fosters algorithmic innovation.”
— Dr. Elena Vance, Lead Researcher at UMD AI Lab
Results: Agent Beats Human Engineers
On math benchmarks like AIME and HMMT, the algorithm the agent discovered achieves better accuracy per unit of compute than established methods. The lean setting slashes token usage by about 70% compared to standard self-consistency, which generates 64 answers in parallel and picks the most common one.
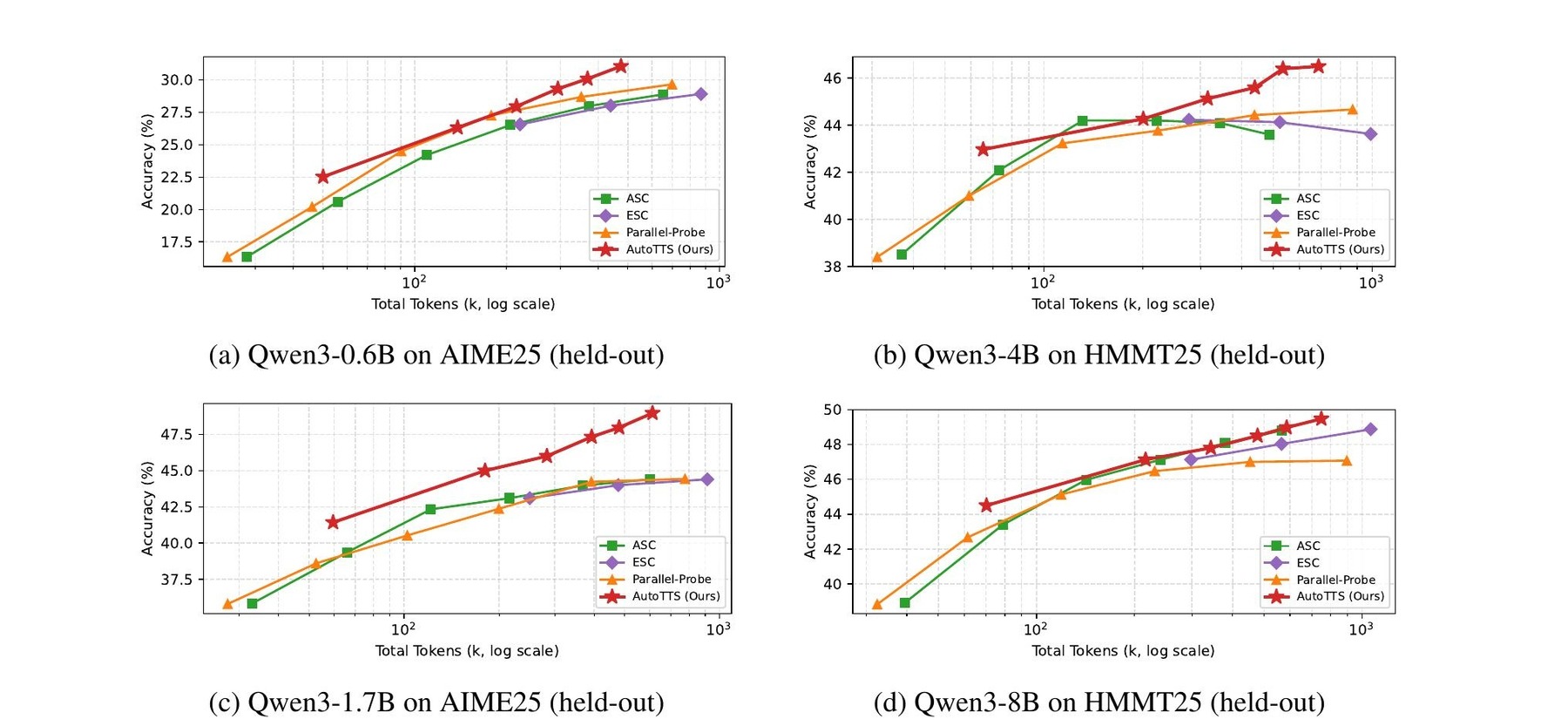
The research team included collaborators from UMD, UVA, Washington University in St. Louis, UNC, Google, and Meta. Their work suggests that the bottleneck to AI progress might be shifting from human architectural ingenuity to our ability to build effective discovery environments.
What This Means for AI Development
The AutoTTS paper points to a broader shift in AI research methodology. Instead of humans manually tuning algorithms, researchers can now focus on designing environments that let AI agents discover solutions. It's a meta-level change: humans define states, actions, and feedback, then step back and let the search happen.
Discussion on Hacker News and AI research communities has focused on this meta nature of the achievement. Some users expressed skepticism about whether the findings generalize beyond math benchmarks. Others see it as the beginning of self-optimizing AI systems that could accelerate their own development.
The 70% compute reduction matters for practical deployment. Inference costs remain a major barrier to using advanced reasoning techniques in production systems. If AI agents can discover more efficient scaling algorithms, that directly translates to lower API bills and broader accessibility.
Logicity's Take
Frequently Asked Questions
What is test-time scaling in AI?
Test-time scaling is a technique that improves large language model performance by allocating more compute during response generation. This can include running multiple solution paths in parallel or extending chains of thought before producing a final answer.
How much did the AutoTTS discovery process cost?
The entire discovery process cost $39.90 in compute resources and took 160 minutes. The system used pre-generated solution paths stored offline, which kept costs low by avoiding repeated calls to the live language model.
How does AutoTTS compare to standard self-consistency methods?
AutoTTS reduces token usage by approximately 70% compared to standard self-consistency, which typically generates 64 answers in parallel and selects the most common one. The agent-discovered algorithm achieves better accuracy per unit of compute on math benchmarks.
Which organizations collaborated on the AutoTTS research?
The research team included collaborators from the University of Maryland, University of Virginia, Washington University in St. Louis, University of North Carolina, Google, and Meta.
Apple's AI infrastructure moves suggest major players are investing heavily in generative AI capabilities
Need Help Implementing This?
Source: The Decoder / Jonathan Kemper
Huma Shazia
Senior AI & Tech Writer
اقرأ أيضاً

رأي مغاير: كيف يؤثر اختراق الأمن الداخلي الأميركي على شركاتنا الخاصة؟
في ظل اختراق عقود الأمن الداخلي الأميركي مع شركات خاصة، نناقش تأثير هذا الاختراق على مستقبل الأمن السيبراني. نستعرض الإحصاءات الموثوقة ونناقش كيف يمكن للشركات الخاصة أن تتعامل مع هذا التهديد. استمتع بقراءة هذا التحليل العميق

الإنسان في زمن ما بعد الوجود البشري: نحو نظام للتعايش بين الإنسان والروبوت - Centre for Arab Unity Studies
في هذا المقال، سنناقش كيف يمكن للبشر والروبوتات التعايش في نظام متكامل. سنستعرض التحديات والحلول المحتملة التي تضعها شركات مثل جوجل وأمازون. كما سنلقي نظرة على التوقعات المستقبلية وفقًا لتقرير ماكنزي

إطلاق ناسا لمهمة مأهولة إلى القمر: خطوة تاريخية نحو استكشاف الفضاء
تعتبر المهمة الجديدة خطوة هامة نحو استكشاف الفضاء وتطوير التكنولوجيا. سوف تشمل المهمة إرسال رواد فضاء إلى سطح القمر لconducting تجارب علمية. ستسهم هذه المهمة في تطوير فهمنا للفضاء وتحسين التكنولوجيا المستخدمة في استكشاف الفضاء.